
论文地址:基于时移建模的入耳式耳机透听系统
引用格式:
摘要
透传(hear-through,HT)技术是通过增强耳机佩戴者对环境声音的感知来主动补偿被动隔离的。耳机中的材料会减少声音 500Hz以上的高频成分。HT算法利用麦克风和用户耳朵之间的相对传递函数(RTF)产生人造声音,从而弥补环境声音的损失。通常,HT的性能取决于环境声音的到达方向( direction of arrival,DOA)。本文提出了一种识别RTF的时移方案和一种精确计算补偿声音的主动均衡算法。还研制了一种整形滤波器,以防止低频人工声音的干扰。最后,将该算法集成到入耳式耳机中,并与一款商用产品的HT性能进行了比较,验证了该算法的有效性。
关键词:自适应系统,到达方向,穿透,入耳式耳机,被动隔离,相对传递函数
1 引言
随着近年来音频技术的进步,智能可听设备市场发展迅速。几家公司已经推出了智能耳机,为消费者提供了比传统耳机更好的听力体验[6]。此外,智能耳机市场占所有耳机市场的份额继续增加,到2026年,全球高端耳机市场预计将超过220亿美元。通常,智能耳机支持主动降噪(ANC)和透听(HT)[7]的切换功能。ANC有助于消除不必要的环境噪声,在过去十年中得到了很好的发展。HT补偿了耳机佩戴者环境声音的损失,有利于交流和增强听力[12][18]。由于耳机中的HT具有与助听器[7]类似的功能,近年来受到了广泛关注[19]。
包括入耳式耳机在内的智能耳机因其轻便便携而最受欢迎[6],[20]。有几家公司已经推出了具有ANC和HT功能的入耳式耳机;但是,为了满足消费者的需求,还必须提高HT的性能。为了实现HT,连接在耳机外部的外部麦克风接收环境声,然后由扬声器创建并播放伪环境声,以补偿耳机造成的声学隔离,从而提供声学透明度[23]。戴耳机的人听到的声音500Hz以上的声音被隔绝。许多研究学者提出了改进的HT函数。Rämö和Välimäki提出了一种基于全通原理的均衡方法,用于耳机[25]的HT系统中,并分析了梳状效应[26]。Ranjan和Gan分析了耳机造成的声学隔离,并提出了自适应滤波技术,用于在开式耳机中再现自然听力[14]。Gan等人还开发了虚拟现实(VR)和增强现实(AR)应用程序,为耳机的佩戴者创造了自然和增强的听力体验。讨论了环境声的变化到达方向(DOA),以设计HT滤波器为目标[17]。Gupta等人提出了参数HT均衡方案来估计声音的DOA,然后从预先计算的数据库中选择相应的HT滤波器来提高多源场景的性能[24]。Patel等人提出了定向HT耳机,该耳机在佩戴者面向的方向上集成了用于HT的麦克风阵列波束形成[29]。Zhuang和Liu表明,在频域中,HT滤波器设计问题可以用类似于ANC滤波器设计的方式来表述[30]。在此基础上,提出了一种约束HT滤波器的设计方法。此外,Gupta et al.[31]基于耳廓线索评估了个性化和非个性化HT均衡滤波器。Jin等人还通过估计鼓膜处的声压,设计了一种个性化的HT均衡滤波器[32]。大多数HT研究都集中在补偿由头戴耳机引起的声学隔离,以提高声学透明度[14],[17],[24],[29], [33]。对入耳式耳机的评估很少。主要原因应该是入耳式耳机太小,难以控制;同时,小型扬声器在低频[34]时很难有良好的性能。因此,HT滤波器的计算必须有效地防止人工声音的回响。大多数入耳式耳机都有定制的耳塞,可以进一步屏蔽环境声音。耳塞有助于消除噪音,因为它们将佩戴者与大频率范围内的环境声音隔离开来,但使HT难以实现。
