
文章目录
日志对于系统开发的开发、调试和运行整个过程中都起着很重要的作用,调试阶段需要查看日志来明确问题所在,运行阶段如果程序崩溃,日志可以记录程序崩溃的相关原因。 刚初学Python的时候,想调试代码基本靠print, 导致项目代码多了之后,print也不知到具体是那部分的。而且print打印日志也不符合PEP8的规范,到调试成功后还得一行行地把print删除,所以logging标准库很好地解决了这个问题。
1. 日志的作用
通过记录日志,可以了解系统、程序的运行情况;某些情况下,日志还可以记录用户的操作行为、类型爱好等可以用来分析。日志可以在程序发现问题后让开发人员或运维人员快速定位问题所在。总而言是,日志在开发调试、定位故障、了解程序运行情况等方面发挥重要作用。
记录日志最简单正确的方式就是使用logging内置模块来实现。最简单一个例子如下:
import logging
# filename 指定日志存放文件,level 指定logging级别
logging.basicConfig(filename="out.log", level=logging.INFO)
logging.debug("hello, debug")
logging.info("hello, info")
logging.info("finsh, info")
运行结果如下:
INFO:root:hello, info
INFO:root:finsh, info
如上三行代码就可以把日志记录到文件中。
2. 日志的级别
有没有好奇为什么第一条logging没有存入日志文件中,这就和我们指定的level有关了,如下指定了日志的级别是INFO级别:
logging.basicConfig(filename="out.log", level=logging.INFO)
下面是logging模块的几种级别的含义和对应的权重:
| 日志级别 | 何时使用 |
|---|---|
| DEBUG | 详细信息,典型地调试问题时会感兴趣。 |
| INFO | 证明事情按预期工作。 |
| WARNING | 表明发生了一些意外,或者不久的将来会发生问题(如‘磁盘满了’)。软件还是在正常工作。 |
| ERROR | 由于更严重的问题,软件已不能执行一些功能了。 |
| CRITICAL | 严重错误,表明软件已不能继续运行了。 |
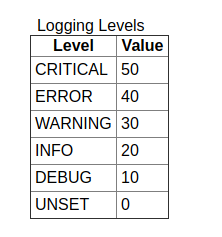
从图中就可以解释为什么上面第一条logging没有记录到日志文件中了,因为INFO的级别比DEBUG大,而日志记录只会记录级别比INFO大或相等级别的日志。也就是说我们可以自己控制消息的级别,来保证重要的消息显示,或者说过滤掉一些不重要的日志,而且你还可以决定输出到哪里,输出的格式等等。
不同等级一般适用于不同的用途,比如开发环境中,我们需要调试程序,通常需要看到具体详细的日志信息来定位问题;而生产环境中,我们就不需要太过于详细的日志,一般只需要异常、错误等级的日志信息,这样避免日志文件很大导致定位问题难,还可以减轻服务器的IO压力。
3. 几个重要的概念
3.1 Logger 记录器
Logger是一个树形层级结构,在使用接口debug,info,warn,error,critical之前必须创建Logger实例,即创建一个记录器,如果没有显式的进行创建,则默认创建一个root logger,并应用默认的日志级别(WARN),处理器Handler(StreamHandler,即将日志信息打印输出在标准输出上),和格式化器Formatter(默认的格式即为第一个简单使用程序中输出的格式)。
创建方法:
logger = logging.getLogger(logger_name)
创建Logger实例后,可以使用以下方法进行日志级别设置,增加处理器Handler。
- logger.setLevel(logging.ERROR) # 设置日志级别为ERROR,即只有日志级别大于等于ERROR的日志才会输出
- logger.addHandler(handler_name) # 为Logger实例增加一个处理器
- logger.removeHandler(handler_name) # 为Logger实例删除一个处理器
3.2 Handler 处理器
Handler处理器类型有很多种,比较常用的有三个,StreamHandler,FileHandler,NullHandler。
创建StreamHandler之后,可以通过使用以下方法设置日志级别,设置格式化器Formatter,增加或删除过滤器Filter。
- ch.setLevel(logging.WARN) # 指定日志级别,低于WARN级别的日志将被忽略
- ch.setFormatter(formatter_name) # 设置一个格式化器formatter
- ch.addFilter(filter_name) # 增加一个过滤器,可以增加多个
- ch.removeFilter(filter_name) # 删除一个过滤器
(1) StreamHandler
创建方法:
sh = logging.StreamHandler(stream=None)
(2) FileHandler
创建方法:
fh = logging.FileHandler(filename, mode='a', encoding=None, delay=False)
(3) NullHandler
NullHandler类位于核心logging包,不做任何的格式化或者输出。
本质上它是个“什么都不做”的handler,由库开发者使用。
3.3 Formatter 格式化器
使用Formatter对象设置日志信息最后的规则、结构和内容,默认的时间格式为%Y-%m-%d %H:%M:%S。
创建方法:
formatter = logging.Formatter(fmt=None, datefmt=None)
其中,fmt是消息的格式化字符串,datefmt是日期字符串。如果不指明fmt,将使用’%(message)s’。如果不指明datefmt,将使用ISO8601日期格式。
3.4 Filter 过滤器
Handlers和Loggers可以使用Filters来完成比级别更复杂的过滤。Filter基类只允许特定Logger层次以下的事件。例如用‘A.B’初始化的Filter允许Logger ‘A.B’, ‘A.B.C’, ‘A.B.C.D’, ‘A.B.D’等记录的事件,logger‘A.BB’, ‘B.A.B’ 等就不行。 如果用空字符串来初始化,所有的事件都接受。
创建方法:
filter = logging.Filter(name='')
4. 常见示例
4.1 常见示例1:Logging日志记录
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# 创建 handler 输出到文件
file_handler = logging.FileHandler("file.log", mode='w') # 一定要加上 mode='w'
file_handler.setLevel(logging.INFO)
# handler 输出到控制台
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.DEBUG)
# 创建 logging format
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
file_handler.setFormatter(formatter)
console_handler.setFormatter(formatter)
# add the handlers to the logger
logger.addHandler(file_handler)
logger.addHandler(console_handler)
logger.info("hello, logging")
logger.debug("print to debug")
logger.error("error logging")
logger.warning("warning logging")
logger.critical("critical logging")
运行结果如下:
2018-04-11 09:30:25,354 - __main__ - INFO - hello, logging
2018-04-11 09:30:25,354 - __main__ - ERROR - error logging
2018-04-11 09:30:25,354 - __main__ - WARNING - warning logging
2018-04-11 09:30:25,354 - __main__ - CRITICAL - critical logging
注:logger对象名称:
这里 name 作为logger对象名称;还有上面例子中getLogger(name)里面的__name__是什么作用呢?
