
目录
引出
1.树的出现:解决链表线性访问时间太慢,树的时间复杂度O(logN);
2.二叉树的定义,最多两个儿子节点;
3.二叉查找树,左小,右大,中居中;remove方法,两种,只有一个儿子节点,有两个儿子节点;
4.AVL树,在二叉查找树基础上加平衡条件,旋转方法,单旋转,双旋转;
5.树的遍历方式,中序遍历,左根右;后续遍历,左右根;先序遍历,根左右;
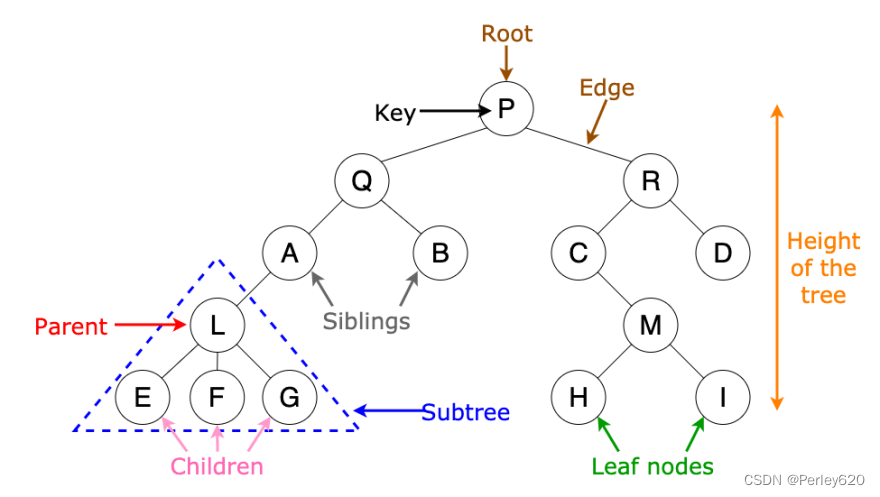
什么是树Tree?
对于大量的输入数据,链表的线性访问时间太慢,不宜使用。本章讨论一种简单的数据结构,其大部分操作的运行时间平均为O(logN)。
这种数据结构叫作二叉查找树(binary search tree)。二又查找树是两种库集合类TreeSet和TreeMap实现的基础,它们用于许多应用之中。在计算机科学中树(tree)是非常有用的抽象概念,因此,我们将讨论树在其他更一般的应用中的使用。
- 看到树是如何用于实现几个流行的操作系统中的文件系统的。
- 看到树如何能够用来计算算术表达式的值。
- 指出如何利用树支持以O(logN)平均时间进行的各种搜索操作,以及如何细化以得到最
坏情况时间界O(logN)。我们还将讨论当数据被存放在磁盘上时如何来实现这些操作。 - 讨论并使用TreeSet类和TreeMap类。
树(Tree)可以用几种方式定义。定义树的一种自然的方式是递归的方式。一棵树是一些节点的集合。这个集合可以是空集;若不是空集,则树由称作根 (root) 的节点 r 以及0个或多个非空的(子)树 T1,T2,…,Tk 组成,这些子树中每一棵的根都被来自根r的一条有向的边(edge)所连结。
每一棵子树的根叫作根r的儿子(child),而r是每一棵子树的根的父亲(parent)。
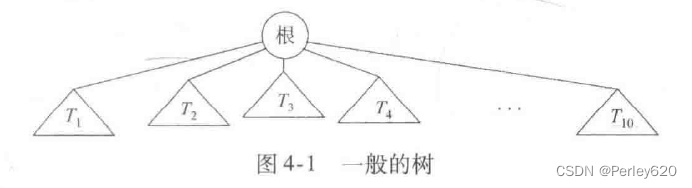
树的实现
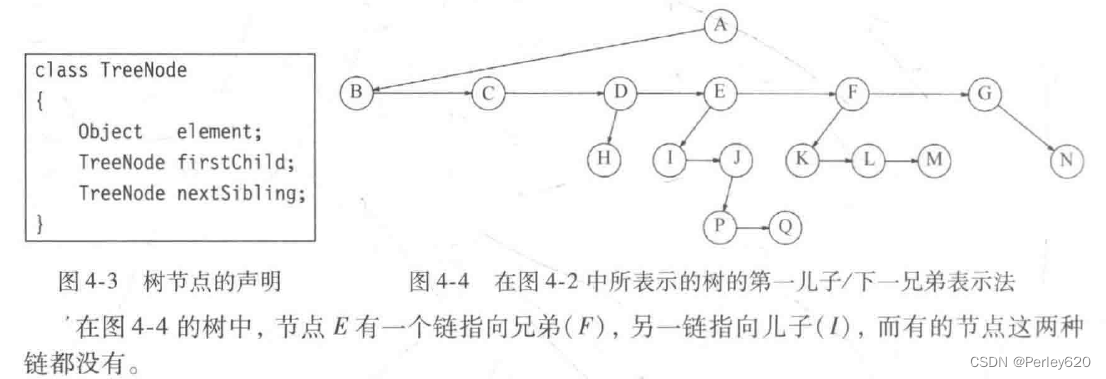
实现树的一种方法可以是在每一个节点除数据外还要有一些链,使得该节点的每一个儿子都有一个链指向它。然而,由于每个节点的儿子数可以变化很大并且事先不知道,因此在数据结构中建立到各(儿)子节点直接的链接是不可行的,因为这样会产生太多浪费的空间。实际上解决方法很简单:将每个节点的所有儿子都放在树节点的链表中。
下图指出一棵树如何用这种实现方法表示出来。图中向下的箭头是指向firstChild(第一儿子)的链,而水平箭头是指向nextSibling(下一兄弟)的链。因为null链太多了,所以没有把它们画出。
