
文章目录
1、如何对贵州茅台的股权进行穿透研究
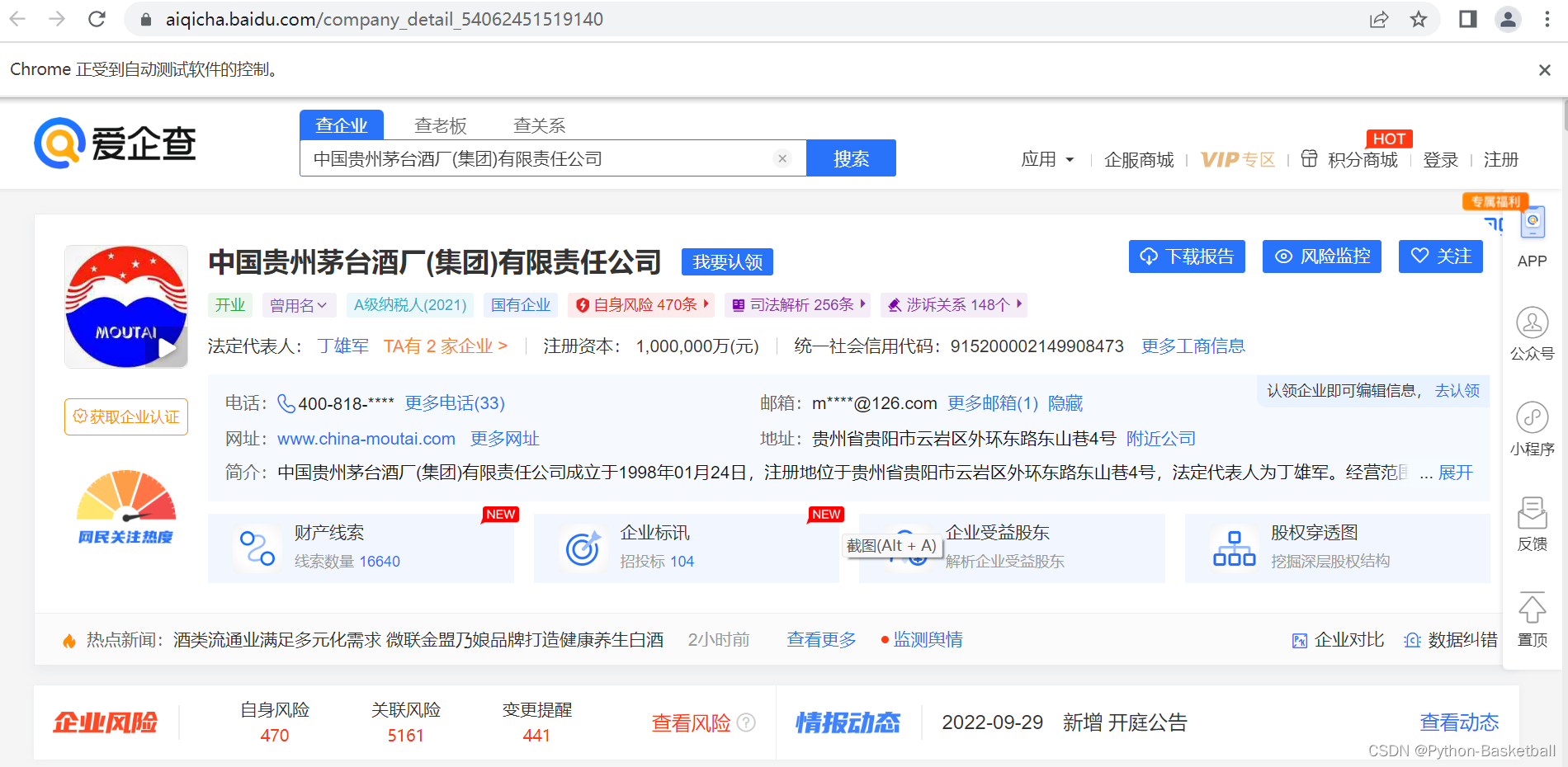
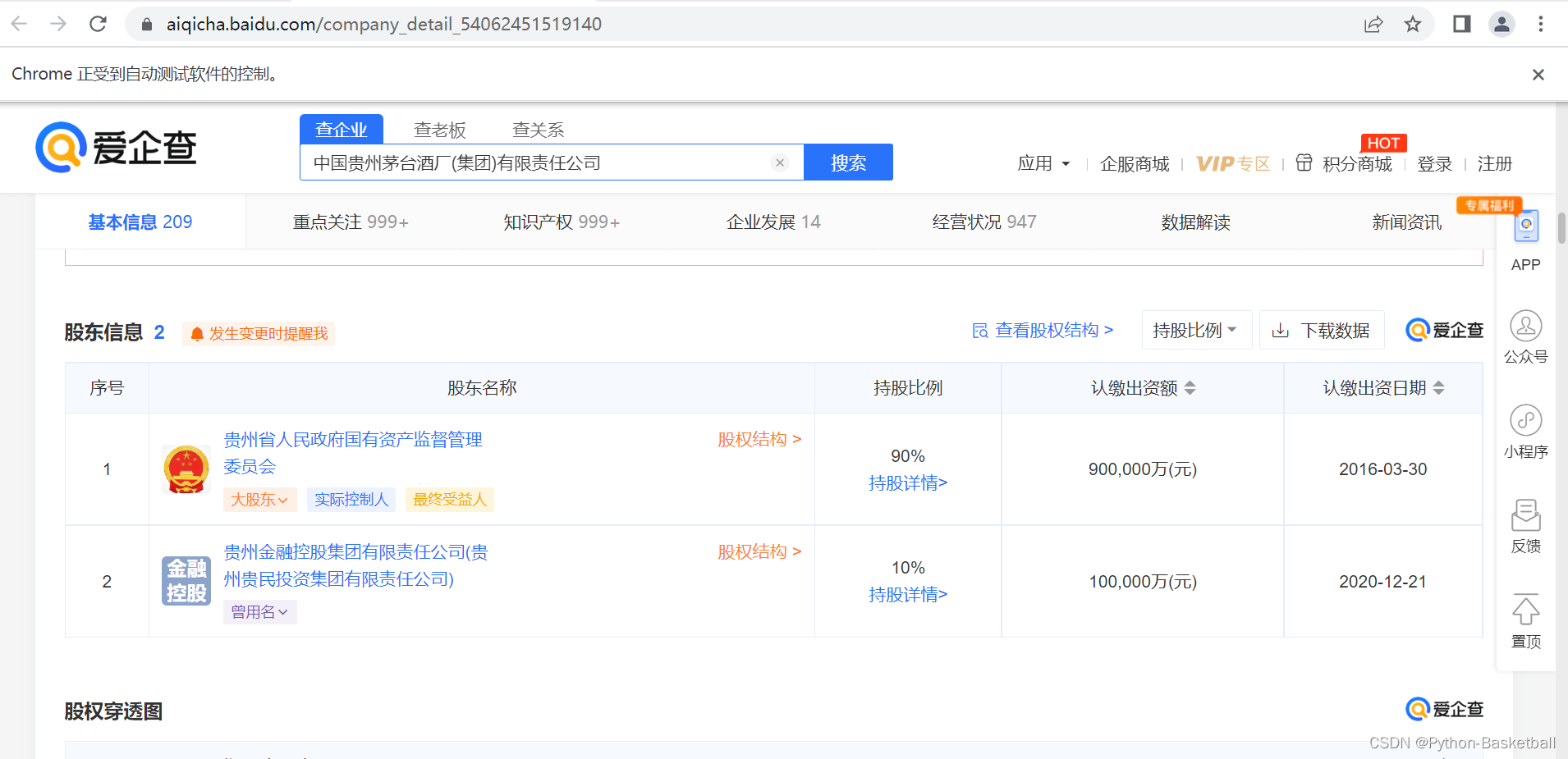
今天就来讲讲如何对贵州茅台股权进行研究
2、茅台股权穿透研究代码如下
#!/usr/bin/env python
# coding: utf-8
# In[1]:
from selenium import webdriver
import re
import time
import pandas as pd
# In[2]:
company_name = '华能信托'
browser = webdriver.Chrome()
url = 'https://xin.baidu.com/s?q=' + company_name
browser.get(url)
data = browser.page_source
print(data)
# In[3]:
p_href = '<h3 data-v-4dc1d36e="" class="title"><a data-v-4dc1d36e="" target="_blank" href="(.*?)"'