本工作开发了一种用于入耳式耳机的HT技术。要实现透传的听觉体验,必须补偿入耳式耳机的被动隔离效果。最直观的方法是在外部麦克风(带入耳式耳机)和鼓膜麦克风(内部麦克风,不带入耳式耳机)之间识别RTF,如图1所示。图1展示了用于集成外部麦克风与入耳式耳机的实验设置。实验中使用了一个假头的耳模拟器。内部麦克风是假头的耳朵。在HT应用中,由于外部和内部麦克风信号产生的条件不同,无法同时接收。因此,在本工作中,提出了时移方法来识别离线的RTF,以实现HT。由于耳塞在较宽的频率范围内将佩戴者与外部声音隔离,因此提出了一种shaping filter方法,在感兴趣的频率上产生补偿声音,从而减少DOA的影响并提高HT性能。
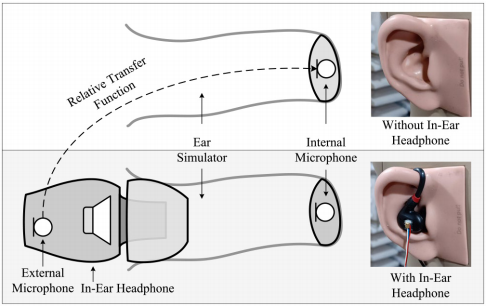

图1所示 一种与外部麦克风集成的入耳式耳机的设置
本文的其余部分组织如下。第二节讨论了基于所提出的时移建模方法和入耳式耳机主动透传均衡(AHE)算法的HT系统。第三节评价了所提出的算法,并讨论了所设计的shaping filter的优点。与商业化的入耳式耳机进行了比较。第四节得出结论。
2 透传 (Hear-through,HT) 系统
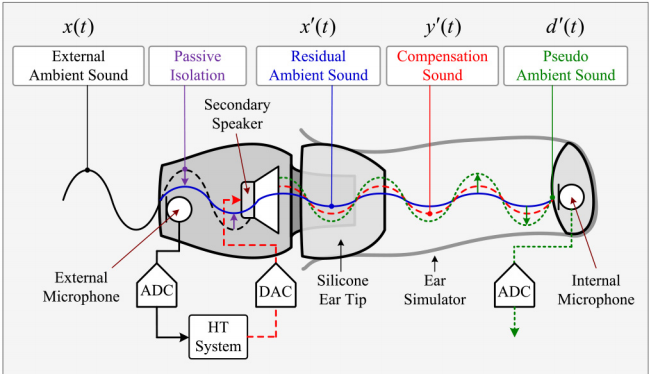
图2所示:一种采用HT方案的入耳式耳机的系统结构
HT方案被广泛应用于现代耳机中。HT的目的是补偿耳机造成的被动隔离。图2示意图描述了入耳式耳机中的HT,其中假头充当耳机用户。外接麦克风连接到入耳式耳机的外部,以接收外部环境声音$x(t)$。假头耳朵中残留的环境声音记为$x'(t)$。HT系统产生的补偿声$y′(t)$,用于补偿耳机被动隔离造成的环境声损失。因此,内部麦克风(假头耳)的伪环境声为
$$d'(t)=x'(t)+y'(t)$$
其中$t$表示时间。此外,数字滤波器可以适应不断变化的环境,因此,模数转换(ADC)和数模转换(DAC)单元被用于拟议的HT系统。

图3 带有假头耳道的入耳式耳机示意图
这项工作开发了一种技术,可以完美地恢复入耳式耳机佩戴者耳膜上的环境声音。图3给出了本文提出的HT系统的概念。主扬声器用于产生激励信号。次要路径表示从次要扬声器到内部麦克风的传递函数,一般包括DAC、重构滤波器(reconstruction filter)、功率放大器( power amplifier)、从次要扬声器到内部麦克风的声学路径、前置放大器(pre-amplifier)、抗混叠滤波器(anti-aliasing filter)、ADC。不考虑从扬声器到外部麦克风的声学反馈路径,因为入耳式耳机的硅胶耳塞会衰减反馈声音。其中,$n$表示数字时间样本。假设外部麦克风处的信号为$x(n)$,所提方案的目的是推导补偿信号$y(n)$,使伪环境信号$d'(n)$(耳机佩戴者接收到的)与信号$d(n)$(在没有耳机的情况下将接收到的)完全匹配。
为了实现这个目标,必须导出目标路径$T(z)$。目标路径$T(z)$是指外部麦克风(戴耳机)和假头的耳麦(不戴耳机)之间的传递函数。由于外部信号$x(n)$和环境信号$d(n)$存在于不同的场景中,$T(z)$不能用传统的自适应方法识别。因此,采用时移建模方法来识别外部和内部麦克风之间的RTF,从而准确估计传递函数$T(z)$。
A. 时移(Time-Shift)离线建模
由于外部和内部麦克风信号不能同时接收。为此,提出了基于时移的方法在离线状态下识别RTF以实现HT。根据外部麦克风和内部麦克风的相干函数计算时移,并利用LMS算法估计目标路径,完成了两个阶段的工作。首先主扬声器播放白噪声作为激励信号,在假头耳朵处接收到信号$d(n)$。然后,信号$x(n)$被如图3所示的外部麦克风接收。目标路径$T(z)$的RTF是$d(n)$和$x(n)$之间的期望传递函数。
$$公式2:T(z) \triangleq Z\left[\frac{d(n)}{x(n)}\right]$$
