
六月初到六月中旬,一转眼二十天过去了,又开始新的起点
大数据
1、Hadoop是个什么东东
Hadoop是一个 开源的【分布式计算 + 分布式存储平台】,是一个大数据的基础架构,基于此进行开发。
2、Haddop能做什么
它能搭建大型数据仓库,PB级别数据的存储、处理、分析、统计等业务。
主要的使用场景如:
搜索引擎数据分析、
海量日志分析【一般这个场景多】、
商业智能【数据报表的呈现】、
数据挖掘【沙子里淘金】
3、Hadoop的核心组件
3.1 分布式文件系统:HDFS
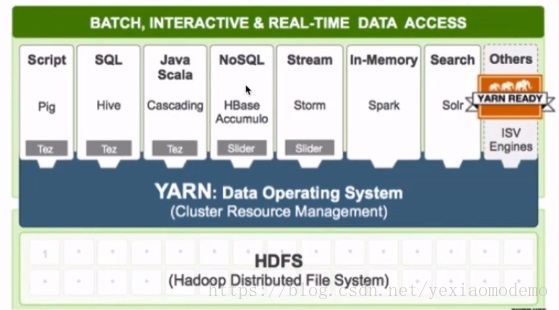
3.2 资源调度管理系统:YARN
负责整个集群资源的管理调度
YARN的处理能够只需要有hadoop的集群即可,不再需要把 Hive、Hbase 也安装集群,全部交由YARN做资源调度。

3.3 分布式计算框架:MapReduce
海量数据离线处理
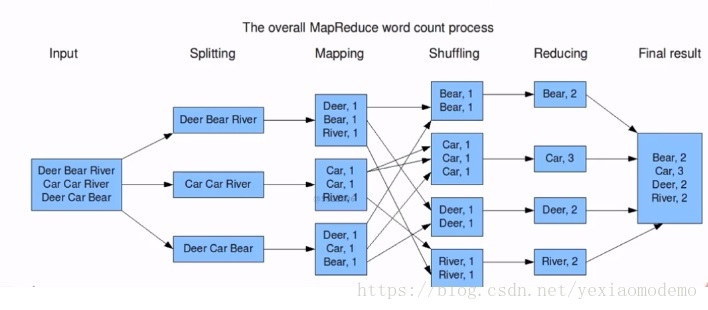
如上面的三个词条的分析,分拆成三个给三个端处理,让后通过计算结果,再合并,做最后返回。
4、Hadoop优势
Hadoop的可靠性:
数据存储:文件多副本、文件拆分成多副本
数据计算:重新调度作业计算
Hadoop的扩展性:
存储/计算资源不够时:可以横向的线性扩展机器,提升资源
一个集群可以有上千的节点保证资源的可用。
Hadoop其他优势:
存储可扩展在廉价机器
成熟的生态圈(Hive,Spark,Hbase)什么的,火的不要不要。
5、狭义Hadoop 与 广义Hadoop
5.1 狭义Hadoop
是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)
和资源调度(YARN)的基础平台而已。这仅仅是一个框架
5.2 广义Hadoop
Hadoop生态系统,Hadoop生态系统是一个非常非常的概念,Hadoop只是其中最基础重要的部分。生态系统里面每一个子系统都是只解决某一个特定的问题域(甚至很小)。而现在在市场上招聘的大数据工程师:指的都是广义的Hadoop,需要动里面的每一个子系统的,所以知识量其实非常大。
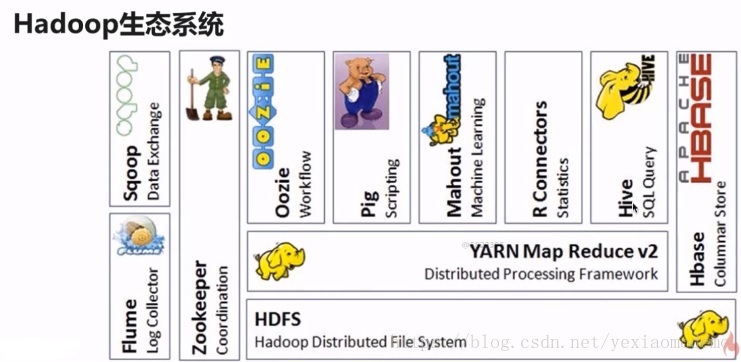
简单说明一下:
HDFS:Hadoop的文件服务系统
YARN:可能也使用Spark 资源调度器
Hbase:Hadoop的数据库,能存储海量数据
Hive:提供一种hiveSQL的sql语言做数据查询。Facebook开源的类似sql查询。(通过Hive的查询引擎转成YARN 去Hadoop做查询)
Rconnectors:统计分析的东东
Mahout:机器学习的东西,已经更不更新了
Pig:脚本语言(离线分析)
Oozie:工作流引擎。
Zookeeper:分布式协调服务。单点故障切换等操作
Flume:nginx ,容器的日志收集做大数据处理分析
Sqoop:sql hadoop从关系型数据库抽取到hive、或Habse里面做分析。或者将分析后的数据导出至关系型数据库做展示图表的操作。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/160954.html

