
参考博客:https://blog.csdn.net/winycg/article/details/88937583
LSTM(Long Short Term Memory),长短时记忆网络,主要用于传统RNN网络所面临的梯度消失/爆炸等问题。关于LSTM的基本原理可以参考我的另外一篇博客:RNN神经网络
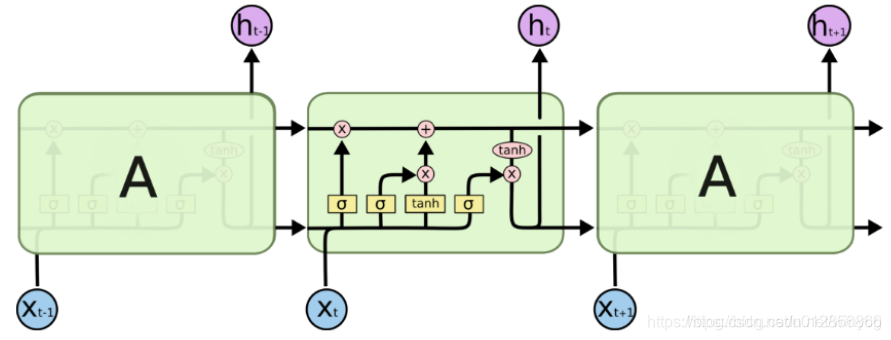

nn.LSTM
LSTM实现MNIST分类
MNIST图片大小为28×28,可以将每张图片看做是长为28的序列,序列中每个元素的特征维度为28。将最后输出的隐藏状态
h
T
h_T
hT作为抽象的隐藏特征输入到全连接层进行分类。
导入基础包
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import transforms
定义网络结构
class Rnn(nn.Module):
def __init__(self, in_dim, hidden_dim, n_layer, n_classes):
super(Rnn, self).__init__()
self.n_layer = n_layer
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(in_dim, hidden_dim, n_layer, batch_first=True)
self.classifier = nn.Linear(hidden_dim, n_classes)
def forward(self, x):
out, (h_n, c_n) = self.lstm(x)
# 此时可以从out中获得最终输出的状态h
# x = out[:, -1, :]
x = h_n[-1, :, :]
x = self.classifier(x)
return x
训练和测试
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False)
net = Rnn(28, 10, 2, 10)
net = net.to('cpu')
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9)
# Training
def train(epoch):
print('\nEpoch: %d' % epoch)
net.train()
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to('cpu'), targets.to('cpu')
optimizer.zero_grad()
outputs = net(torch.squeeze(inputs, 1))
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print(batch_idx, len(trainloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (train_loss/(batch_idx+1), 100.*correct/total, correct, total))
def test(epoch):
global best_acc
net.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
inputs, targets = inputs.to('cpu'), targets.to('cpu')
outputs = net(torch.squeeze(inputs, 1))
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print(batch_idx, len(testloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (test_loss/(batch_idx+1), 100.*correct/total, correct, total))
for epoch in range(200):
train(epoch)
test(epoch)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/162887.html