其中$Z[·]$表示Z变换。然而,信号$d(n)$和$x(n)$不能同时测量,两者之间的相干性几乎为零,因此没有自适应方法可以直接识别目标路径$T(z)$。因此,在本研究中采用时移建模来估计目标路径$T(z)$。由于高效的系统识别需要外部和内部麦克风之间的高相干性,为了提高相干性,首先计算信号$d(n)$和$x(n)$之间的时移常数,如图4(a)所示。作为延迟的时移$\Delta _1$应用于$d(n)$以满足因果关系。
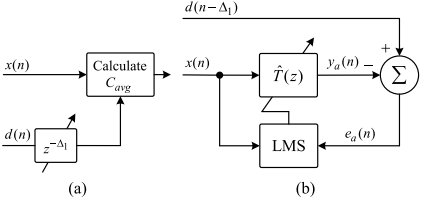
图4 时移建模框图,(a)计算时移,(b)估计目标路径T(z)
定义外部环境信号$x(n)$与真实环境信号$d(n)$之间的相干函数[35]为
$$公式3:\gamma_{d x}(\omega) \equiv \frac{S_{d x}(\omega)}{\sqrt{S_{d d}(\omega) S_{x x}(\omega)}}$$
其中$S_{dd}(w)$和$S_{xx}(w)$分别为环境信号$d(n)$和外部信号$x(n)$的自功率谱;$S_{dx}(w)$为复交叉功率谱,$\omega $为频率。相干性$C_{dx}(w)$是在所有频率上满足以下约束的归一化交叉谱密度函数
$$公式4:0 \leq C_{d x}(\omega) \equiv\left|\gamma_{d x}(\omega)\right|^2=\frac{\left|S_{d x}(\omega)\right|^2}{S_{d d}(\omega) S_{x x}(\omega)} \leq 1$$
为了确定最优时移,使用了平均平方相干$C_{avg}$的性能指标;它是由
$$公式5:C_{a v g}=\frac{1}{N} \sum_{k=1}^N C_{d x}\left(\omega_k\right)$$
其中$w_k$是感兴趣的频率。将最优移码参数$\bigtriangleup _1$设置为使$C_{avg}$值最大化。一旦获得了最高的平均相干性,就可以利用$d(n-\bigtriangleup _1)$自适应识别目标路径$T(z)$,如图4(b)所示。
因此,误差信号表示为
$$公式6:e_a(n)=d\left(n-\Delta_1\right)-y_a(n)$$
$y_a(n)=\hat{t}^T(n)x(n)$,$T$表示转置,$x(n)\equiv [x(n)x(n-1)…x(n-L+1)]^T$,$\hat{t}(n)\equiv [\hat{t}_0\hat{t}_1…\hat{t}_{L-1}]^T$,$\hat{t}_l(n)(l=0,…,L-1)$为滤波器长度为$L$的目标路径模型$T(z)$的第$l$个系数,采用最小均方(LMS)算法将目标路径模型$T(z)$的系数更新为:
$$公式7:\hat{t}(n+1)=\hat{t}(n)+\mu x(n)e_a(n)$$
其中$\mu$为步长。在步长足够小的情况下,LMS算法可以调整权重向量$\hat{t}(n)$,使误差信号$e_a(n)$最小化。
B. 主动透传均衡算法
为了得到所需的均衡滤波器,假设剩余的环境信号$x(n)$为零。基本上,剩余的环境信号$x(n)$只包含500Hz以下的环境声音$x(n)$的低频成分,超出了感兴趣的频率范围。因此,在设计阶段可以忽略剩余的环境信号$x(n)$。最优均衡滤波器为
$$公式8:W^{\circ}(z)=\frac{T(z)}{S(z)}$$
如图3所示。此外,为了实现入耳式耳机的HT,必须补偿由次要路径引起的固有延迟。因此,我们加入了$\bigtriangleup_2$个延迟样本来克服消除因果约束[36]。因此,推导出实际均衡滤波器[23]为
$$公式9:W(z)=\frac{\hat{T}(z) z^{-\Delta_2}}{\hat{S}(z)}$$
