
文章目录
书接上回:算法系列二:插值查找、斐波那契查找
六. 树表查找
6.1 简介
- 二叉排序树,是最简单的树表查找算法,利用待查找的所有数据,首先生成一棵树,前提要确保树的左分支的值始终小于右分支的值(根节点的值始终大于左子树任意一个节点的值,始终小于右子树任一结点的值),之后再与每个节点的父节点比较大小,进行查找。
- 二叉排序树或者是一棵空树,或者是具有如下性质的一棵树:
① 左子树不空的情况下,所有节点值始终<=根结点的值;
② 右子树不空情况下,所有结点的值始终>=根结点的值;
③ 左、右子树也分别为一颗小的二叉排序树,直至分叉到叶子节点。
6.2 二叉排序树中序遍历
二叉排序树有前、中、后三种遍历方式,我们这里只说中序遍历。上个二叉树的例子:
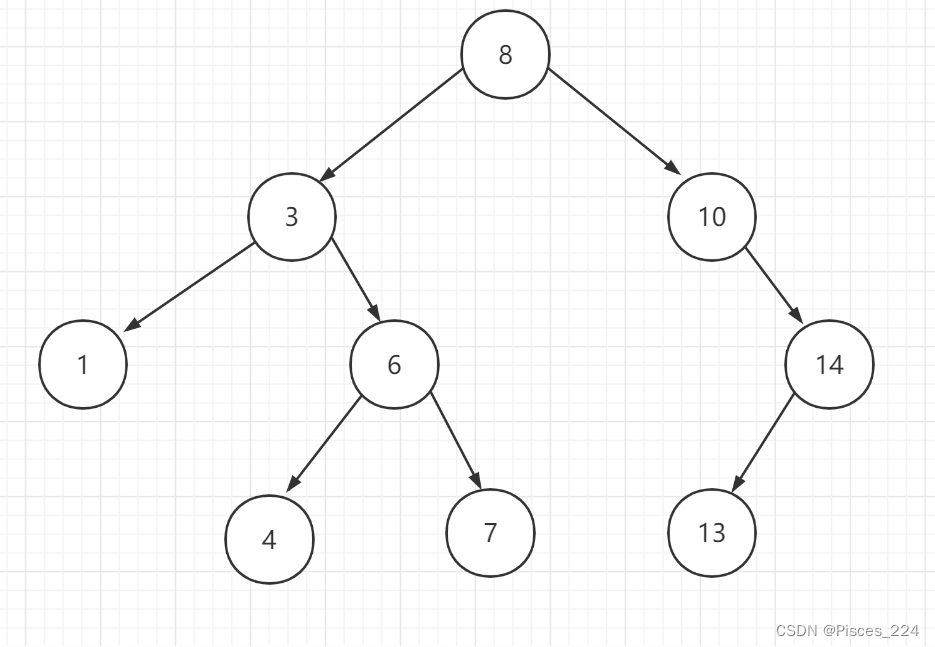
中序遍历的方式为:左中右(左节点,根节点,右节点)。该二叉树中序遍历的结果:
1,3,4,6,7,8,10,13,14
二叉查找树查找步骤:
①先建立一颗二叉排序树;
② 再进行查找。
6.3 算法实现
- 创建树的节点
class BinaryTree{
int value;
BinaryTree left;
BinaryTree right;
public BinaryTree(int value){
this.value = value;
}
}
- 创建二叉排序树:创建二叉排序树是一个递归的过程,需要将序列中的值一个一个添加到二叉树中。方便起见,可以利用序列中第一个元素作为根节点,再持续添加节点。
int[] array = {35,76,6,22,16,49,49,98,46,9,40};
BinaryTree root = new BinaryTree(array[0]);
for(int i = 1; i < array.length; i++){
createBST(root, array[i]);
}
具体创建树的过程,就是一个不断与根节点比较,然后添加到左侧、右侧或不添加(相等时)的过程。
public static void createBST(BinaryTree root, int element){
BinaryTree newNode = new BinaryTree(element);
if(element > root.value){
if(root.right == null)
root.right = newNode;
else
createBST(root.right, element);
}else if(element < root.value){
if(root.left == null)
root.left = newNode;
else
createBST(root.left, element);
}else{
System.out.println("该节点" + element + "已存在");
return;
}
}
查找元素是否在树中的过程,就是一个二分查找的过程,不过查找的对象从左右子序列转换成了左右子树而已。
public static void searchBST(BinaryTree root, int target, BinaryTree p){
if(root == null){
System.out.println("查找"+target+"失败");
}else if(root.value == target){
System.out.println("查找"+target+"成功");
}else if(root.value >= target){
searchBST(root.left, target, root);
}else{
searchBST(root.right, target, root);
}
}
6.4 完整代码
public class BinarySortTree {
public static void main(String[] args) {
int[] array = {35,76,6,22,16,49,49,98,46,9,40};
BinaryTree root = new BinaryTree(array[0]);
for(int i = 1; i < array.length; i++){
createBST(root, array[i]);
}
System.out.println("中序遍历结果:");
midOrderPrint(root);
System.out.println();
searchBST(root, 22, null);
searchBST(root, 100, null);
}
/*创建二叉排序树*/
public static void createBST(BinaryTree root, int element){
BinaryTree newNode = new BinaryTree(element);
if(element > root.value){
if(root.right == null)
root.right = newNode;
