
论文地址:声学回声消除与双信号变换LSTM网络
预训练模型:https://github.com/breizhn/DTLN-aec
论文代码:https://github.com/breizhn/DTLN
博客作者:
摘要
本文将双信号变换LSTM网络(dual-signal transformation LSTM network,DTLN)应用于实时声学回声消除(AEC)任务。DTLN在堆叠网络方法中结合了短时傅里叶变换和learned 特征表示,从而可以在时频和时域中进行可靠的信息处理,其中还包括相位信息。该模型在真实和合成的回声场景中训练60小时。训练设置包括多语种语音,数据增强,额加噪音和混响,以创建一个模型,该模型应能很好地推广到各种现实世界中。DTLN方法可在干净和嘈杂的回声条件下产生最先进的性能,从而有效减少声回声和额外的噪声。 该方法的平均意见得分(MOS)优于AEC挑战基线0.30。
索引词:AEC, real-time, deep learning, audio, voicecommunication
1 引言
2 方法
2.1 问题公式化
对于声学回声消除系统,通常可以使用两个输入信号,即麦克风信号$y(n)$和远端麦克风信号$x(n)$。 可以将近端麦克风信号描述为以下信号的组合:
$$公式1:y((n)=s(n)+v(n)+d(n)$$
其中$s(n)$是近端语音信号,$v(n)$是可能的近端噪声信号,$d(n)$对应于回声信号,它是远端麦克风信号$x(n)$与传输路径的脉冲响应$h(n)$的卷积。传输路径是由音频设备的缓冲产生的系统延迟、扬声器与放大器的结合特性以及近端扬声器和近端麦克风之间的传递函数的组合。 声学回声场景如图1所示。所需信号是近端语音信号$s(n)$,而所有其他信号部分都应删除。 此任务是音频源分离任务。 如果只有远端信号和噪声信号存在,那么期望的信号就是安静。
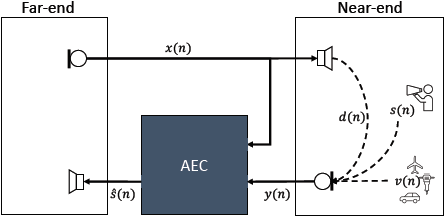
图1 带有附加噪声的回声场景说明
2.2 适用于AEC的DTLN模型
在Interspeech 2020的DNS挑战[12]的背景下,开发了双信号转换LSTM网络(DTLN)[15]以减少嘈杂语音混合物中的噪声。 DTLN方法适用于AEC任务(DTLN-aec1),下面将进行介绍。
该网络由两个separation cores(分离核心)组成。 每个separation cores都有两个LSTM层和一个全连接层,并通过S型激活函数来预测masks(掩模)。 第一 separation cores 由近端和远端麦克风信号的串联归一化对数功率谱fed。 每个麦克风信号分别被instant layer normalization(瞬时层归一化,iLN),以解决level变化问题。Instant layer normalization类似于standard layer normalization [20],其中每个帧都单独归一化,但不随时间累积统计信息。 该概念在[21]中作为channel-wise layer标准化引入。 第一core预测 时频掩码,该时频mask应用于近端麦克风信号的非归一化幅度STFT。 使用原始近端麦克风信号的相位,通过逆FFT将估计的幅度转换回时域。
第二个core使用通过1D-Conv图层创建的learned特征表示。 这种方法的灵感来自[9,22]。核心被fed先前预测信号的归一化特征表示和远端麦克风信号的归一化特征表示。 为了将两个信号都转换到时域,应用了相同的权重,但是分别使用iLN进行归一化,以实现每个表示形式的单独scaling(缩放)和bias(偏置)。 将第二核的预测掩码与第一核的输出的未归一化特征表示相乘。 通过1D-Conv层将该估计的特征表示转换回时域。 为了重建连续时间信号,使用重叠相加过程。 模型架构如图2所示。
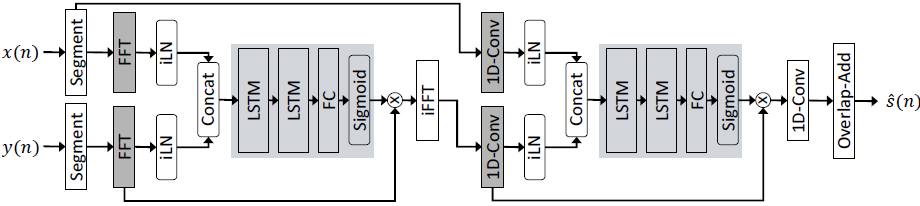
图2 提出的DTLN-aec模型体系结构。左边的处理链显示第一个separation core利用STFT信号变换(近端和远端麦克风信号的split in segmentation和FFT),右边的构建块代表第二个核,将基于1D-Conv层的学习特征转换应用于第一个核的输出和segmented 远端麦克风信号。
对于回声消除任务,选择了32ms的帧长和8ms的帧偏移。FFT的大小是512,学习的特征表示的大小也是512。由于从语音中去除语音和噪声非常困难,与[15]中相当小的模型相比,每层选择512个LSTM单元。因此,当前模型的参数总数为10.3M。此外,还对每层具有128和256个单位的模型进行了训练,以探索模型性能如何随size 变化。
2.3 数据集和数据集准备
2.4 训练和数据增强
2.5 基线系统
2.6 客观和主观评价
3 结果
4 总结
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/159121.html