其中$\hat{S}(z)$是次路径$S(z)$的估计模型。从$\hat{S}(z)$的脉冲响应的第一个零可以计算出延迟$\Delta _2$。耳机的被动隔离性能取决于环境声音的DOA,如图5所示。在图7中,在离假头右耳30厘米的地方放置一个扬声器,播放粉红色的噪音(20hz至20khz)作为环境声;将入耳式耳机放在假人的右耳中,测量噪音。图5中的灰线显示了当声音入射角从0到$315^{o} $(步长为$45_{o}$)时假头右耳处振幅的减小;蓝线表示平均振幅减小,红线表示耳朵打开。
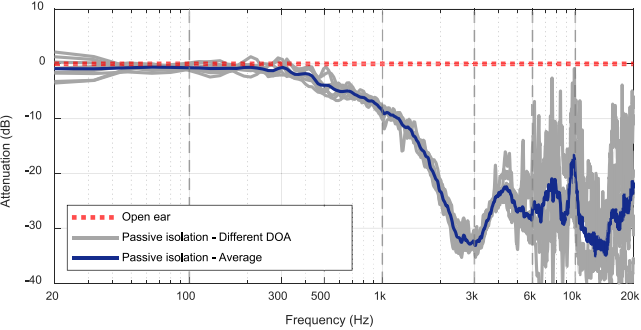
图5所示 入耳式耳机的被动隔离效果
在这种情况下,低于4kHz的环境声音各组成部分的幅度衰减几乎相等。入耳式耳机的硅胶耳尖在较高频率下衰减更大,因此残留的环境信号$x(n)$包含周围声音的低频成分。如图5所示,衰减发生在500 Hz以上。因此,带通整形滤波器$C(z)$的截止频率$f_L$ = 500 Hz和$f_H$ = 4 kHz,使HT系统只补偿感兴趣的频率范围。因此,所提出的包含shaping filter的均衡滤波器可以导出为
$$公式10:W_c(z)=\frac{\hat{T}(z) C(z) z^{-\Delta_2}}{\hat{S}(z)}$$
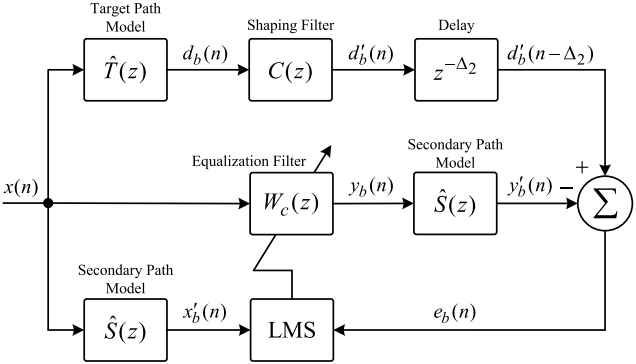
图6所示 AHE算法框图
图6给出了推导均衡滤波器$W_c(z)$的AHE算法框图。在AHE算法中,误差信号表示为
$$公式11:e_b(n)=d_b^{\prime}\left(n-\Delta_2\right)-y_b^{\prime}(n)$$
其中$d’b(n)$为期望目标信号;$y’_b(n)$为补偿信号,$\Delta _2$为延时采样数。均衡滤波器$W_c(z)$的输出信号$y_b(n)$表示为
$$公式12:y_b(n)=\hat{w}^Tx(n)$$
其中$w(n)=[w_0(n)w_1(n)…w_{L-1}(n)]^T$为权向量;$w_l(n)(l=0,…,L-1)$为滤波器长度为$L$的$W_c(z)$的第$l$个系数,$x(n)=[x(n)x(n-1)…,x(n-L+1)]^T$为外部麦克风接收到的信号。在filtered-X LMS (FXLMS)算法的基础上,对均衡滤波器$W_c(z)$进行了更新
$$公式13:\mathbf{w}(n+1)=\mathbf{w}(n)+\mu[\hat{\mathbf{s}}(n) * \mathbf{x}(n)] e_b(n)$$
式中$*$为线性卷积,$\hat{s}(n)$为次路径模型$\hat{S}(z)$的脉冲响应向量。$w(n)$以足够小的步长收敛到最优值。
3 分析与实验
A. 实验步骤
实验在符合ISO 3745(2003)和ASTM E336(2009)标准的消声室中进行。在离假头右耳30厘米的地方放置扬声器,发出激励信号。耳朵处的声音水平约为80 dBA。在入耳式耳机的外壳上附加了一个MEMS麦克风作为外部麦克风。在假头下方放置一个旋转圆盘,以评估不同DOA($0^o,45^o,…,315^o$)。实验以数字信号处理器(DSP)为计算核心,采样频率为48 kHz,低通滤波器截止频率为20 kHz。一款具有HT功能的商业入耳式耳机被同样使用,以进行公平的比较。图7(a)和图7(b)所示为设置。
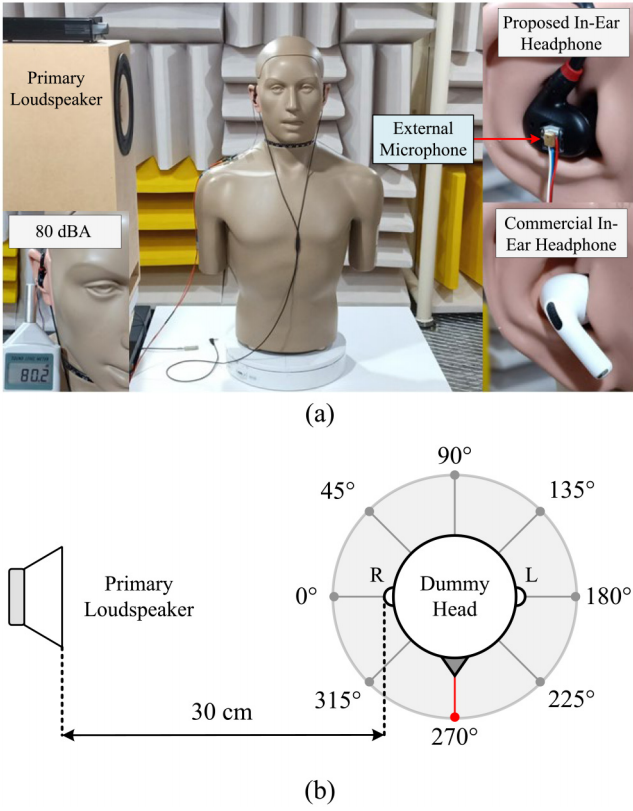
图7所示。(a)实验设置,(b)用DOA测试HT的设置
B. 实验结果
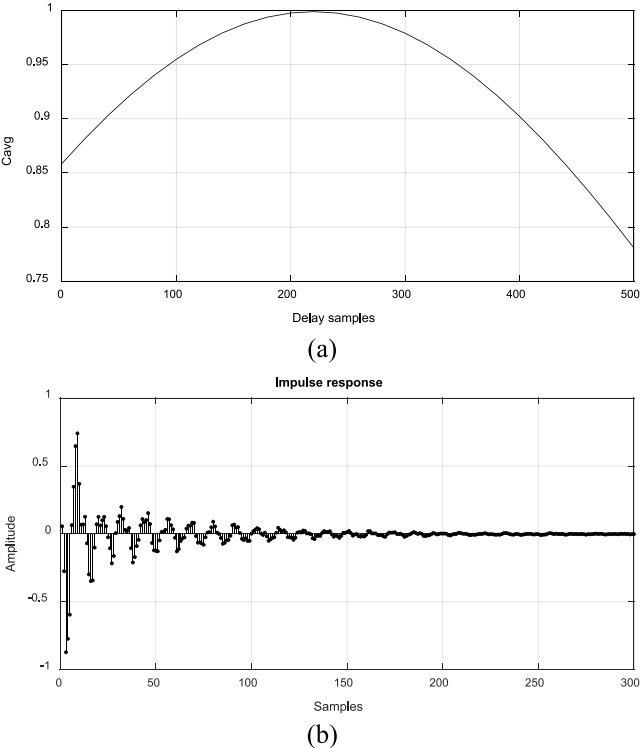
图8所示。(a)相干计算,(b)目标路径模型T(z)的脉冲响应