href = re.findall(p_href, data)
url2 = 'https://xin.baidu.com' + href[0]
browser.get(url2)
data = browser.page_source
# In[5]:
table = pd.read_html(data)
df = table[1]
df
# In[7]:
company = df['发起人/股东'][1]
company
# In[12]:
company_split = company.split(' ')
company_split
# In[14]:
company = df['发起人/股东'][0]
company_split = company.split(' ')
for i in company_split:
if '有限公司' in i:
print(i)
# In[13]:
company = df['发起人/股东'][0]
company_split = company.split(' ')
for i in company_split:
if len(i) > 6:
print(i)
# In[15]:
def baidu(company_name):
browser = webdriver.Chrome()
url = 'https://xin.baidu.com/s?q=' + company_name
browser.get(url)
time.sleep(2) # 休息2秒,防止页面没加载完
data = browser.page_source
p_href = '<h3 data-v-4dc1d36e="" class="title"><a data-v-4dc1d36e="" target="_blank" href="(.*?)"'
href = re.findall(p_href, data)
url2 = 'https://xin.baidu.com' + href[0]
browser.get(url2)
time.sleep(2) # 休息2秒,防止页面没加载完
data = browser.page_source
table = pd.read_html(data)
df = table[1]
browser.quit() # 退出模拟浏览器
company = df['发起人/股东'][0]
company_split = company.split(' ')
for i in company_split:
if len(i) > 6: # 不要用if '有限公司' in i,这个不太好,例如国资委不含有“有限公司 ”字样
return i
# In[16]:
baidu('中国华能集团有限公司')
# In[17]:
company_1 = baidu('华能信托')
company_2 = baidu(company_1)
company_3 = baidu(company_2)
# In[18]:
company_1, company_2, company_3
# In[ ]:
# In[ ]:
# In[19]:
company = '贵州茅台'
while True:
try:
company = baidu(company)
print(company)
except:
break
company
# In[ ]:
# In[ ]:
# In[38]:
num_sum = 0.0
num = 0
for i in df['持股比例']:
if i == '-':
num = 1
break
i = float(i[0:-1]) # 清除百分号,并转为浮点数
print(i)
num_sum = i + num_sum
num += 1
if num_sum > 80:
break
print(num)
# In[17]:
for i in range(num):
company_i = df['发起人/股东'][i]
company_split = company_i.split(' ')
for j in company_split:
if '有限公司' in j:
print(j)
# In[ ]:
# In[ ]:
执行过程中发现报错:
