
文章目录
数据挖掘的五大流程包括:
- 获取数据
- 数据预处理
- 特征工程
- 建模
- 上线
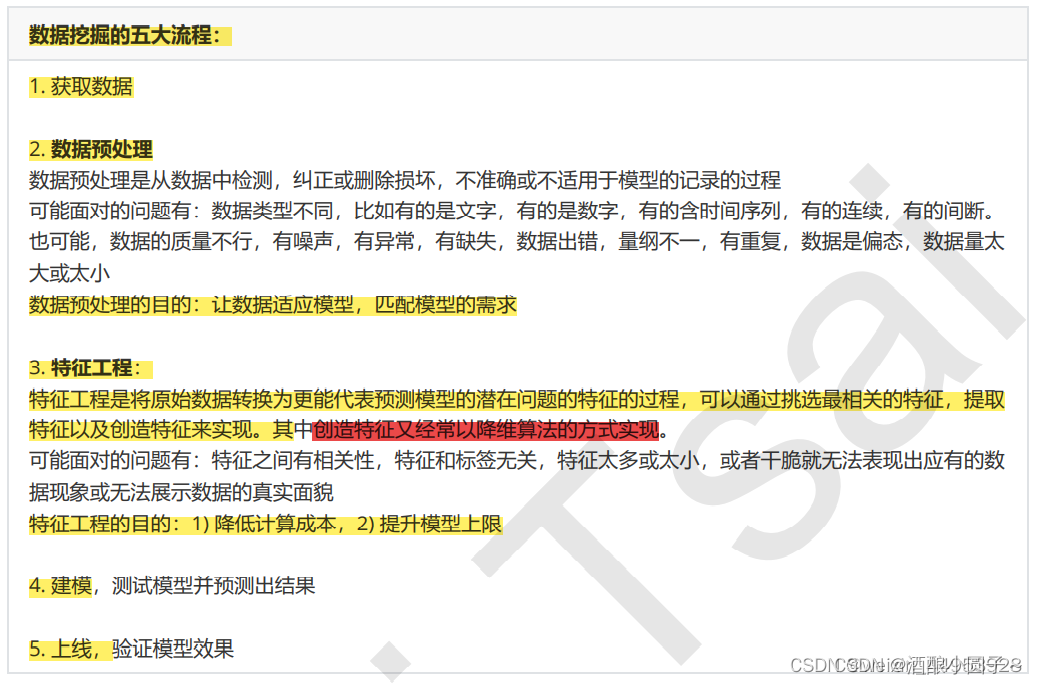
其中,数据预处理中常用的方法包括数据标准化和归一化。sklearn中包含众多的数据预处理模块,

- 模块preprocessing:几乎包含数据预处理的所有内容
- 模块Impute:填补缺失值专用
- 模块feature_selection:包含特征选择的各种方法的实践
- 模块decomposition:包含降维算法
1. 无量纲化
1.1 sklearn.preprocessing.MinMaxScaler
sklearn.preprocessing.MinMaxScaler(feature_range=(0, 1), copy=True)
1.2 sklearn.preprocessing.StandardScaler
sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True)
2. 缺失值
3. 分类型特征
4. 连续型特征
【参考博客】:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/162799.html