首先通过确定信号的相干$C_{avg}$并求$\Delta _1$,得到$x(n)$与$d(n)$之间的延迟,结果如图8(a)所示。从0到500的延迟样本进行了测试,发现$\Delta _1=220$处产生了最高的相干性。因此,可参考图4(b)估计目标路径模型$\hat{T}(z)$。图8(b)为得到的$\hat{T}(z)$的脉冲响应。它还建议大约300的滤波器长度应该用于提出的时移建模方案。
典型人类声音的频率范围小于4khz。为了使HT性能与DOA保持一致;因此,通过级联一个二阶IIR高通滤波器(截止频率为500Hz)和一个三阶IIR低通滤波器(截止频率为4kHz),基于如图5所示的耳机造成的被动隔离,设计了shaping filter $C(z)$。图9所示为shaping filter的频率响应。为了训练均衡滤波器$W_c(z)$,需要延迟$\Delta _2$来补偿由估计的次要路径引起的延迟。
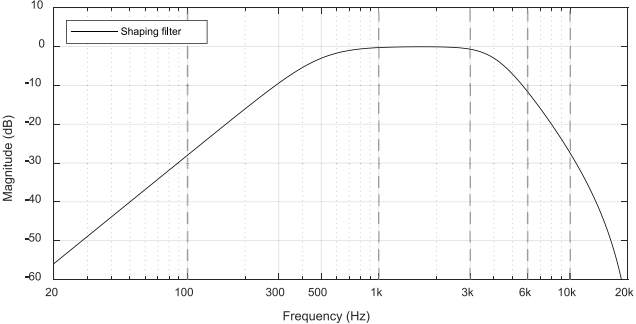
图9所示 整形滤波器C(z)的幅值响应
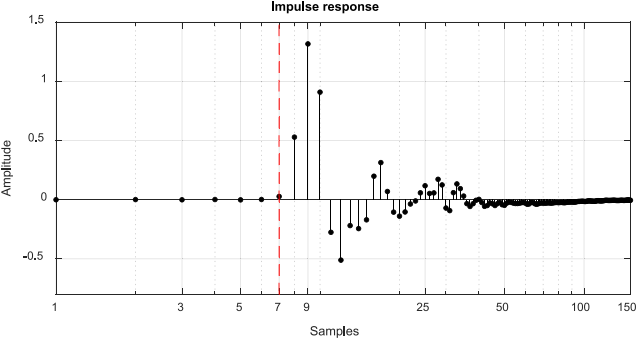
图10所示 二次路径模型S(z)的脉冲响应
图10给出了滤波长度为150的次路径模型$\hat{S}(z)$的脉冲响应。当采样率为48 kHz时,使用7个样本可以得到S(z)的延迟;因此,选择$\Delta _2=7$。通过对不同滤波器长度、延迟50秒的样本进行测试,图11给出了均衡滤波器$W_c(z)$推导过程中$e_b(n)$的均方误差(MSE)。显然,延迟$\Delta _2$必须大于7以最小化MSE,均衡滤波器$W_c(z)$的滤波器长度必须超过150。
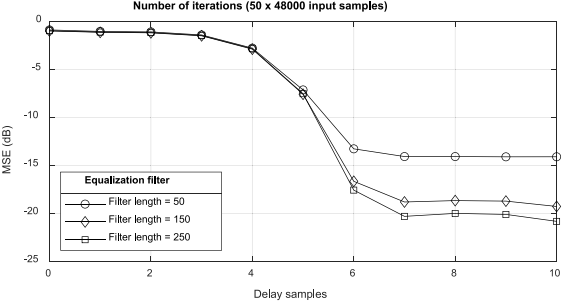
图11所示 $W_c(z)$在不同滤波长度和延迟采样条件下的MSE
下一个实验检验了整形滤波器的重要性,如图12所示。横轴表示假头右耳接收到声音的频率,纵轴表示衰减。蓝色、绿色、紫色线表示在假人的耳朵上安装入耳式耳机时得到的结果。本文所提出的HT方案的主动补偿目标是0 dB处的线。显然,入耳式耳机的大部分被动隔离来自500hz,如蓝线所示。绿色和紫色的线对应的结果,衰减的环境声补偿时,提出的HT方法与不shaping filter。因此,建议的带有shaping filter的方案(绿色线)优于没有整形滤波器的方案(紫色线),特别是对于低于1 kHz的组件。
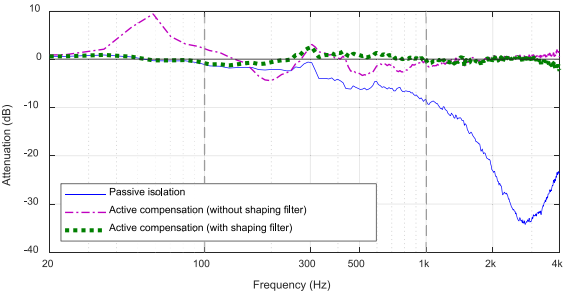
图12所示。所提HT系统的性能
接下来,将所提出方法的HT性能与Gupta等人的方法[23]和一款商用入耳式耳机进行比较。$270^o$ (20 Hz到20 kHz)的粉色噪音作为主要噪音播放。使用了假头的右耳。实验设置如图7所示。图13给出了由此得到的结果。黑色线和蓝色线分别代表不戴入耳式耳机和戴入耳式耳机时假人的右耳听到的声音。显然,图13(a)和图13(b)中黑色和蓝色线之间的差异是由被动隔离引起的。在图13(a)中,绿线和红线代表了本文和Gupta et al.[23]的HT结果。显然,所提出的HT几乎与图13(a)所示的从50 Hz到4 kHz的黑线相同。提出的HT方案也优于Gupta et al.[23]的HT方案,特别是在低于1 kHz的低频范围内。提出的方法只关注频率范围高达4 kHz,以解决DOA问题。
图13(b)中的绿线显示了激活HT功能后的商用入耳式耳机的性能。在感兴趣的频率范围内(100 Hz至2 kHz),拟议HT(图13(a)中的绿线和商业HT(图13(b)中的绿线)的性能几乎相同;然而,所提出的HT(图13(a))比商用HT(图13(b))表现更好,特别是在频率范围从2 kHz到4 kHz。