树的深度是指从根节点到最远叶子节点的路径上的节点数。换句话说,树的深度表示树中最长路径的长度。
在一棵树中,根节点位于第一层,它没有父节点。每个非叶子节点的深度是其父节点的深度加1。叶子节点的深度是从根节点到该叶子节点的路径上的节点数。
树的深度可以用来衡量树的高度或者树的层数。深度为0的树只有一个根节点,深度为1的树有一个根节点和一个子节点,以此类推。
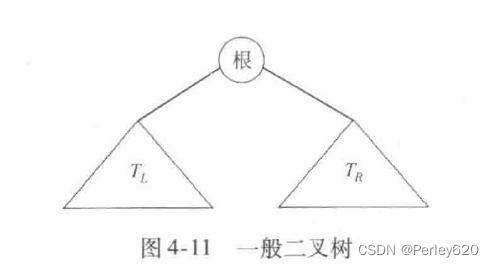
二叉树binary tree
二叉树(binary tree)是一棵树,其中每个节点都不能有多于两个的儿子。一棵由一个根和两棵子树组成的二叉树,子树TL,和TK均可能为空。
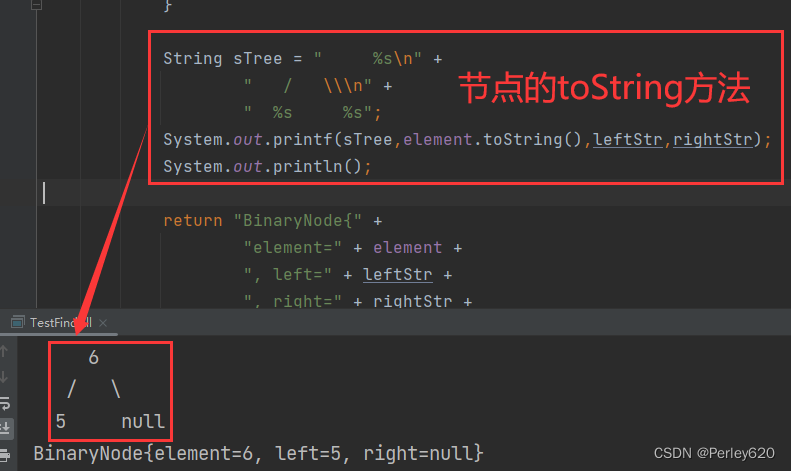
因为一个二叉树节点最多有两个子节点,所以我们可以保存直接链接到它们的链。树节点的声明在结构上类似于双链表的声明,在声明中,节点就是由element(元素)的信息加上两个到其他节点的引用( Left 和 Right)组成的结构。

节点的实现

toString方法
/**
* 内部类,节点,元素,左节点,右节点。类似于链表
* @param <T>
*/
public static class BinaryNode<T>{
T element; // 当前节点的数据
BinaryNode<T> left; // 左侧的节点
BinaryNode<T> right; // 右侧的节点
public BinaryNode(T element) {
this(element,null,null);
}
public BinaryNode(T element, BinaryNode<T> left, BinaryNode<T> right) {
this.element = element;
this.left = left;
this.right = right;
}
@Override
public String toString() {
String leftStr = null;
String rightStr = null;
if (left!=null) {
leftStr = left.element.toString();
}
if (right!=null){
rightStr = right.element.toString();
}
String sTree = " %s\n" +
