
引言
深度神经网络模型被广泛应用在图像分类、物体检测等机器视觉任务中,并取得了巨大成功。然而,由于存储空间和功耗的限制,神经网络模型在嵌入式设备上的存储与计算仍然是一个巨大的挑战。
目前工业级和学术界设计轻量化神经网络模型主要有4个方向:
- 人工设计轻量化神经网络模型
- 基于神经网络架构搜索(Neural Architecture Search,NAS)的自动化设计神经网络
- CNN模型压缩
- 基于AutoML的自动模型压缩
本文首先介绍基本卷积计算单元,并基于这些单元介绍MobileNet V1&V2,ShuffleNet V1&V2的设计思路。其次,最后介绍自动化设计神经网络的主流方法和基本思路。最后概述CNN模型压缩的主要方法,详细说明基于AutoML的自动模型压缩的相关算法:AMC、PockFlow以及TensorFlow lite的代码实现。
基本卷积运算
标准卷积
卷积层的 输入为$(N,C_{in},H_{in},W_{in})$。输出为 $(N,C_{out},H_{out},W_{out})$,其中$H_{\text{out}}$和$W_{\text{out}}$ 分别为特征图的高度和宽度。卷积核(Kernel)的高和宽:$K[0]$和$K[1]$
$$FLOPS=(C_{in}*K[0]·K[1])*H_{\text{out}}·W_{\text{out}}*C_{out}\quad(考虑bias)$$
输出特征图中有$H_{\text{out}}*W_{\text{out}}*C_{out}$个像素;每个像素对应一个立体卷积核$k[0]*k[1]*C_{in}$在输入特征图上做立体卷积卷积出来的;而这个立体卷积操作,卷积核上每个点都对应一次MACC操作


图3标准卷积:空间维度和通道维度示意图
吃个例子
输入shape为(7*7*3),卷积核大小为(filter size)(3*3*3),卷积核个数(filter num \ channel_out)为2,输出shape为(3*3*2)。

Grouped Convolution
分组卷积是标准卷积的变体,其中输入特征通道被为G组(图4),并且对于每个分组的信道独立地执行卷积,则分组卷积计算量为标准卷积计算量的1/G:
$$FLOPS=\frac{(C_{in}*K[0]*K[1])*H_{\text{out}}*W_{\text{out}}*C_{out}}{G}$$

分组卷积:空间维度和通道维度示意图
Depthwise convolution
引用:Chollet F. Xception: Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1251-1258.
Depthwise convolution 是指将输入特征图$(batch\_size, H\_{in}, W\_{in}, C\_{in})$分为group组,Group=$C\_{in}$(既Depthwise 是Grouped Convlution的特殊简化形式),然后每一组做k*k卷积,Depthwise convolution的计算量为普通卷积的$1/C_{in}$,通过忽略通道维度的卷积显著降低计算量
$$FLOPS=K[0]*K[1]*H_{\text{out}}*W_{\text{out}}*C_{in}$$
Depthwise相当于单独收集每个Channel的空间特征。

Depthwise卷积:空间维度和通道维度示意图
pointwise convolution
Pointwise是指对输入$(batch\_size, H\_{in}, W\_{in}, C\_{in})$做$k$个普通的 1×1卷积,主要用于改变输出通道特征维度,相当于在通道之间“混合”信息。Pointwise计算量为
$$FLOPS=H_{\text{out}}*W_{\text{out}}*C_{in}*C_{out}$$

Pointwise卷积:空间维度和通道维度示意图
Channel Shuffle
Grouped Convlution导致模型的信息流限制在各个group内,组与组之间没有信息交换,这会影响模型的表示能力。因此,需要引入group之间信息交换的机制,即Channel Shuffle操作。
Channel shuffle是ShuffleNet提出的,通过张量的reshape 和transpose,实现改变通道之间顺序。Channel shuffle没有卷积计算,仅简单改变通道的顺序。

Channel shuffle:空间维度和通道维度示意图
2 轻量化模型设计
SequeezeNet
Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size[J]. arXiv preprint arXiv:1602.07360, 2016.