图13所示。使用(a)提议的入耳式耳机,(b)商用入耳式耳机的HT功能比较
商用耳机使用固定系数的均衡滤波器来执行HT功能。因此,针对DOA依赖问题,应重点关注低频补偿,因为低频性能与声音DOA无关。此外,所提出的方法使用整形滤波器,以避免放大不需要的高频信号,确保在不同DOA来声下的一致性,并防止低频人工声音的干扰。为了验证这一说法,我们评估了所提出的HT的性能,并将其与Gupta等人[23]和一款商用入耳式耳机的方案进行了比较。
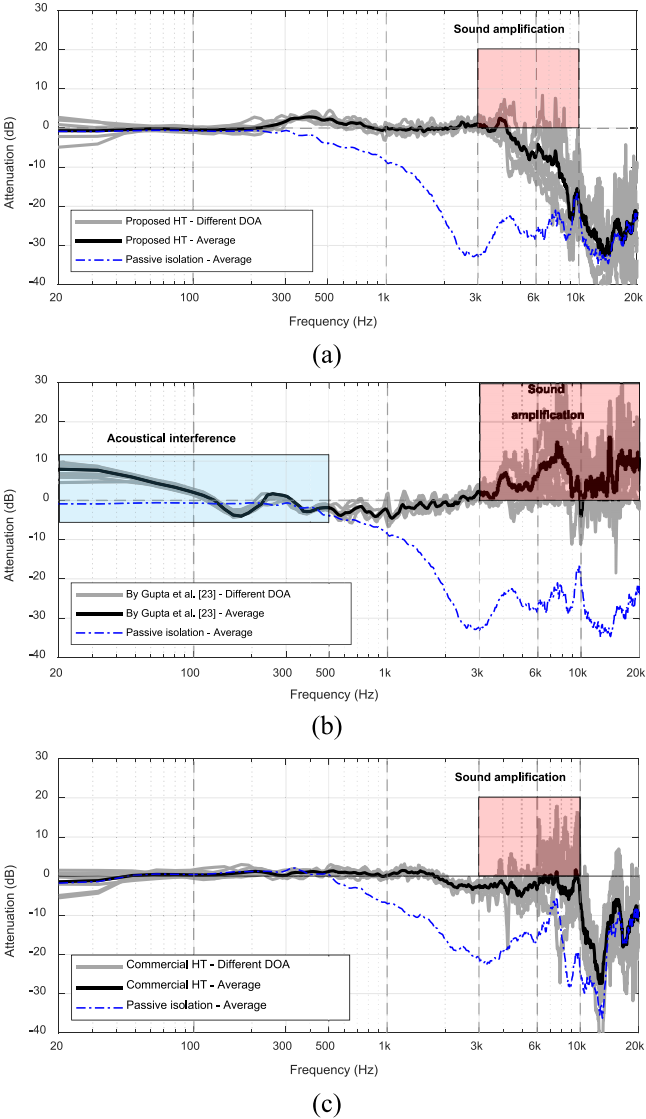
图14所示。使用HT技术的入耳式耳机DOA依赖关系,(a)提出的HT, (b) Gupta等人的HT方法[23],以及(c)商业HT
对比结果如图14所示。横轴表示从20hz到20khz的频率,纵轴表示耳机被动隔离的衰减。HT函数的完美补偿对应于0 dB处的性能,即无衰减。图14中的蓝线显示了使用入耳式耳机从假头的右耳接收到来自不同方向(0,45,…, 315)。HT性能由灰色线表示,这些线被平均后得到黑线。从图14(a)中可以看出,对于不同DOA声音,所提出的HT方案在4 kHz以下的性能基本一致。图14(b)显示了Gupta et al.[23]方法的性能,补偿后的声音会对500 Hz以下的残余声音产生声学干扰。另外,不同的DOA声音会在高频4 kHz以上造成不必要的声音放大,如图14(b)中的蓝色和红色区域所示。图14(c)展示了商用入耳式耳机的性能。显然,商用HT可以有效地补偿高达10 kHz的隔音,但它会导致比拟议HT在3 kHz至10 kHz之间更高的不必要的声音放大。这意味着商用入耳式耳机无法在不同DOA声音下保持一致的性能。该方案不仅减少了低频声干扰,而且有效地防止了高频声不必要的放大。
4 结论
HT技术是为入耳式耳机开发的,为消费者提供伪环境声。利用所提出的时移离线建模和AHE算法,所提供的均衡滤波器有效地补偿了入耳式耳机的被动隔离。所设计的整形滤波器确保了所述HT技术的性能在整个感兴趣的频率范围内是一致的,并且在低频时不会受到声波干扰,在高频时也不会受到不必要的声音放大。实验结果验证了该方法的性能。在感兴趣的频率范围内的外部环境声音可以为入耳式耳机的佩戴者使用所提出的HT技术完美地再现。
参考文献
[1] Hearable devices Global market trajectory & analytics, Global Ind. Anal. Inc., San Jose, CA, USA, Rep. 5302556, Apr. 2021.
[2] R. Miyahara, K. Oosugi, and A. Sugiyama, A hearing device with an adaptive noise canceller for noise-robust voice input, IEEE Trans. Consum. Electron., vol. 65, no. 4, pp. 444 453, Nov. 2019, doi: 10.1109/TCE.2019.2941708.
[3] T. Kawase, M. Okamoto, T. Fukutomi, and Y. Takahashi, Speech enhancement parameter adjustment to maximize accuracy of automatic speech recognition, IEEE Trans. Consum. Electron., vol. 66, no. 2, pp. 125 133, May 2020, doi: 10.1109/TCE.2020.2986003.