" / \\\n" +
" %s %s";
System.out.printf(sTree,element.toString(),leftStr,rightStr);
System.out.println();
return "BinaryNode{" +
"element=" + element +
", left=" + leftStr +
", right=" + rightStr +
'}';
}
}
查找树ADT——二叉查找树Binary Search Tree
二叉树的一个重要的应用是它们在查找中的使用。假设树中的每个节点存储一项数据。在我们的例子中,虽然任意复杂的项在Jva中都容易处理,但为简单起见还是假设它们是整数。还将假设所有的项都是互异的,以后再处理有重复元的情况。
使二叉树成为二叉查找树的性质是,对于树中的每个节点X,它的左子树中所有项的值小于X中的项,而它的右子树中所有项的值大于X中的项。注意,这意味着该树所有的元素可以用某种一致的方式排序。
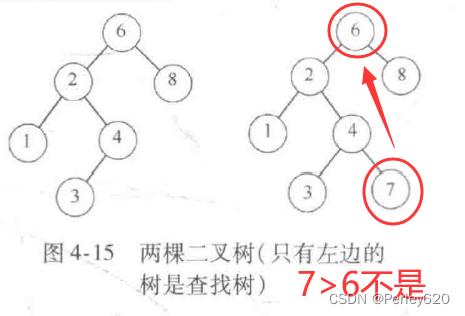
二叉查找树(Binary Search Tree,简称BST)是一种特殊的二叉树,它具有以下性质:
- 对于树中的每个节点,其左子树中的所有节点的值都小于该节点的值,而右子树中的所有节点的值都大于该节点的值。
- 对于树中的每个节点,其左子树和右子树也都是二叉查找树。
基于这些性质,二叉查找树可以支持高效的查找、插入和删除操作。
6
/ \
2 8
/ \
1 4
/
3
提供一个生成一颗树的方法
/**
*
* 6
* / \
* 2 8
* / \
* 1 4
* /
* 3
* @return 获得一二叉树
*/
public BinarySearchTree<Integer> getIntegerTree() {
BinaryNode<Integer> root = new BinaryNode<>(6);
root.left = new BinaryNode<>(2);
root.right = new BinaryNode<>(8);
root.left.left = new BinaryNode<>(1);
root.left.right = new BinaryNode<>(4);
root.left.right.left = new BinaryNode<>(3);
return new BinarySearchTree<>(root);
}