在网络结构设计方面主要采取以下三种方式:
- 用1*1卷积核替换3*3卷积:理论上一个1*1卷积核的参数是一个3*3卷积核的1/9,可以将模型尺寸压缩9倍。
- 减小3*3卷积的输入通道数:根据上述公式,减少输入通道数不仅可以减少卷积的运算量,而且输入通道数与输出通道数相同时还可以减少MAC。
- 延迟降采样:分辨率越大的输入能够提供更多特征的信息,有利于网络的训练判断,延迟降采样可以提高网络精度。
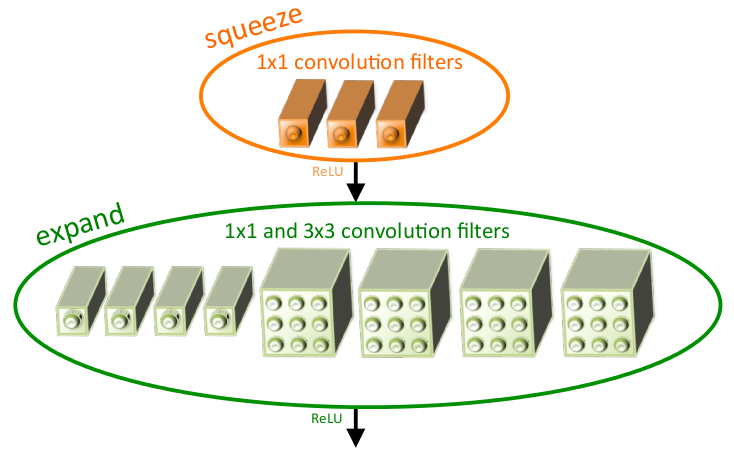
SqueezeNet提出一种多分支结构——fire model,其中是由Squeeze层和expand层构成。Squeeze层是由s1个1*1卷积组成,主要是通过1*1的卷积降低expand层的输入维度;expand层利用e1个1*1和e3个3*3卷积构成多分支结构提取输入特征,以此提高网络的精度(其中e1=e3=4*s1)。
DepthwiseSeparableConv
Howard A G, Zhu M, Chen B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint arXiv:1704.04861, 2017.
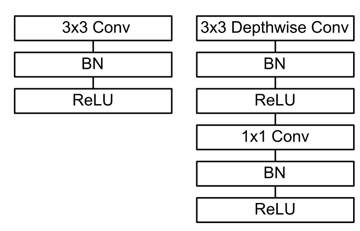
深度可分离卷积由 一个深度卷积(depthwise convolution)和一个逐点卷积(pointwise convolution)组成。
- 采用深度卷积(depthwise convolution)在减少参数数量的同时提升运算速度。但是由于每个feature map只被一个卷积核卷积,因此经过深度卷积输出的feature map不能只包含输入特征图的全部信息,而且特征之间的信息不能进行交流,导致“信息流通不畅”。
- 采用逐点卷积(pointwise convolution)实现通道特征信息交流,解决深度卷积卷积导致“信息流通不畅”的问题。
深度可分离卷积总计算量是:
$$FLOPS = depthwise+pointwise =K[0]*K[1]*H_{\text{out}}*W_{\text{out}}*C_{in}+H_{\text{out}}*W_{\text{out}}*C_{in}*C_{out}=H_{\text{out}}*W_{\text{out}}*C_{in}(K[0]*K[1]+C_{out})$$
$$\frac{depthwise+pointwise}{conv}=\frac{H_{\text{out}}*W_{\text{out}}*C_{in}(K[0]*K[1]+C_{out})}{(C_{in}*K[0]·K[1])*H_{\text{out}}·W_{\text{out}}*C_{out}}=\frac{1}{C_{out}}+\frac{1}{(K[0]·K[1]}$$
一般网络架构中$C_{out}$远大于卷积核尺寸,(e.g. K=3 and M ≥ 32),既深度可分离卷积计算量可显著降低标准卷积计算量的1/8–1/9。

深度可分离卷积:空间维度和通道维度示意图
MobileNet-v2
Sandler M, Howard A, Zhu M, et al. Mobilenetv2: Inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4510-4520.