[4] S. Itani, S. Kita, and Y. Kajikawa, Multimodal personal ear authentication using acoustic ear feature for smartphone security, IEEE Trans. Consum. Electron., vol. 68, no. 1, pp. 77 84, Feb. 2022, doi: 10.1109/TCE.2021.3137474.
[5] J.-M. Yang, G. W. Lee, S. Kim, and H.-G. Moon, Multi-sensor speech enhancement using in-ear and beamforming signal synthesis in TWS voice communication, in Proc. IEEE Int. Conf. Consum. Electron. (ICCE), Las Vegas, NV, USA, Jan. 2022, pp. 1 6.
[6] Earphones and headphones market Global outlook and forecast 2021- 2026, Arizton Advisory Intell., Chicago, IL, USA, Rep. 5311280, Apr. 2021.
[7] V. Valimaki, A. Franck, J. Ramo, H. Gamper, and L. Savioja, Assisted listening using a headset: Enhancing audio perception in real, augmented, and virtual environments, IEEE Signal Process. Mag., vol. 32, no. 2, pp. 92 99, Mar. 2015, doi: 10.1109/MSP.2014.2369191.
[8] C.-Y. Chang, A. Siswanto, C.-Y. Ho, T.-K. Yeh, Y.-R. Chen, and S. M. Kuo, Listening in a noisy environment: Integration of active noise control in audio products, IEEE Consum. Electron. Mag., vol. 5, no. 4, pp. 34 43, Oct. 2016, doi: 10.1109/MCE.2016.2590159.
[9] M. T. Khan and R. A. Shaik, High-performance hardware design of block LMS adaptive noise canceller for in-ear headphones, IEEE Consum. Electron. Mag., vol. 9, no. 3, pp. 105 113, May 2020, doi: 10.1109/MCE.2020.2976418.
[10] L. Lu et al., A survey on active noise control in the past decade Part I: Linear systems, Signal Process., vol. 183, Jun. 2021, Art. no. 108039, doi: 10.1016/j.sigpro.2021.108039.
[11] L. Lu et al., A survey on active noise control in the past decade Part II: Nonlinear systems, Signal Process., vol. 181, Apr. 2021, Art. no. 107929, doi: 10.1016/j.sigpro.2020.107929.
[12] T. Lee, Y. Baek, Y.-C. Park, and D. H. Youn, Stereo upmixbased binaural auralization for mobile devices, IEEE Trans. Consum. Electron., vol. 60, no. 3, pp. 411 419, Aug. 2014, doi: 10.1109/TCE.2014.6937325.
[13] N. Lezzoum, G. Gagnon, and J. Voix, Voice activity detection system for smart earphones, IEEE Trans. Consum. Electron., vol. 60, no. 4, pp. 737 744, Nov. 2014, doi: 10.1109/TCE.2014.7027350.
[14] R. Ranjan and W.-S. Gan, Natural listening over headphones in augmented reality using adaptive filtering techniques, IEEE/ACM Trans. Audio, Speech, Language Process., vol. 23, no. 11, pp. 1988 2002, Nov. 2015, doi: 10.1109/TASLP.2015.2460459.
[15] S.-N. Yao, Headphone-based immersive audio for virtual reality headsets, IEEE Trans. Consum. Electron., vol. 63, no. 3, pp. 300 308, Aug. 2017, doi: 10.1109/TCE.2017.014951.
[16] J. Harth et al., Different types of users, different types of immersion: A user study of interaction design and immersion in consumer virtual reality, IEEE Consum. Electron. Mag., vol. 7, no. 4, pp. 36 43, Jul. 2018, doi: 10.1109/MCE.2018.2816218.
[17] W.-S. Gan, J. He, R. Ranjan, and R. Gupta, Natural and augmented listening for VR and AR/MR, in Proc. ICASSP Tutorial, Calgary, AB, Canada, Apr. 2018. [Online]. Available: https://sigport.org/ documents/icassp-2018-tutorial-t11-natual-and-augmented-listeningvrarmr (Accessed: Jul. 14, 2022).
[18] R. Gupta et al., Augmented/mixed reality audio for hearables: Sensing, control, and rendering, IEEE Signal Process. Mag., vol. 39, no. 3, pp. 63 89, May 2022, doi: 10.1109/MSP.2021.3110108.
[19] Active noise cancelling (ANC) headphones market Global outlook and forecast 2019 2024, Arizton Advisory Intell., Chicago, IL, USA, Rep. 4825751, Aug. 2019.
[20] S. M. Kuo, Y.-R. Chen, C.-Y. Chang, and C.-W. Lai, Development and evaluation of light-weight active noise cancellation earphones, Appl. Sci., vol. 8, no. 7, p. 1178, Jul. 2018, doi: 10.3390/app8071178.
[21] H. Schepker, F. Denk, B. Kollmeier, and S. Doclo, Acoustic transparency in hearables Perceptual sound quality evaluations, J. Audio Eng. Soc., vol. 68, nos. 7 8, pp. 495 507, Jul. 2020, doi: 10.17743/jaes.2020.0045.
[22] F. Denk, H. Schepker, S. Doclo, and B. Kollmeier, Acoustic transparency in hearables Technical evaluation, J. Audio Eng. Soc., vol. 68, nos. 7 8, pp. 508 521, Jul. 2020, doi: 10.17743/jaes.2020.0042.
[23] R. Gupta, R. Ranjan, J. He, W.-S. Gan, and S. Peksi, Acoustic transparency in hearables for augmented reality audio: Hear-through techniques review and challenges, in Proc. AES Int. Conf. AVAR, Aug. 2020, pp. 3 7.
