
1. Multi-Head Attention
当前最流行的Attention机制当属 Scaled-Dot Attention (源于 Attention Is All You Need) ,即:
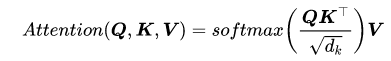
基于上述 Scaled-Dot Attention 下标准的 Multi-Head Attention 如下所示:

2. Talking-Heads Attention
近日,来自 Google 的研究团队提出一种「交谈注意力机制」(Talking-Heads Attention),在 softmax 操作前后引入对多头注意力之间的线性映射,以此增加多个注意力机制间的信息交流。这样的操作虽然增加了模型的计算复杂度,却能够在多项语言处理问题上取得更好的效果。
- 论文:Talking-Heads Attention
- 论文地址:https://arxiv.org/abs/2003.02436
2.1 基本原理
当前的Multi-Head Attention每个head的运算是相互孤立的,而通过将它们联系(Talking)起来,则可以得到更强的Attention设计

如上图,就是将多头注意力用一个参数矩阵重新融合成多个混合注意力。每个新的得到的混合注意力都融合了原先的各head注意力。
注:
1、这里省略了缩放因子 {d_k}^1/2
2、新生成的多个混合注意力可以多于原先的h
2.2 具体实现
- tensorflow官方实现 :https://github.com/tensorflow/models/tree/master/official/nlp/modeling/layers
- pytorch实现1:https://github.com/lucidrains/x-transformers
- pytorch实现2:https://github.com/lucidrains/En-transformer
【参考博客】:
- 注意力机制的改进:https://blog.csdn.net/zsycode/article/details/105811847
- Google | 突破瓶颈,打造更强大的Transformer:https://blog.csdn.net/xixiaoyaoww/article/details/105549150
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/162842.html