else
createBST(root.right, element);
}else if(element < root.value){
if(root.left == null)
root.left = newNode;
else
createBST(root.left, element);
}else{
System.out.println("该节点" + element + "已存在");
return;
}
}
/*二叉树中查找元素*/
public static void searchBST(BinaryTree root, int target, BinaryTree p){
if(root == null){
System.out.println("查找"+target+"失败");
}else if(root.value == target){
System.out.println("查找"+target+"成功");
}else if(root.value >= target){
searchBST(root.left, target, root);
}else{
searchBST(root.right, target, root);
}
}
/*二叉树的中序遍历*/
public static void midOrderPrint(BinaryTree rt){
if(rt != null){
midOrderPrint(rt.left);
System.out.print(rt.value + " ");
midOrderPrint(rt.right);
}
}
}
输出结果:
该节点49已存在
中序遍历结果:
6 9 16 22 35 40 46 49 76 98
查找22成功
查找100失败
七. 哈希查找
7.1 简介(哈希函数、哈希表)
哈希查找涉及到的两个东西,哈希表和哈希函数。
- 哈希表
哈希表,是根据关键值而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表(哈希表)
- 哈希函数
哈希函数指将哈希表中元素的关键键值映射为元素存储位置的函数。
我们可以知道,哈希查找比较的不是待查找数值,而是一个关键码。
7.2 构造哈希表
既然如此,我们就需要先构造一个哈希表。那么常见的几种构造方法有:
- 直接定址法
哈希地址:f(key) = a*key+b (a、b为常数)。
这种方法的优点是:简单、均匀、不会产生冲突。但是需要事先知道 key 的分布情况,适合查找表较小并且连续的情况。
- 数字分析法
假设关键字是R进制数(如十进制)。并且哈希表中可能出现的关键字都是事先知道的,则可选取关键字的若干数位组成哈希地址。选取的原则是使得到的哈希地址尽量避免冲突,即所选数位上的数字尽可能是随机的。
举个例子:比如11位手机号码“136xxxx5889”,其中前三位是接入号,一般对应不同运营公司的子品牌,中间四位表示归属地,最后四位才是用户号,此时就可以用后4位来作为哈希地址。
- 平方取中法
取key平方后的中间几位为哈希地址。通常在选定哈希函数时不一定能知道关键字的全部情况,仅取其中的几位为地址不一定合适。而一个数平方后的中间几位数和数的每一位都相关, 由此得到的哈希地址随机性更大。如key是1234,那么它的平方就是1522756,再抽取中间的3位就是227作为 f(key) 。
- 折叠法:
折叠法是将 key 从左到右分割成位数相等的几个部分(最后一部分位数不够可以短些),然后将这几部分叠加求和,并按哈希表的表长,取后几位作为 f(key) 。
比如key是9876543210,哈希表的表长为3位,我们将 key 分为4组,987 | 654 | 321 | 0 ,然后将它们叠加求和 987+654+321+0=1962,再取后3位即得到哈希位置是:962 。
- 除留余数法
取关键字被某个不大于哈希表表长 m 的数 p 除后所得的余数为哈希地址。即 f(key) = key % p (p ≤ m)。这种方法是最常用的哈希函数构造方法。
- 随机数法
哈希地址:random(key) ,这里random是随机函数,当 key 的长度不等时,采用这种方法比较合适。
7.3 如何解决冲突
我们在使用以上方法计算key对应的哈希地址时,偶尔会遇到两个key不相等,但是计算出来的哈希地址却相同的情况,该情况就被称为“冲突”。在构造哈希表时,有常用几种方式解决冲突:
- 开放定址法
该方法指的是两个key在计算出相同的哈希地址时,后者继续在哈希表中向后寻找空位置,存放改key的方法。举个例子:假如原始的key中有8、15两个元素,哈希表中的长度为7,当使用key % length求余时,两个key会计算出相同的哈希位置。假设哈希表中的1位置已经存放了8,那么15就要从1位置往后寻找空位,假如2位置是空的,就可以把15存放到2位置;假如2位置不空,就要往3位置寻找,以此类推。
三种方式:
a. 线性探测再散列:
顺序查看下一个单元,直到找出一个空单元填入或查遍全表。
b. 二次(平方)探测再散列:
在表的左右进行跳跃式探测,直到找出一个空单元或查遍全表.