[24] R. Gupta, R. Ranjan, J. He, and W.-S. Gan, Parametric hear through equalization for augmented reality audio, in Proc. IEEE 44th Int. Conf. Acoust. Speech Signal Process. (ICASSP), Brighton, U.K., May 2019, pp. 1587 1591.
[25] J. Rämö and V. Välimäki, An allpass hear-through headset, in Proc. 22nd Eur. Signal Process. Conf. (EUSIPCO), Lisbon, Portugal, Sep. 2014, pp. 1123 1127.
[26] J. Rämö and V. Välimäki, Digital augmented reality audio headset, J. Electr. Comput. Eng., vol. 2012, pp. 1 13, Oct. 2012, doi: 10.1155/2012/457374.
[27] S. Liebich, J.-G. Richter, J. Fabry, C. Durand, J. Fels, and P. Jax, Direction-of-arrival dependency of active noise cancellation headphones, in Proc. 47th Int. Congr. Expo. Noise Control Eng. (INTERNOISE), Chicago, IL, USA, Aug. 2018, pp. 1 10.
[28] S. Liebich and P. Vary, Occlusion effect cancellation in headphones and hearing devices The sister of active noise cancellation, IEEE/ACM Trans. Audio, Speech, Language Process., vol. 30, pp. 35 48, 2022, doi: 10.1109/TASLP.2021.3130966.
[29] V. Patel, J. Cheer, and S. Fontana, Design and implementation of an active noise control headphone with directional hear-through capability, IEEE Trans. Consum. Electron., vol. 66, no. 1, pp. 32 40, Feb. 2020, doi: 10.1109/TCE.2019.2956634.
[30] Y. Zhuang and Y. Liu, A constrained optimal hear-through filter design approach for earphones, in Proc. 50th Int. Congr. Expo. Noise Control Eng. (INTERNOISE), Washington, DC, USA, Aug. 2021, pp. 1329 1337.
[31] R. Gupta, R. Ranjan, J. He, and W.-S. Gan, Study on differences between individualized and non-individualized hear-through equalization for natural augmented listening, in Proc. AES Int. Conf. Headphone Technol., San Francisco, CA, USA, Aug. 2019, p. 12.
[32] W. Jin, T. Schoof, and H. Schepker, Individualized hear-through for acoustic transparency using PCA-based sound pressure estimation at the eardrum, in Proc. IEEE 47th Int. Conf. Acoust. Speech Signal Process. (ICASSP), Singapore, May 2022, pp. 341 345.
[33] R. Gupta, R. Ranjan, J. He, and W.-S. Gan, On the use of closed-back headphones for active hear-through equalization in augmented reality applications, in Proc. AES Int. Conf. AVAR, Redmond, WA, USA, Aug. 2018, p. P8-2.
[34] S. Liebich, J. Fabry, P. Jax, and P. Vary, Signal processing challenges for active noise cancellation headphones, in Proc. 13th ITG-Symp. Speech Comm., Oldenburg, Germany, Oct. 2018, pp. 1 5.
[35] S. M. Kuo and D. R. Morgan, Active Noise Control Systems: Algorithms and DSP Implementations. New York, NY, USA: Wiley, 1996, pp. 56 58.
[36] S. M. Kuo and D. R. Morgan, Active noise control: A tutorial review, Proc. IEEE, vol. 87, no. 6, pp. 943 973, Jun. 1999, doi: 10.1109/5.763310.

黄崇瑞1993年出生于台湾。他于2017年获得台湾桃园市建新科技大学电子工程学士学位,并于2019年获得桃园市中原基督教大学电气工程硕士学位,目前正在攻读电气工程博士学位。主要研究方向为主动噪声控制、声信号处理、自适应信号处理、嵌入式系统等。

张成元1968年出生于台湾。他于1990年和1994年分别获得台湾新竹国立交通大学控制工程学士学位和硕士学位,并于2000年获得台湾桃园国立中央大学电气工程博士学位。2007年,他加入台湾中原基督教大学电气工程系,目前是该校特聘教授。2009年至2011年,2013年至2019年,他担任该部门的主席。2012年任美国北伊利诺伊大学客座教授。主要研究方向为信号处理应用和有源噪声控制系统设计。他曾于2007年至2011年担任TASSE秘书,并于2013年至2015年担任IEEE台北分会秘书。

郭明明先生1976年毕业于台北市国立台湾师范大学,获理学学士学位;1983年和1985年分别获得美国新墨西哥大学(Albuquerque, NM)硕士和博士学位。1985年至2014年,他在北伊利诺伊大学迪卡尔布分校工作,2002年至2008年担任系主任。2014年至2021年,他担任中原基督教大学电气工程系名誉讲座教授。1993年,他在德克萨斯州休斯顿的德州仪器公司工作,2008年在中央大学工作。他是三本书的主要作者:有源噪声控制系统(Wiley, 1996)、实时数字信号处理(Wiley, 2001, 2007和2013)和数字信号处理器(Prentice-Hall, 2005),并与人合著了三本书:微信号架构的嵌入式信号处理(Wiley, 2007)、子带自适应滤波(Wiley, 2009)和有源噪声控制系统的二次路径建模技术(施普林格)。他拥有10项美国专利。他的研究主要集中在主动噪声和振动控制,实时DSP应用,数字音频应用和生物医学信号处理。他是1993年IEEE切斯特萨勒奖(IEEE transactions on Consumer Electronics)第一交易论文奖的获得者,2001年因在研究和学术领域的成就而获得年度教员奖。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/159049.html

