
1、ZAB协议处理
Zookeeper Automic Broadcast(ZAB),是paxos经典实现。
术语:quorum:集群过半数的集合
ZAB(zookeeper)中节点分三种状态:
looking:选举Leader的状态(崩溃恢复下)
following:跟随者(follower)的状态,服从Leader命令
leading:当前节点是Leader,负责协调工作。
observing:observer(观察者),不参与选举,只读节点。
ZAB中的两个模式:
崩溃恢复、消息广播

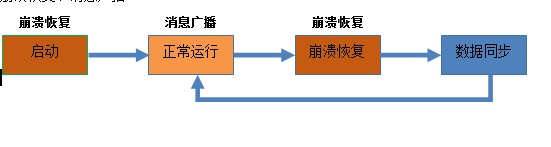
崩溃恢复:

1. 每个server都有一张选票<myid,zxid>,选票投自己。
2. 搜集各个服务器的投票。
3. 比较投票,比较逻辑:优先比较zxid,然后才比较myid。
4. 改变服务器状态(崩溃恢复=》数据同步,或者崩溃恢复=》消息广播)
epoch周期值
acceptedEpoch(比喻:年号):follower已经接受leader更改年好的(newepoch)提议。
currentEpoch(比喻:当前的年号):当前的年号
lastZxid:history中最近接收到的提议zxid(最大的值)
history:当前节点接受到事务提议的log
Zxid(64位的数据结构)
前32位:39000 Leader 周期编号 myid
低32位:0000f 事务的自增序列(单调递增的序列)只要客户端有请求,就+1
当产生新Leader的时候,就从这个Leader服务器上取出本地log中最大事务zxid,从里面读出epoch+1,作为一个新epoch,并将低32位置0(保证id绝对自增)。
消息广播(类似2P提交):

1. Leader接受请求后,讲这个请求赋予全局的唯一64位自增Id(zxid)。
2. 将zxid作为议案发给所有follower。
3. 所有的follower接受到议案后,想将议案写入硬盘后,马上回复Leader一个ACK(OK)。
4. 当Leader接受到合法数量Acks,Leader给所有follower发送commit命令。
5. follower执行commit命令。
ps:到了这个阶段,ZK集群才正式对外提供服务,并且Leader可以进行消息广播,如果有新节点加入,还需要进行同步。
数据同步:
1. 取出Leader最大lastZxid(从本地log日志来)
2. 找到对应zxid的数据,进行同步(数据同步过程保证所有follower一致)。
3. 只有满足quorum同步完成,准Leader才能成为真正的Leader。
个人总结:
崩溃恢复解说如下:
崩溃恢复的前提是剩余的节点数还在半数以上。接下来继续
客户端每一次请求创建,修改,删除 都会产生一个事务ID,每一个节点的事务ID不一样。因为每个客户端去连接的时候产生的一个编号ID ,上一篇文章解说过。此时,事务ID是一个自增长的,此时崩溃恢复的的时候需要选举,剩余节点哪一台作为Leader.(剩余节点事务ID最大的那一台节点有优先权)为什么有优先权,因为前文讲过,半数以上节点允许了后事务才让提交。那么半数上内的节点的事务是最大的,为了防止分布式数据丢失,此时的非事务ID最大的节点是没有优先权的。然后才是剩下的选择权。那个选择权随机算法都可以,只要节点可用即可了。
中间有多个状态的过渡:所有节点looking的时候,不提供对外事务提交服务,为了保证强一致性,zookeeper牺牲了部分可用性,就在此处提现出来了,当然如果无半数以上的可用服务,可用性同样也是停止的。一旦looking变更成 leading,fllowing之后,事务服务恢复。
新leading 选举出来后,首先做的事情就是从leading的log中取出事务日志,将数据同步到事务ID没有leading事务版本大的节点中。做完了这个然后才是做epoth的修改,这个东西倒是不那么重要。主要是要弄清楚基于paxos的ZAB算法的leading选举实现方案,并理解为什么zookeeper只是一个AP 型设计,非CP 型设计的各个方面间的联系,以及分布式事务关系到各个节点的数据稳定。
废话有点多,但是这个都是学习后的总结
2、Curator
curator连接ZK应用最广泛的工具。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/160961.html