"app": "universe", // 调用方端内 APP 类型:iOS/Android/universe,非端内传 universe
"ver": "", // app版本号
}
xaf.init(initParams);
} catch(e) {
console.log(e);
}</script> <script src="//xinpub.cdn.bcebos.com/aiqicha/static/1667908976/js/s.031a6934a4e.js"></script> </body></html>
Traceback (most recent call last):
File "E:/tech/SufferSpace/股权穿透研究-1110.py", line 29, in <module>
url2 = 'https://xin.baidu.com' + href[0]
IndexError: list index out of range
Process finished with exit code 1
3、发现在29行代码出现问题,就是href取得是空数组,怀疑是p_href的问题
于是通过网页发现应该是这个地址:
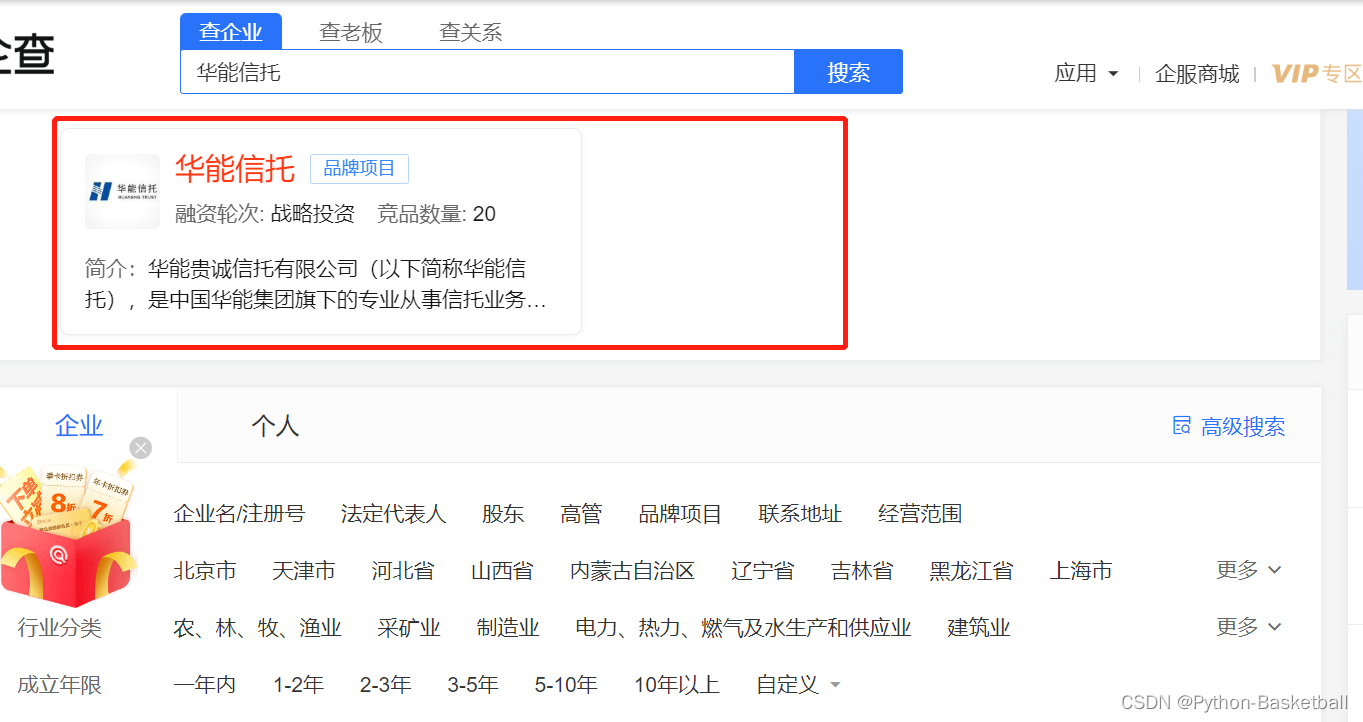
但是等到执行后面的代码,发现有个“发起人/股东”,因为按照上面这个地址,在这个页面中:https://aiqicha.baidu.com/brand/detail?pid=65781811851309&id=414444999
4、取不到股东信息,所以再仔细查看应该是下面这个第一个地址:
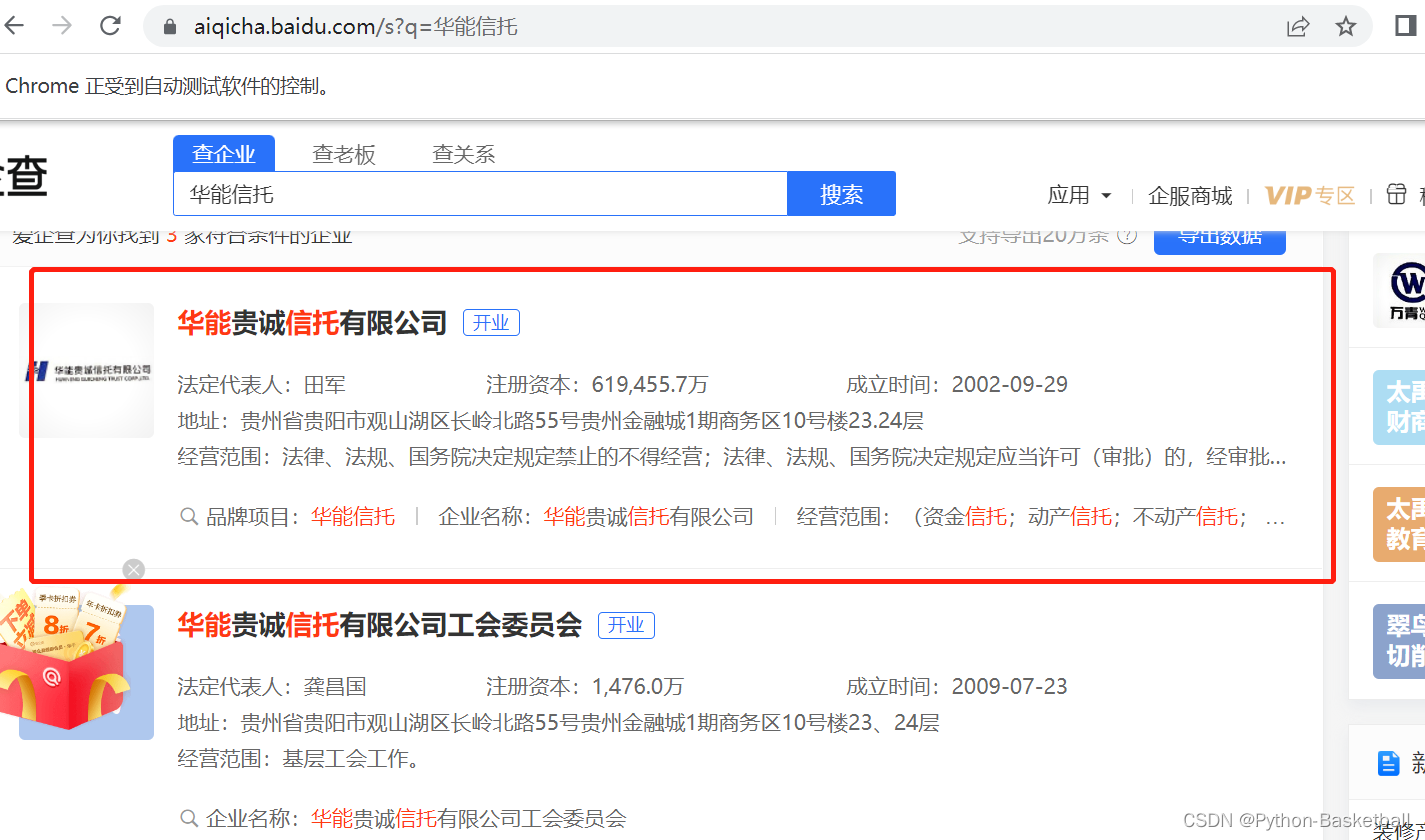
通过网址:https://aiqicha.baidu.com/company_detail_65781811851309
修改匹配逻辑如下:
p_href = '<h3 data-v-387da8b0="" class="title"><a data-v-387da8b0="" target="_blank" href="(.*?)"'