c. 伪随机探测再散列:
- 建立一个伪随机数发生器,并给一个随机数作为起点
- di=伪随机数序列。具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),并给定一个随机数做起点。
例如,已知哈希表长度m=11,哈希函数为:H(key)= key % 11,则H(47)=3,H(26)=4,H(60)=5,假设下一个关键字为69,则H(69)=3,与47冲突。
如果用线性探测再散列处理冲突,下一个哈希地址为H1=(3 + 1)% 11 = 4,仍然冲突,再找下一个哈希地址为H2=(3 + 2)% 11 = 5,还是冲突,继续找下一个哈希地址为H3=(3 + 3)% 11 = 6,此时不再冲突,将69填入5号单元。
如果用二次探测再散列处理冲突,下一个哈希地址为H1=(3 + 12)% 11 = 4,仍然冲突,再找下一个哈希地址为H2=(3 – 12)% 11 = 2,此时不再冲突,将69填入2号单元。
如果用伪随机探测再散列处理冲突,且伪随机数序列为:2,5,9,………,则下一个哈希地址为H1=(3 + 2)% 11 = 5,仍然冲突,再找下一个哈希地址为H2=(3 + 5)% 11 = 8,此时不再冲突,将69填入8号单元
- 拉链法(链地址法)
简单来说,就是对于相同的哈希值,使用链表进行连接(如HashMap)
即创建一个List,存储相同位置上不同值的key
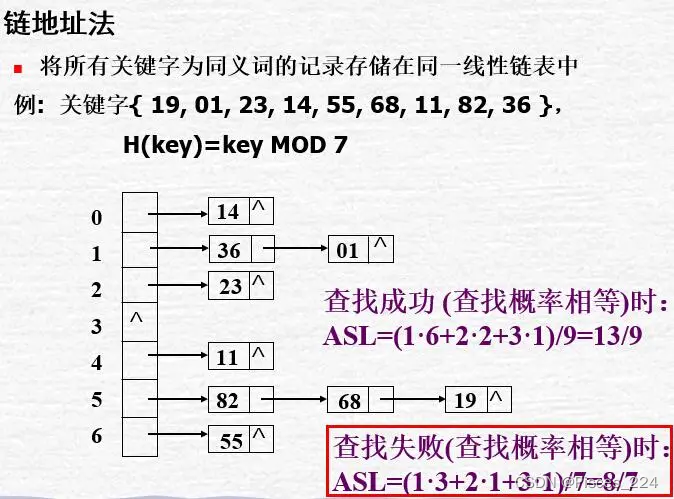
-
优点:
①处理冲突简单,无堆积现象。即非同义词决不会发生冲突,因此平均查找长度较短;
②适合总数经常变化的情况。(因为拉链法中各链表上的结点空间是动态申请的)
③占空间小。装填因子可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计
④删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。 -
缺点:
①查询时效率较低。(存储是动态的,查询时跳转需要更多的时间)
②在key-value可以预知,以及没有后续增改操作时候,开放定址法性能优于链地址法。
③不容易序列化
- 再哈希法(*)
提供多个哈希函数,如果第一个哈希函数计算出来的key的哈希值冲突了,则使用第二个哈希函数计算key的哈希值。
优缺点:不易产生聚集;增加计算时间。
- 建立公共溢出区(*)
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表
7.4 算法实现
- 先构建哈希表。而要构建哈希表,就要先有计算地址的方法:
/*用除留余数法计算要插入元素的地址*/
public static int hash(int[] hashTable, int data) {
return data % hashTable.length;
}
- 有了计算哈希地址的方法后,剩下的就是将原始的元素插入到哈希表中,也就是先利用key计算一个地址,如果这个地址以及有元素了,就继续向后寻找。此处可以循环计算地址:
/*将元素插入到哈希表中*/
public static void insertHashTable(int[] hashTable, int target) {
int hashAddress = hash(hashTable, target);
/*如果不为0,则说明发生冲突*/
while (hashTable[hashAddress] != 0) {
/*利用开放定址法解决冲突,即向后寻找新地址*/
hashAddress = (++hashAddress) % hashTable.length;
}
/*将元素插入到哈希表中*/
hashTable[hashAddress] = target;
}
- 哈希表构建后,就是在哈希表中查找元素了。在查找元素时,容易想到的情况是:在直接计算出的哈希地址及其后续位置查找元素。特殊的是,上一步中,有循环计算地址的操作,所以此处计算到原始地址时,也代表查找失败。
public static int searchHashTable(int[] hashTable, int target) {
int hashAddress = hash(hashTable, target);
while (hashTable[hashAddress] != target) {
/*寻找原始地址后面的位置*/