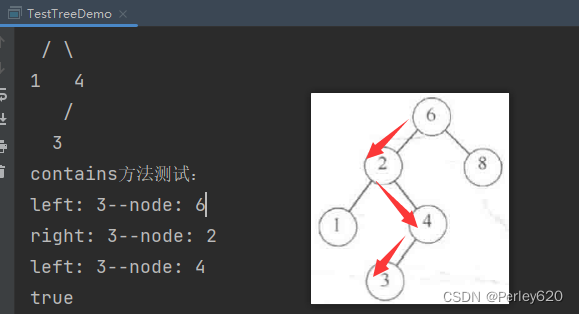
1.contains方法
如果在树T中存在含有项X的节点,那么这个操作需要返回true,如果这样的节点不存在则返回false。树的结构使得这种操作很简单。如果T是空集,那么可以就返回false。否则,如果存储在T处的项是X,那么可以返回true。否则,我们对树T的左子树或右子树进行一次递归调用,这依赖于X与存储在T中的项的关系。
关键的问题是首先要对是否空树进行测试,否则我们就会生成一个企图通过null引用访问数据域的NullPointerException异常。
/**
* 从根节点开始,递归查找,判断x是否在树中
* @param x 判断的元素
* @param node 从哪个节点开始判断
* @return
*/
public boolean contains(T x,BinaryNode<T> node){
if (node==null){// 根节点为null,空树
return false;
}
// 进行比较
int compareResult = x.compareTo(node.element);
if (compareResult >0){
// 说明x大于当前节点,则往右走
System.out.println("right: "+x+"--node: "+node.element);
return contains(x, node.right);
}else if(compareResult <0){
System.out.println("left: "+x+"--node: "+node.element);
return contains(x, node.left); // 往左走
}else {
return true; // 找到了
}
}
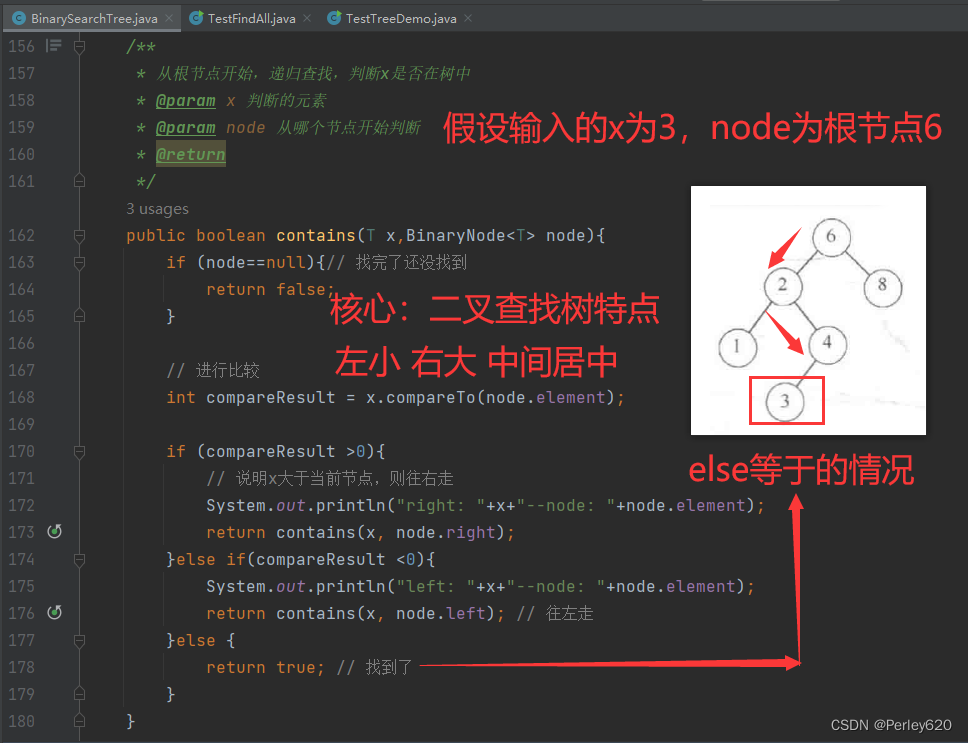
查找的顺序
2.findMax和findMin方法
最大

最小
/**
* 查找最大值,需要保证不是空树
* @return
*/
public T findMax(){
if (isEmpty()){
System.out.println("空树");
return null;
}
// 根据二叉查找树的定义,最大值就是不断往右找
BinaryNode<T> right = root.right;
T max = root.element;
while (right!=null){