#p_href = '<a data-v-05558e48="" href="(.*?)" data-log-an="s-brandpanel" data-log-title="s-brandpanel-brand" class="item-inner">'
href = re.findall(p_href, data)
# https://aiqicha.baidu.com/brand/detail?pid=65781811851309&id=414444999
url2 = 'https://xin.baidu.com' + href[0]
#url2 = "https://aiqicha.baidu.com/company_detail_65781811851309"
browser.get(url2)
time.sleep(3)
data = browser.page_source
5、这里注意要加sleep,要不然有时候容易报错,找不到网页元素
time.sleep(3)
修改完后继续执行代码,又报错了
raise KeyError(key) from err
KeyError: '发起人/股东'
Process finished with exit code 1
找不到“发起人/股东”,查看网页,确实没有这个,应该是“股东名称”
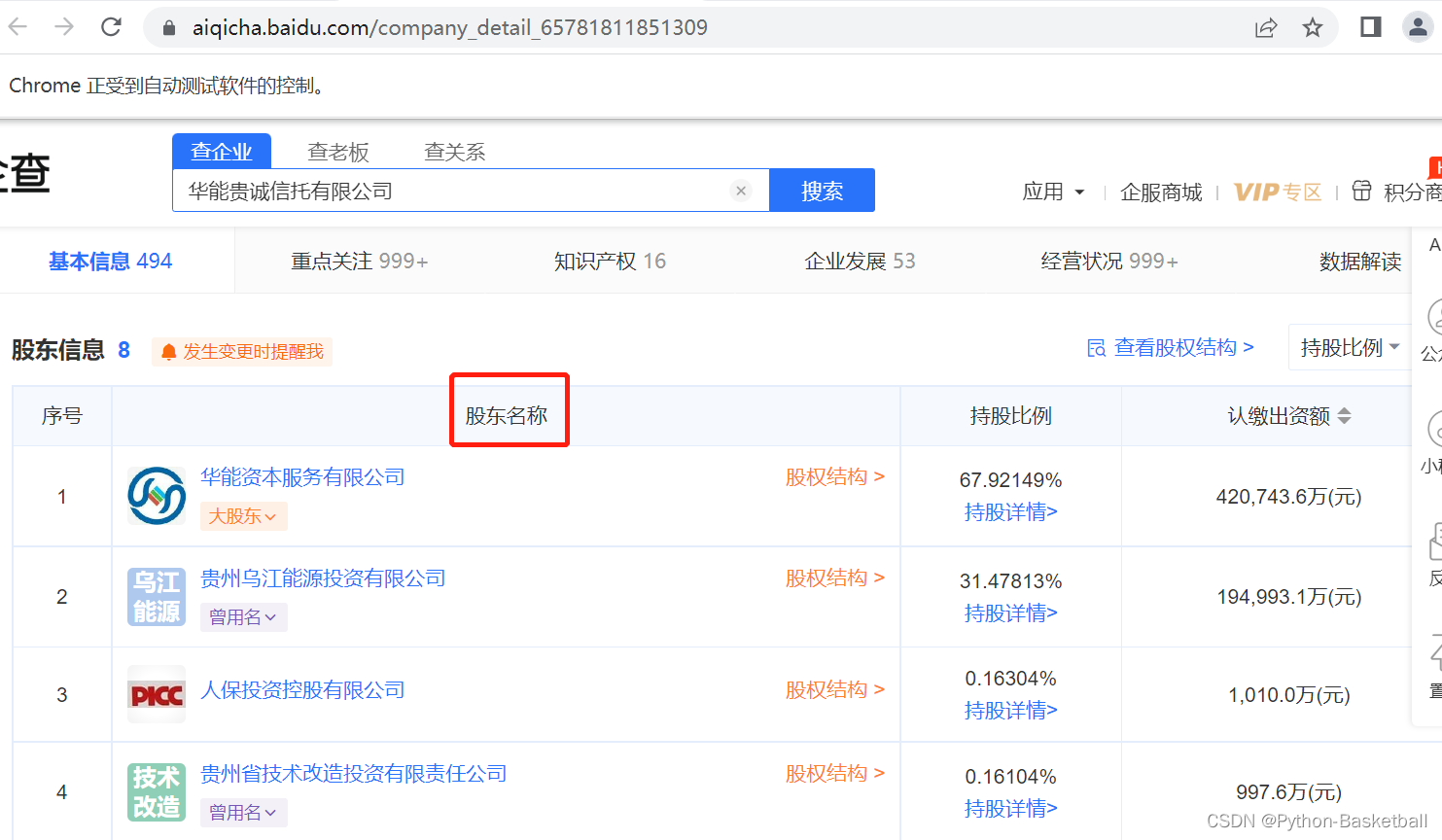
修改完后,继续执行代码,又报错了:
i = float(i[0:-1]) # 清除百分号,并转为浮点数
ValueError: could not convert string to float: '67.92149%持股详情'
Process finished with exit code 1
6、你知道i[0:-1]是什么意思吗?
