
文章目录
1. 香农信息量
1.1 基本定义
如果是连续型随机变量的情况,设
p
p
p 为随机变量
X
X
X 的概率分布,即
p
(
x
)
p(x)
p(x) 为随机变量
X
X
X 在 $X = x $ 处的概率密度函数值,则随机变量
X
X
X 在
X
=
x
X = x
X=x 处的香农信息量定义为:
−
l
o
g
2
p
(
x
)
=
log
2
1
p
(
x
)
– {\rm{lo}}{{\rm{g}}_2}p(x) = {\log _2}\frac{1}{{p(x)}}
−log2p(x)=log2p(x)1
这时香农信息量的单位为比特。(如果非连续型随机变量,则为某一具体随机事件的概率,其他的同上)
1.2 具体含义
香农信息量用于刻画消除随机变量在处的不确定性所需的信息量的大小。
上面给出了香农信息量的完整而严谨的表达,基本上读完就只剩下一个问题,为什么是这个式子?为了方便理解我们先看一下香农信息量在数据压缩应用的一般流程。
(1) 数据压缩样例1
假设我们有一段数据长下面这样:
a
a
B
a
a
a
V
a
a
a
a
a
aaBaaaVaaaaa
aaBaaaVaaaaa
可以算出三个字母出现的概率分别为:
a
:
10
12
a : \frac{10}{12}
a:1210,
B
:
1
12
B : \frac{1}{12}
B:121,
V
:
1
12
V : \frac{1}{12}
V:121
香农信息量为:
a
:
0.263
a : 0.263
a:0.263 ,
B
:
3.585
B : 3.585
B:3.585 ,
V
:
3.585
V : 3.585
V:3.585
也就是说如果我们要用比特来表述这几个字母,分别需要 0.263 , 3.585 , 3.585 个这样的比特。当然,由于比特是整数的,因此应该向上取整,变为 1 , 4 , 4 个比特。
这个时候我们就可以按照这个指导对字母进行编码,比如把
a
a
a 编码为”0″,把
B
B
B 编码为”1000″,V 编码为”1001″,然后用编码替换掉字母来完成压缩编码,数据压缩结果为:001000000100100000。
上面例子看起来有点不合理,因为如果我们可以编码出不一样的东西,如
a
a
a 编码为”0″,B 编码为”10″,V 编码为”11″,因此可以把数据压缩的更小。那么问题出现在哪呢?
出现在这里的B和V这两个字母只用两个比特进行编码对于他们自身而言并不是充分的。在下面压缩的例子中,可以一下子就看出来
(2) 数据压缩样例2
假设新的数据长这样:
a
b
B
c
d
e
V
f
h
g
i
m
abBcdeVfhgim
abBcdeVfhgim
上面的每一个字母出现的概率都为
1
12
\frac{1}{12}
121,假设我们还是以两个比特去编码
B
B
B 和
V
V
V ,那么就无法完全区分出12个字母。而如果是4个比特,便有16种可能性,可以足够区分这12个字母。
现在回过头来看香农信息量的公式,它正是告诉我们:如果已经知道一个事件出现的概率,至少需要多少的比特数才能完整描绘这个事件(无论外部其他事件的概率怎么变化)。 其中为底的2就是比特的两种可能性,而因为二分是一个除的关系,因此自变量是概率分之一而不是概率本身。
感性的看,如果我们知道
a
a
a 出现的概率为
5
6
\frac{5}{6}
65 ,那么用比特中的”0″状态来表述它是完全合理的,因为其他事件的概率总和只有
1
6
\frac{1}{6}
61,但我们给这
1
6
\frac{1}{6}
61 空出了比特的”1″这
1
2
\frac{1}{2}
21 的空间来表达他们,是完全足够的。
【参考博客】:香农信息量:https://blog.csdn.net/weixinhum/article/details/85059320
2. 信息熵
2.1 基本定义
由香农信息量我们可以知道对于一个已知概率的事件,我们需要多少的数据量能完整地把它表达清楚,不与外界产生歧义。但对于整个系统而言,其实我们更加关心的是表达系统整体所需要的信息量。比如我们上面举例的
a
a
B
a
a
a
V
a
a
a
a
a
aaBaaaVaaaaa
aaBaaaVaaaaa 这段字母,虽然
B
B
B 和
V
V
V 的香农信息量比较大,但他们出现的次数明显要比
a
a
a 少很多,因此我们需要有一个方法来评估整体系统的信息量。
相信你可以很容易想到利用期望这个东西,因此评估的方法可以是:“事件香农信息量×事件概率”的累加。这也正是信息熵的概念。
H
(
X
)
=
−
∑
x
∈
χ
p
(
x
)
log
p
(
x
)
H(X) = – \sum\limits_{x \in \chi }^{} {p(x)\log p(x)}
H(X)=−x∈χ∑p(x)logp(x)
如
a
a
B
a
a
a
V
a
a
a
a
a
aaBaaaVaaaaa
aaBaaaVaaaaa 这段字母,信息熵为:
−
5
6
log
2
5
6
−
2
×
1
12
log
2
1
12
=
0.817
– \frac{5}{6}{\log _2}\frac{5}{6} – 2 \times \frac{1}{{12}}{\log _2}\frac{1}{{12}} = 0.817
−65log265−2×121log2121=0.817
a
b
B
c
d
e
V
f
h
g
i
m
abBcdeVfhgim
abBcdeVfhgim 这段字母,信息熵为:
−
12
×
1
12
log
2
1
12
=
3.585
– 12 \times \frac{1}{{12}}{\log _2}\frac{1}{{12}} = 3.585
−12×121log2121=3.585
从数值上可以很直观地看出,第二段字母信息量大,和观察相一致。
对于连续型随机变量,信息熵公式变为积分的形式,如下:
H
(
X
)
=
E
x
∼
p
(
x
)
[
−
log
p
(
x
)
]
=
−
∫
p
(
x
)
log
p
(
x
)
d
x
H(X) = {E_{x \sim p(x)}}[ – \log p(x)] = – \int {p(x)\log p(x)dx}
H(X)=Ex∼p(x)[−logp(x)]=−∫p(x)logp(x)dx
【参考博客】:信息熵:https://blog.csdn.net/weixinhum/article/details/85059557
2.2 基本性质
信息论之父克劳德·香农给出的信息熵的三个性质:
- 单调性,发生概率越高的事件,其携带的信息量越低;
- 非负性,信息熵可以看作为一种广度量,非负性是一种合理的必然;
- 累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和,这也是广度量的一种体现。
3. 两随机变量系统中熵的相关概念
3.1 互信息
3.2 联合熵
3.3 条件熵
3.4 互信息、联合熵、条件熵之间的关系
【参考博客】:信息熵及其相关概念:https://blog.csdn.net/am290333566/article/details/81187124
4. 两分布系统中熵的相关概念
4.1 交叉熵
考虑一种情况,对于一个样本集,存在两个概率分布
p
(
x
)
p(x)
p(x) 和
q
(
x
)
q(x)
q(x),其中
p
(
x
)
p(x)
p(x) 为真实分布,
q
(
x
)
q(x)
q(x) 为非真实分布。基于真实分布
p
(
x
)
p(x)
p(x) 我们可以计算这个样本集的信息熵也就是编码长度的期望为:
H
(
p
)
=
−
∑
x
p
(
x
)
log
p
(
x
)
H(p) = – \sum\limits_x {p(x)\log p(x)}
H(p)=−x∑p(x)logp(x)
回顾一下负对数项表征了所含的信息量,如果我们用非真实分布
q
(
x
)
q(x)
q(x) 来代表样本集的信息量的话,那么:
H
(
p
,
q
)
=
−
∑
x
p
(
x
)
log
q
(
x
)
H(p,q) = – \sum\limits_x {p(x)\log q(x)}
H(p,q)=−x∑p(x)logq(x)
因为其中表示信息量的项来自于非真实分布
q
(
x
)
q(x)
q(x) ,而对其期望值的计算采用的是真实分布
p
(
x
)
p(x)
p(x),所以称其为交叉熵 (Cross Entropy)。