max = right.element;
right = right.right;
}
return max;
}
/**
* 从某个节点开始找最大值
* @param node 开始的节点
* @return
*/
public T findMax(BinaryNode<T> node){
if (isEmpty()){
System.out.println("空树");
return null;
}
if (node!=null){
while (node.right!=null){
node = node.right;
}
return node.element;
}
return null;
}
/**
*
* @param node 开始查找的节点
* @return
*/
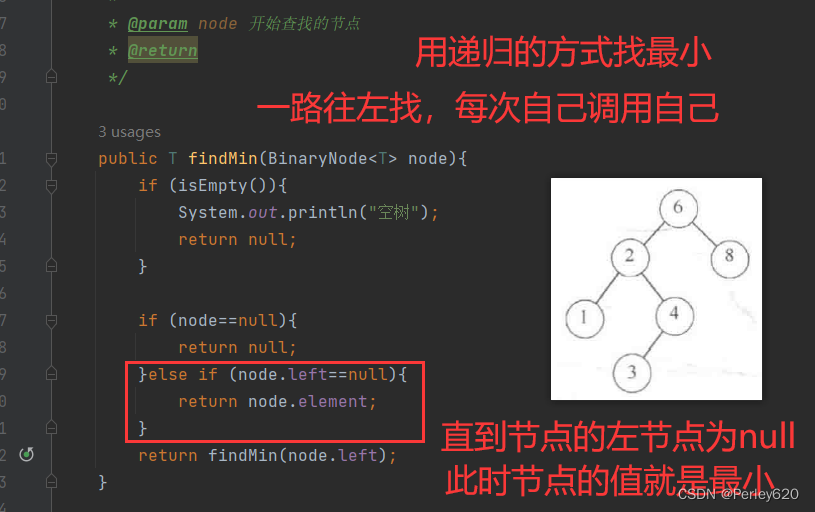
public T findMin(BinaryNode<T> node){
if (isEmpty()){
System.out.println("空树");
return null;
}
if (node==null){
return null;
}else if (node.left==null){
return node.element;
}
return findMin(node.left);
}
3.insert方法
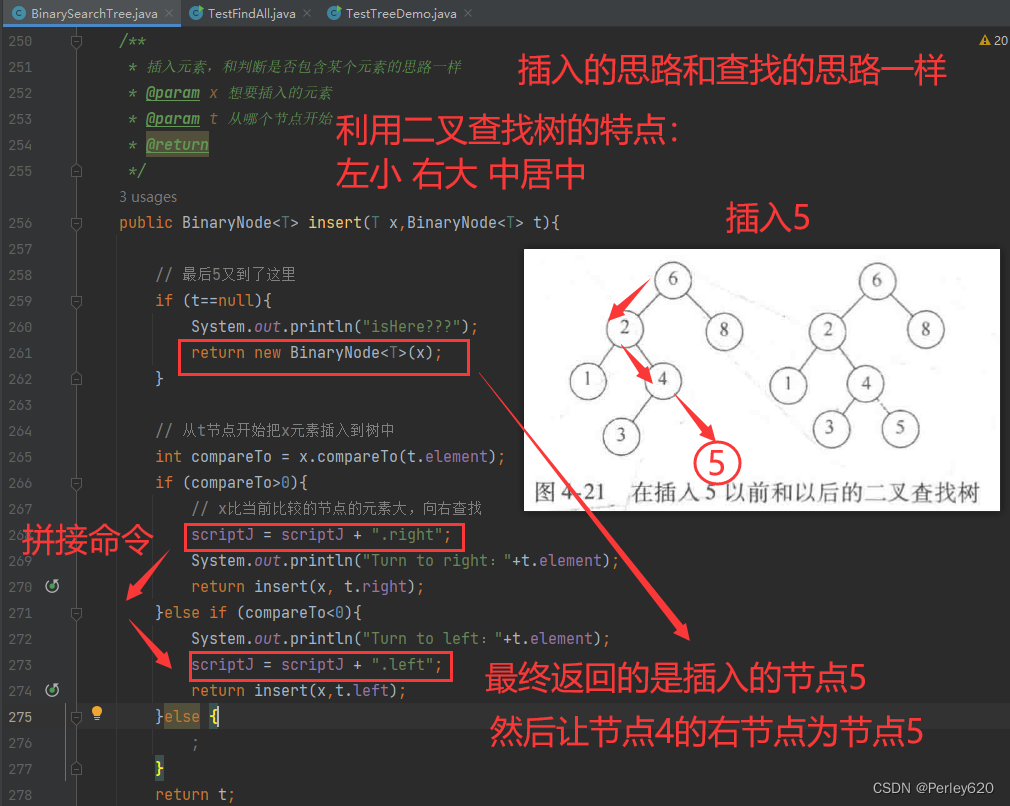
进行插入操作的例程在概念上是简单的。为了将X插入到树T中,你可以像用contains那样沿着树查找。如果找到X,则什么也不用做(或做一些“更新”)。否则,将X插入到遍历的路径上的最后一点上。
下图显示实际的插入情况。为了插入5,我们遍历该树就好像在运行contains。在具有关键字4的节点处,我们需要向右行进,但右边不存在子树,因此5不在这棵树上,从而这个位置就是所要插入的位置。

进行插入的测试

/**
* 获取insert操作后的运行脚本
*/
String scriptJ = "root";
/**
* 插入元素,和判断是否包含某个元素的思路一样
* @param x 想要插入的元素
* @param t 从哪个节点开始
* @return
*/
public BinaryNode<T> insert(T x,BinaryNode<T> t){
// 最后5又到了这里
if (t==null){
// System.out.println("isHere???");