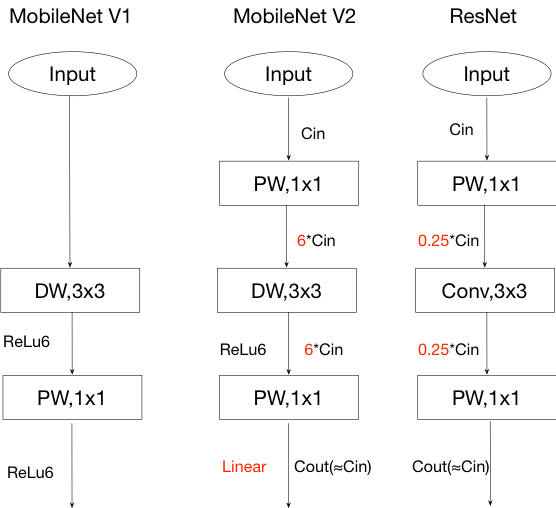
MobileNet V1设计时参考传统的VGGNet等链式架构,但层叠过多的卷积层会出现一个问题,就是梯度弥散(Vanishing)。残差网络使信息更容易在各层之间流动,包括在前向传播时提供特征重用,在反向传播时缓解梯度信号消失。于是改进版的MobileNet V2[3]增加skip connection,并且对ResNet和Mobilenet V1基本Block如下改进:
- 采用Inverted residuals:为了保证网络可以提取更多的特征,在residual block中第一个1*1 Conv和3*3 DW Conv之前进行通道扩充
- Linear bottlenecks:为了避免ReLU对特征的破坏,在residual block的Eltwise sum之前的那个 1*1 Conv 不再采用ReLU
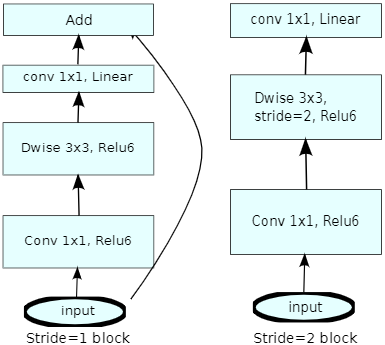
- stride=2的Conv不使用shot-cot,stride=1的Conv使用shot-cut
Inverted residuals
ResNet中Residuals block先经过1*1的卷积,把feature map的通道数降下来,再经过3*3 卷积,最后经过一个1*1 的卷积将通道数再“扩张”回去。即采用先压缩,后扩张的方式。inverted residuals采用先扩张,后压缩的方式。
原因:MobileNet采用DW conv提取特征,由于DW conv本身提取的特征数就少,再经过传统residuals block进行“压缩”,此时提取的特征数会更少,因此inverted residuals对其进行“扩张”,保证网络可以提取更多的特征。
Linear bottlenecks
ReLu激活函数会破坏特征。ReLu对于负的输入,输出全为0,而本来DW conv特征通道已经被“压缩”,再经过ReLu的话,又会损失一部分特征。采用Linear,目的是防止Relu破坏特征。
shortcut
stride=2的conv不使用shot-cot,stride=1的conv使用shot-cut
ShuffleNet-v1
Zhang X, Zhou X, Lin M, et al. Shufflenet: An extremely efficient convolutional neural network for mobile devices[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 6848-6856.