其实,logger对象名字的层级和python包的层级是相似的,并且如果你使用推荐的结构logging.getLogger(name)来管理你的loggers对象的话,那就与python包的层级结构是一模一样的。因为在一个模块中__name__是一个在python包中名字空间的模块的名称。
例如,你在模块 foo.bar.my_module 里调用 logging.getLogger(name),那么其实等价于 logging.getLogger(‘foo.bar.my_module’)。这样做的目的是,你设置logger时候指定了foo包后,该包下的所有模块日志都是使用同一logger的配置,方便后期日志查看时清楚是那个模块的记录。
4.2 常见示例2 :函数化示例 (避免重复日志)
def get_logger(log_dir, name, log_filename='info.log', level=logging.INFO):
try:
os.makedirs(log_dir)
except OSError:
pass
logger = logging.getLogger(name)
logger.setLevel(level)
# Create logging format
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
if not logger.handlers: # 避免重复日志
# Add file handler
file_handler = logging.FileHandler(os.path.join(log_dir, log_filename), mode='w')
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
# Add console handler
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(formatter)
logger.addHandler(console_handler)
logger.info('Log directory: %s', log_dir)
return logger
问题: 代码运行过程中,发现日志内容出现很多重复,使得日志内容很臃肿,影响日志内容查看!
原因: 之所以出现这个问题的原因在于代码里面多个地方都调用了 logger = get_logger()
每次调用getLogger(),都会添加一个FileHandler,多次调用,就会添加多个FileHandler。有多少个FileHandler ,就会在需要记录日志的地方,重复打印多少次的日志内容。
解决方案:
由此看来,解决办法有两个:
(1) 每次记录了日志内容之后,就把这个filehandler移除。
msg = "xxxxxx"
logger = get_logger()
logger.info(msg)
logger.removeHandler(FileHandler)
(2) 每次调用getLogger()函数,添加filehandler之前,判断一下是否已经存在filehandler,如果存在则不继续添加,这样就不会出现多次添加handler的情况。
# 判断一下是否已经存在filehandler, 避免重复日志
if not logger.handlers:
# Add file handler
file_handler = logging.FileHandler(os.path.join(log_dir, log_filename), mode='w')
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
# Add console handler
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(formatter)
logger.addHandler(console_handler)
参考博客: python之logging日志重复输出问题: http://blog.sina.com.cn/s/blog_a1e9c7910102z4p3.html
4.3 多进程环境下往同一个文件写日志
在使用 Gunicorn 使用多线程往同一个文件写日志时,发现日志存在以下问题:
- 时间顺序混乱
- 部分日志内容丢失
经过查阅文档发现:
按照官方文档的介绍,logging 是线程安全的,也就是说,在一个进程内的多个线程同时往同一个文件写日志是安全的。但是(对,这里有个但是)多个进程往同一个文件写日志不是安全的。
【解决办法】:多进程环境python logging打印日志混乱问题
logging.basicConfig(level=logging.INFO,
format='[%(asctime)s] p%(process)s {%(name)-12s:%(lineno)d} %(levelname)-8s - %(message)s',
datefmt='%m-%d %H:%M',
filename='taobao.log',
filemode='a') # 注意此处用'a'而不是'w'
file_handler = logging.FileHandler(os.path.join(log_dir, log_filename), mode='a') #注意此处用'a'而不是'w'
fileMode:表示日志文件的打开方式。filemode=‘a’ # 注意此处用’a’而不是’w’。
- w-直接写,使用这个配置当系统重启的时候日志会清空,一个进程打开后其他进程是无法使用的;
- a-尾部追加,大家都可以打开往文件结尾进行追加写入。
【参考博客】:
- python logging模块使用教程: https://www.jianshu.com/p/feb86c06c4f4
- Python日志最佳实践: https://www.jianshu.com/p/c7850ac01362
- 【踩坑记录】记录一次使用Python logging库多进程打印日志的填坑过程: https://www.cnblogs.com/longweiqiang/p/12156288.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/162845.html