hashAddress = (++hashAddress) % hashTable.length;
/*查找到开放单元(未存放元素的位置)或 循环回到原点,表示查找失败*/
if (hashTable[hashAddress] == 0 || hashAddress == hash(hashTable, target)) {
return -1;
}
}
return hashAddress;
}
7.5 完整代码示例
public class HashSearch {
/*待查找序列*/
static int[] array = {13, 29, 27, 28, 26, 30, 38};
/* 初始化哈希表长度,此处哈希表容量设置的和array长度一样。
* 其实正常情况下,哈希表长度应该要长于array长度,因为使用
* 开放地址法时,可能会多使用一些空位置
*/
static int hashLength = 7;
static int[] hashTable = new int[hashLength];
public static void main(String[] args) {
/*将元素插入到哈希表中*/
for (int i = 0; i < array.length; i++) {
insertHashTable(hashTable, array[i]);
}
System.out.println("哈希表中的数据:");
printHashTable(hashTable);
int data = 28;
System.out.println("\n要查找的数据"+data);
int result = searchHashTable(hashTable, data);
if (result == -1) {
System.out.println("对不起,没有找到!");
} else {
System.out.println("在哈希表中的位置是:" + result);
}
}
/*将元素插入到哈希表中*/
public static void insertHashTable(int[] hashTable, int target) {
int hashAddress = hash(hashTable, target);
/*如果不为0,则说明发生冲突*/
while (hashTable[hashAddress] != 0) {
/*利用开放定址法解决冲突,即向后寻找新地址*/
hashAddress = (++hashAddress) % hashTable.length;
}
/*将元素插入到哈希表中*/
hashTable[hashAddress] = target;
}
public static int searchHashTable(int[] hashTable, int target) {
int hashAddress = hash(hashTable, target);
while (hashTable[hashAddress] != target) {
/*寻找原始地址后面的位置*/
hashAddress = (++hashAddress) % hashTable.length;
/*查找到开放单元(未存放元素的位置)或 循环回到原点,表示查找失败*/
if (hashTable[hashAddress] == 0 || hashAddress == hash(hashTable, target)) {
return -1;
}
}
return hashAddress;
}
/*用除留余数法计算要插入元素的地址*/
public static int hash(int[] hashTable, int data) {
return data % hashTable.length;
}
public static void printHashTable(int[] hashTable) {
for(int i=0;i<hashTable.length;i++)
System.out.print(hashTable[i]+" ");
}
}
结果:
哈希表中的数据:
27 29 28 30 38 26 13
要查找的数据28
在哈希表中的位置是:2
活动地址:CSDN21天学习挑战赛
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/157244.html