MobileNet中1*1卷积的操作占据了约95%的计算量,所以ShuffleNet将1*1也更改为group卷积,使得相比MobileNet的计算量大大减少。group卷积与DW存在同样使“通道信息交流不畅”的问题,MobileNet中采用pointwise(PW) Conv解决上述问题,SheffleNet中采用channel shuffle,将输入的group进行打散,从而保证每个卷积核的感受野能够分散到不同group的输入中,增加了模型的学习能力。
- 采用group conv减少大量参数:roup conv与DW conv存在相同的“信息流通不畅”问题
- 采用channel shuffle解决上述问题:MobileNet中采用PW conv解决上述问题,SheffleNet中采用channel shuffle
- 采用concat替换add操作:avg pooling和DW conv(s=2)会减小feature map的分辨率,采用concat增加通道数从而弥补分辨率减小而带来信息的损失
ShuffleNet的shuffle操作如图所示
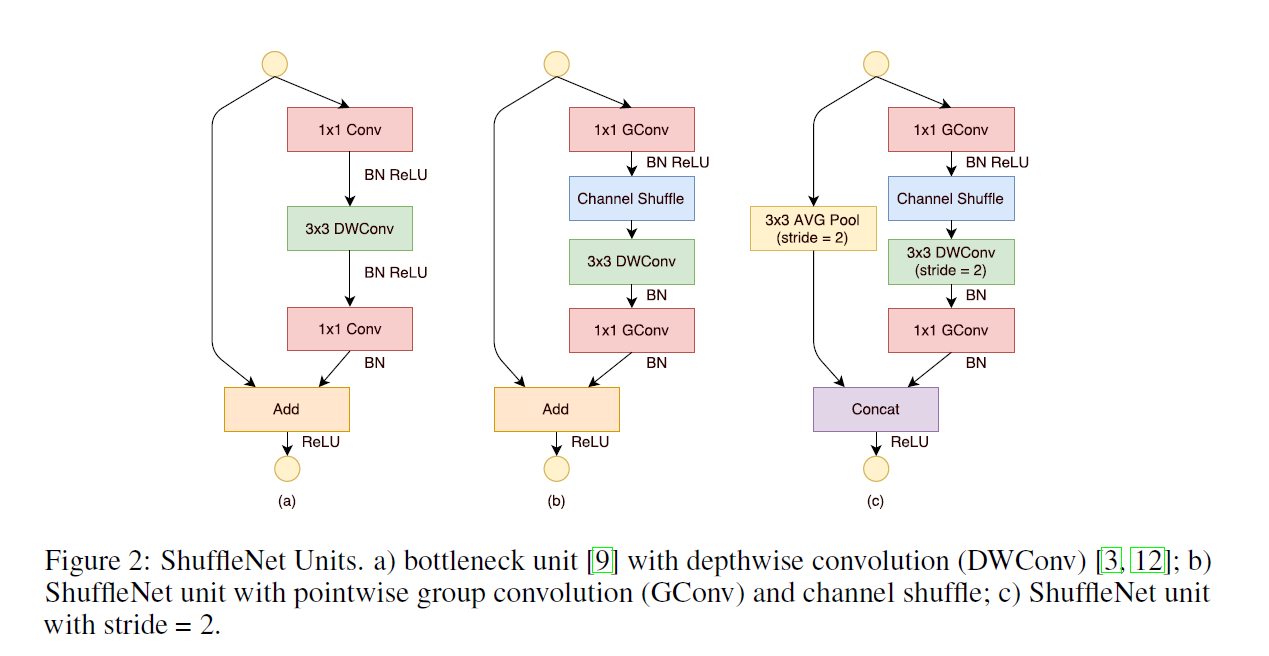
avg pooling和DW conv(s=2)会减小feature map的分辨率,采用concat增加通道数从而弥补分辨率减小而带来信息的损失;实验表明:多使用多通道(提升通道的使用率),有助于提高小模型的准确率。
ResNet bootleneck计算量:
$$FLOPS=H_{out}*W_{out}(2*C_{in}*C_{in}+K[0]*K[1]*C_{in}*C_{in})$$
ShuffleNet stride=1计算量:
$FLOPS=H_{out}*W_{out}(\frac{2*C_{in}*C_{in}}{8}+K*C_{in}*C_{in})$
对比可知,ShuffleNet和ResNet结构可知,ShuffleNet计算量降低主要是通过分组卷积实现。ShuffleNet虽然降低了计算量,但是引入两个新的问题:
- channel shuffle在工程实现占用大量内存和指针跳转,这部分很耗时。
- channel shuffle的规则是人工设计,分组之间信息交流存在随意性,没有理论指导。
ShuffleNet-v2
Ma N, Zhang X, Zheng H T, et al. Shufflenet v2: Practical guidelines for efficient cnn architecture design[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 116-131.