a = [0,1,2,3,4,5,6,7,8,9]
b = a[i:j] 表示复制a[i]到a[j-1],以生成新的list对象
b = a[1:3] 那么,b的内容是 [1,2]
当i缺省时,默认为0,即 a[:3]相当于 a[0:3]
当j缺省时,默认为len(alist), 即a[1:]相当于a[1:10]
a[:-1]其实就是去除了这行文本的最后一个字符(换行符)后剩下的部分 ,结果是:[0,1,2,3,4,5,6,7,8]
A = ”67.92149%持股详情>“,这个字符,要取出纯数字,就是:
A[0:-6],-6正好是%的那个位置,然后修改代码如下:
num_sum = 0.0
num = 0
for i in df['持股比例']:
if i == '-':
num = 1
break
i = float(i[0:-6]) # 清除百分号,并转为浮点数
print(i)
num_sum = i + num_sum
num += 1
if num_sum > 80:
break
print(num)
最后执行结果如下:
华能资本服务有限公司
华能资本服务有限公司
贵州省人民政府国有资产监督管理委员会
67.92149
31.47813
2
华能资本服务有限公司
贵州乌江能源投资有限公司
Process finished with exit code 0
7、华能信托和贵州茅台股权穿透研究完整代码:
#!/usr/bin/env python
# coding: utf-8
# In[1]:
from selenium import webdriver
import re
import time
import pandas as pd
# In[2]:
company_name = '华能信托'
browser = webdriver.Chrome()
url = 'https://xin.baidu.com/s?q=' + company_name
browser.get(url)
time.sleep(3)
data = browser.page_source
print(data)
# In[3]:
p_href = '<h3 data-v-387da8b0="" class="title"><a data-v-387da8b0="" target="_blank" href="(.*?)"'
href = re.findall(p_href, data)
url2 = 'https://xin.baidu.com' + href[0]
browser.get(url2)
time.sleep(3)
data = browser.page_source
# In[5]:
table = pd.read_html(data)
df = table[1]
df
# In[7]:
company = df['股东名称'][1]
company
# In[12]:
company_split = company.split(' ')
company_split
# In[14]:
company = df['股东名称'][0]
company_split = company.split(' ')
for i in company_split:
if '有限公司' in i:
print(i)
# In[13]:
company = df['股东名称'][0]
company_split = company.split(' ')
for i in company_split:
if len(i) > 6:
print(i)
# In[15]:
def baidu(company_name):
browser = webdriver.Chrome()
url = 'https://xin.baidu.com/s?q=' + company_name
browser.get(url)
time.sleep(2) # 休息2秒,防止页面没加载完
data = browser.page_source
p_href = '<h3 data-v-387da8b0="" class="title"><a data-v-387da8b0="" target="_blank" href="(.*?)"'
href = re.findall(p_href, data)
url2 = 'https://xin.baidu.com' + href[0]
browser.get(url2)
time.sleep(2) # 休息2秒,防止页面没加载完
data = browser.page_source
table = pd.read_html(data)
df = table[1]
browser.quit() # 退出模拟浏览器
company = df['股东名称'][0]
company_split = company.split(' ')
for i in company_split:
if len(i) > 6: # 不要用if '有限公司' in i,这个不太好,例如国资委不含有“有限公司 ”字样
return i
# In[16]:
baidu('中国华能集团有限公司')
# In[17]:
company_1 = baidu('华能信托')
company_2 = baidu(company_1)
company_3 = baidu(company_2)
# In[18]:
company_1, company_2, company_3
# In[ ]:
# In[ ]:
# In[19]:
company = '贵州茅台'
while True:
try:
company = baidu(company)
print(company)
except:
break
company
# In[ ]:
# In[ ]:
# In[38]:
num_sum = 0.0
num = 0
for i in df['持股比例']:
if i == '-':
num = 1
break
i = float(i[0:-6]) # 清除百分号,并转为浮点数
print(i)
num_sum = i + num_sum
num += 1
if num_sum > 80:
break
print(num)
# In[17]:
for i in range(num):
company_i = df['股东名称'][i]
company_split = company_i.split(' ')
for j in company_split:
if '有限公司' in j:
print(j)
# In[ ]:
# In[ ]:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/164005.html

