
文章目录
GCN结合邻近节点特征的方式和图的结构依依相关,这也给GCN带来了几个问题:
- 无法完成inductive任务,即处理动态图问题。inductive任务是指:训练阶段与测试阶段需要处理的graph不同。通常是训练阶段只是在子图(subgraph)上进行,测试阶段需要处理未知的顶点。(unseen node)
- 处理有向图的瓶颈,不容易实现分配不同的学习权重给不同的neighbor。
于是,Bengio等人在ICLR 2018上提出了图注意力(GAT)模型,论文详见:Graph Attention Networks
1. GAT基本原理

结合上图,GAT的核心思想就是针对节点
i
i
i和节点
j
j
j , GAT首先学习了他们之间的注意力权重
a
i
,
j
a_{i,j}
ai,j(如左图所示);然后,基于注意力权重
{
a
1
,
.
.
.
,
a
6
}
\{a_1, … , a_6\}
{a1,...,a6}来对节点
{
1
,
2
,
.
.
.
,
6
}
\{1, 2, … ,6\}
{1,2,...,6}的表示
{
h
1
,
.
.
.
,
h
6
}
\{h_1, … , h_6\}
{h1,...,h6}加权平均,进而得到节点1的表示
h
1
′
{h}’_1
h1′ 。
和所有的attention mechanism一样,GAT的计算也分为两步走:
1.1 计算注意力系数(attention coefficient)
对于顶点
i
i
i ,逐个计算它的邻居们和它自己之间的相似系数
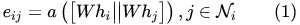
解读一下这个公式:
- 首先一个共享参数
W
W
W的线性映射对于顶点的特征进行了增维,当然这是一种常见的特征增强(feature augment)方法;
∣
∣
||
∣∣对于顶点
i
,
j
i, j
i,j 的变换后的特征进行了拼接(concatenate);
- 最后
a
(
)
a()
a() 把拼接后的高维特征映射到一个实数上。
显然学习顶点
i
,
j
i, j
i,j 之间的相关性,就是通过可学习的参数
W
W
W 和映射
a
(
)
a()
a() 完成的。
有了相关系数,离注意力系数就差归一化了!其实就是用个softmax
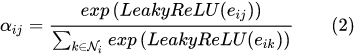
1.2 特征加权求和(aggregate)
第二步很简单,根据计算好的注意力系数,把特征加权求和(aggregate)一下。
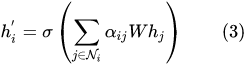
h
i
′
{h}’_i
hi′ 就是GAT输出的对于每个顶点
i
i
i 的新特征(融合了邻域信息)。
1.3 multi-head attention
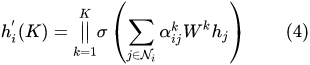
multi-head attention也可以理解成用了ensemble的方法。
关于GAT的解读,推荐下面几篇文章:
2. GAT实现代码
GAT实现代码Github地址:Pytorch | Tensorflow | Keras
PyTorch版代码解析:
- https://www.jianshu.com/p/7a397ca90895
- https://blog.csdn.net/weixin_36474809/article/details/89350573
Tensorflow版代码解析:
- 我的另外一篇博客:Graph Attention Network (GAT) 的Tensorflow版代码解析
- https://blog.csdn.net/karroyan/article/details/100318072
- https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/105548217
- https://blog.csdn.net/lyd1995/article/details/98451367
3. GAT和GCN优缺点对比
3.1 GCN缺点
-
GCN模型对于同阶的邻域上分配给不同的邻居的权重是完全相同的(也就是GAT论文里说的:无法允许为邻居中的不同节点指定不同的权重)。这一点限制了模型对于空间信息的相关性的捕捉能力,这也是在很多任务上不如GAT的根本原因。
-
GCN结合临近节点特征的方式和图的结构依依相关,这局限了训练所得模型在其他图结构上的泛化能力。
Graph Attention Network(GAT)提出了用注意力机制对邻近节点特征加权求和。 邻近节点特征的权重完全取决于节点特征,独立于图结构。GAT和GCN的核心区别在于如何收集并累和距离为1的邻居节点的特征表示。 图注意力模型GAT用注意力机制替代了GCN中固定的标准化操作。本质上,GAT只是将原本GCN的标准化函数替换为使用注意力权重的邻居节点特征聚合函数。
3.2 GAT优点
-
在GAT中,图中的每个节点可以根据邻节点的特征,为其分配不同的权值。
-
GAT的另一个优点在于,引入注意力机制之后,只与相邻节点有关,即共享边的节点有关,无需得到整张图的信息:(1)该图不需要是无向的(如果边缘 j->i 不存在,我们可以简单地省略计算
a
i
j
a_{ij}
aij;(2)它使我们的技术直接适用于Inductive Learning——包括在训练期间完全看不见的图形上的评估模型的任务。
参考博客:【图结构】之图注意力网络GAT详解以及GAT的推广:https://www.jianshu.com/p/d5d366ba1a57
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/162890.html