ShuffleNet-v2提出影响神经网络速度的4个因素:
- FLOPs(FLOPs就是网络执行了多少multiply-adds操作)
- MAC(内存访问成本)
- 并行度(如果网络并行度高,速度明显提升)
- 计算平台(GPU,ARM)
ShuffleNet-v2 提出了4点网络结构设计策略:
- 输入输出的channel相同时,MAC最小
- 组卷积会增加MAC
- 多分支降低运算效率;
- 元素级运算增加计算量
depthwise convolution 和 瓶颈结构增加了 MAC,用了太多的 group,跨层连接中的 element-wise Add 操作也是可以优化的点。所以在 shuffleNet V2 中增加了几种新特性。
ShuffleNet V2 引入通道分割(channel split)操作,将输入通道分为两组:一个分支为shortcut流,另一个分支含三个卷积(且三个分支的通道数一样),分支合并采用拼接(concat),让前后的channel数相同,最后进行Channel Shuffle。元素级的三个运算channel split、concat、Channel Shuffle合并一个Element-wise,显著降低计算复杂度。
所谓的 channel split 其实就是将通道数一分为2,化成两分支来代替原先的分组卷积结构,并且每个分支中的卷积层都是保持输入输出通道数相同,其中一个分支不采取任何操作减少基本单元数,最后使用了 concat 代替原来的 elementy-wise add,并且后面不加 ReLU,再加入channle shuffle 来增加通道之间的信息交流。 对于下采样层,在这一层中对通道数进行翻倍。 在网络结构的最后,即平均值池化层前加入一层 1×1 的卷积层来进一步的混合特征。
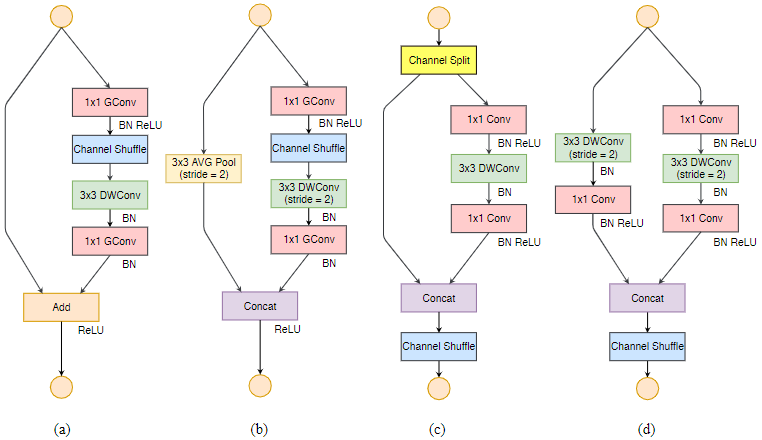
(a)ShuffleNet 基本单元;(b)用于空间下采样 (2×) 的 ShuffleNet 单元
(c)ShuffleNet V2 的基本单元;(d)用于空间下采样 (2×) 的 ShuffleNet V2 单元
由于高效,可以增加更多的channel,增加网络容量,采用split使得一部分特征直接与下面的block相连,特征复用(DenseNet)
Xception
Chollet F. Xception: Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1251-1258.