从这个例子中,我们可以看到交叉熵比原本真实的信息熵要大。直观来看,当我们对分布估计不准确时,总会引入额外的不必要信息期望(可以理解为引入了额外的偏差),再加上原本真实的信息期望,最终的信息期望值要比真实系统分布所需的信息期望值要大。
4.2 相对熵
相对熵 (Relative Entropy) 也称 KL 散度。在信息论中,相对熵等价于两个概率分布的信息熵的差值,若其中一个概率分布为真实分布,另一个为理论(拟合)分布,则此时相对熵等于交叉熵与真实分布的信息熵之差,表示使用理论分布拟合真实分布时产生的信息损耗 。
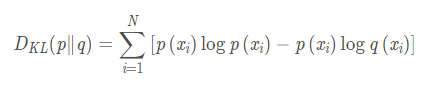
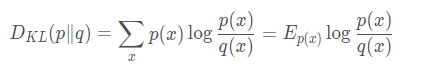
上面的
p
(
x
i
)
p ( x _i)
p(xi) 为真实事件的概率分布,
q
(
x
i
)
q ( x _i)
q(xi) 为理论拟合出来的该事件的概率分布。因此该公式的字面上含义就是真实事件的信息熵与理论拟合的事件的香农信息量与真实事件的概率的乘积的差的累加。
假设理论拟合出来的事件概率分布跟真实的一模一样,那么相对熵就等于真实事件的信息熵。假设拟合的不是特别好,那么相对熵会比真实事件的信息熵大(稍后证明)。

相对熵具有不对称的性质,举个例子,比如随机变量
X
∼
P
X \sim P
X∼P 取值为1,2,3时的概率分别为[0.1,0.4,0.5],随机变量
Y
∼
Q
Y \sim Q
Y∼Q 取值为1,2,3时的概率分别为[0.4,0.2,0.4],则:
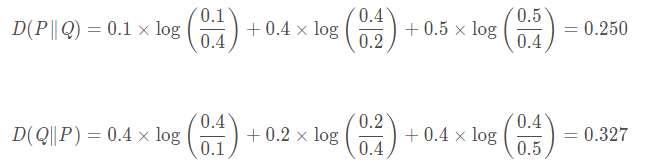
也就是说用
P
P
P 来拟合
Q
Q
Q 和用
Q
Q
Q 来拟合
P
P
P 的相对熵不一样。
4.3 相对熵与交叉熵的关系
对相对熵公式进一步变形为:

同时,也更容易的看出来相对熵表示的其实是当我们用一个非真实的分布表示系统时,其得到的信息量期望值相比采用真实分布表示时候多出的部分。
在机器学习中,训练数据的分布已经固定下来,那么真实分布的熵
H
(
p
)
H(p)
H(p) 是一个定值。最小化相对熵
D
K
L
(
P
∣
∣
q
)
{D_{KL}}(P||q)
DKL(P∣∣q) 等价于最小化交叉熵
H
(
p
,
q
)
H(p,q)
H(p,q)。
【参考博客】:信息熵及其相关概念:https://blog.csdn.net/am290333566/article/details/81187124
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/162834.html