Xception假设卷积的时候要将通道的卷积与空间的卷积进行分离,这样会比较好。Xception是对Inception v3的另一种改进,主要是采用depthwise separable convolution来替换原来Inception v3中的卷积操作。
与原版的Depth-wise convolution有两个不同之处:
- 原版Depth-wise convolution,先逐通道卷积,再1*1卷积;而Xception是反过来,先1*1卷积,再逐通道卷积;
- 原版Depth-wise convolution的两个卷积之间是不带激活函数的,而Xception在经过1*1卷积之后会带上一个Relu的非线性激活函数;
Xception的发展流程如下:

图:左:Inception module (Inception V3);中:A simplified Inception module;右:XInception 模块
总结
在移动端部署深度卷积网络,无论什么视觉任务,选择高精度的计算量少和参数少的骨干网是必经之路。轻量化网络是移动端的研究重点,目前的一些主要的轻量化网络及特点如下:
- SqueezeNet:提出Fire Module设计,主要思想是先通过1×1卷积压缩通道数(Squeeze),再通过并行使用1×1卷积和3×3卷积来抽取特征(Expand),通过延迟下采样阶段来保证精度。综合来说,SqueezeNet旨在减少参数量来加速。
通过减少MAdds来加速的轻量模型:
- MobileNet V1:提出深度可分离卷积;
- MobileNet V2:提出反转残差线性瓶颈块;
- ShuffleNet:结合使用分组卷积和通道混洗操作;
- CondenseNet:dense连接
- ShiftNet:利用shift操作和逐点卷积代替了昂贵的空间卷积
从SqueezeNet开始模型的参数量就不断下降,为了进一步减少模型的实际操作数(MAdds),MobileNetV1利用了深度可分离卷积提高了计算效率,而MobileNetV2则加入了线性bottlenecks和反转残差模块构成了高效的基本模块。随后的ShuffleNet充分利用了组卷积和通道shuffle进一步提高模型效率。CondenseNet则学习保留有效的dense连接在保持精度的同时降低,ShiftNet则利用shift操作和逐点卷积代替了昂贵的空间卷积。
(1)MobileNet-v1中深度可分离卷积的理解:
将传统卷积分解为空间滤波和特征生成两个步骤,空间滤波对应较轻的3×3 depthwise conv layer,特征生成对应较重的1×1 pointwise conv layer.
(2)MobileNet-v2中反转残差线性瓶颈块的理解:
扩张(1×1 conv) -> 抽取特征(3×3 depthwise)-> 压缩(1×1 conv)
当且仅当输入输出具有相同的通道数时,才进行残余连接
在最后“压缩”完以后,没有接ReLU激活,作者认为这样会引起较大的信息损失
该结构在输入和输出处保持紧凑的表示,同时在内部扩展到更高维的特征空间,以增加非线性每通道变换的表现力。
(3)MnasNet理解:
在MobileNet-v2的基础上构建,融入SENet的思想
与SE-ResBlock相比,不同点在于SE-ResBlock的SE layer加在最后一个1×1卷积后,而MnasNet的SE layer加在depthwise卷积之后,也就是在通道数最多的feature map上做Attention。
(4)MobileNet-v3的理解:
MobileNet-v3集现有轻量模型思想于一体,主要包括:swish非线性激活Squeeze and Excitation思想为了减轻计算swish中传统sigmoid的代价,提出了hard sigmoid
这么一看就发现,轻量化主要得益于depth-wise convolution,因此大家可以考虑采用depth-wise convolution 来设计自己的轻量化网络, 但是要注意“信息流通不畅问题”
解决“信息流通不畅”的问题,MobileNet采用了point-wise convolution,ShuffleNet采用的是channel shuffle。MobileNet相较于ShuffleNet使用了更多的卷积,计算量和参数量上是劣势,但是增加了非线性层数,理论上特征更抽象,更高级了;ShuffleNet则省去point-wise convolution,采用channel shuffle,简单明了,省去卷积步骤,减少了参数量。
参考
【Github文章】深度学习500问
【知乎】轻量化神经网络综述(文后还有NAS与神经网络架构搜索、AutoML自动模型压缩)
【卷积动图】https://cs231n.github.io/assets/conv-demo/index.html
【CSDN】最全动画诠释各种卷积网络及实现机制
【github】卷积动画
【github】ShuffleNet-Series
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/159113.html