return new BinaryNode<T>(x);
}
// 从t节点开始把x元素插入到树中
int compareTo = x.compareTo(t.element);
if (compareTo>0){
// x比当前比较的节点的元素大,向右查找
scriptJ = scriptJ + ".right";
// System.out.println("Turn to right:"+t.element);
return insert(x, t.right);
}else if (compareTo<0){
// System.out.println("Turn to left:"+t.element);
scriptJ = scriptJ + ".left";
return insert(x,t.left);
}else {
;
}
return t;
}
进行测试:flag脚本执行未成功
System.out.println("插入新的元素");
BinarySearchTree.BinaryNode<Integer> insert = binarySearchTree.insert(5, binarySearchTree.root);
System.out.println(insert);
System.out.println(binarySearchTree.scriptJ); // .left.right.right
System.out.println(binarySearchTree.root.left.right);
System.out.println("执行插入:binarySearchTree."+binarySearchTree.scriptJ + "=insert");
binarySearchTree.root.left.right.right = insert; // 根节点的左右为插入的新节点
System.out.println(binarySearchTree.root.left.right.right);
System.out.println("执行插入后的节点4:"+binarySearchTree.root.left.right);
System.out.println("#######################################");
ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine engine = manager.getEngineByName("js");
Bindings bindings = new SimpleBindings();
bindings.put("binarySearchTree", binarySearchTree);
// String script = "binarySearchTree.root.left.right.right=insert";
String script = "binarySearchTree.root";
Object result = engine.eval(script, bindings);
System.out.println(result);
4.remove方法(复杂)
正如许多数据结构一样,最困难的操作是remove(删除)。一旦我们发现要被删除的节点,就需要考虑几种可能的情况。如果节点是一片树叶,那么它可以被立即删除。如果节点有一个儿子,则该节点可以在其父节点调整自己的链以绕过该节点后被删除(为了清楚起见,我们将明确地画出链的指向)
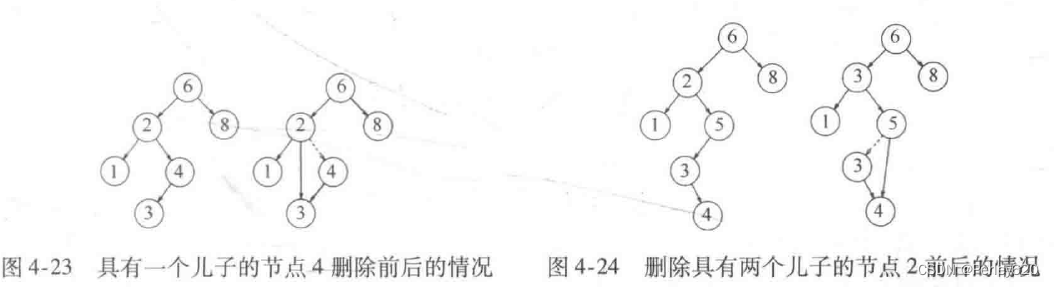
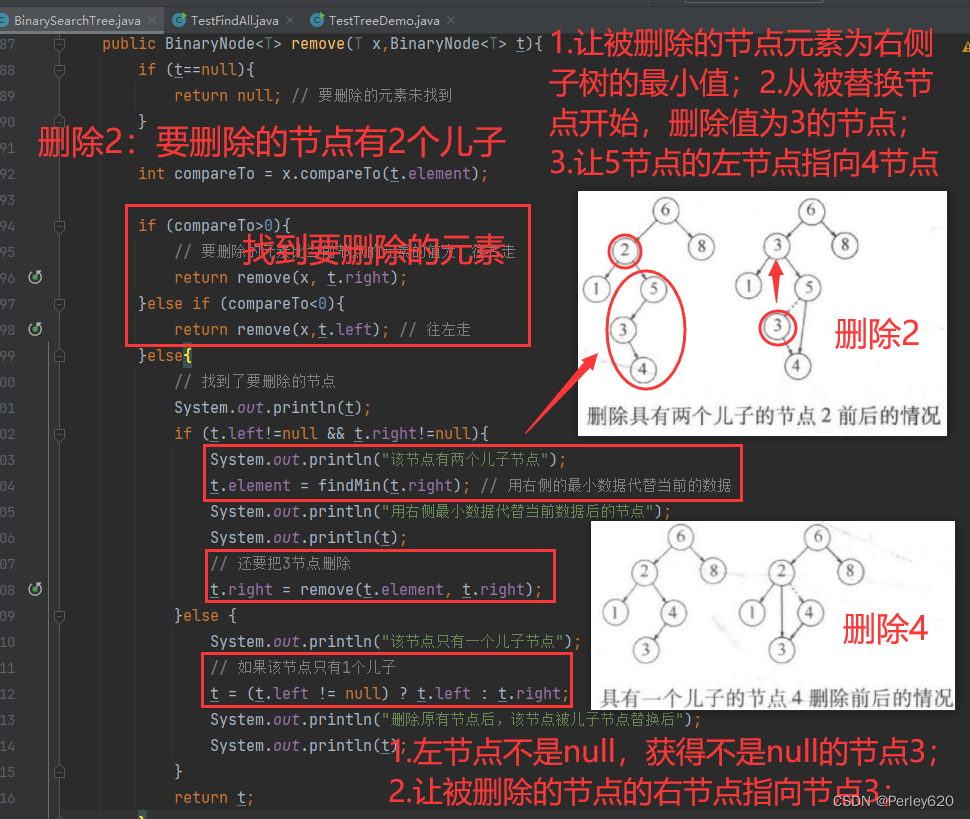
复杂的情况是处理具有两个儿子的节点。一般的删除策略是用其右子树的最小的数据(很容易找到)代替该节点的数据并递归地删除那个节点(现在它是空的)。因为右子树中的最小的节点不可能有左儿子,所以第二次remove要容易。图4-24显示一棵初始的树及其中一个节点被删除后的结果。要被删除的节点是根的左儿子;其关键字是2。它被其右子树中的最小数据3所代替,然后关键字是3的原节点如前例那样被删除。
6
/ \
2 8
/ \
1 5
/
3
\
4
/**
* 删除元素
* @param x 要删除的元素
* @param t 开始遍历的节点
* @return
*/
public BinaryNode<T> remove(T x,BinaryNode<T> t){
if (t==null){
return null; // 要删除的元素未找到
}
int compareTo = x.compareTo(t.element);
if (compareTo>0){
// 要删除的元素比当前节点的元素的值大,往右走
return remove(x, t.right);
}else if (compareTo<0){
return remove(x,t.left); // 往左走
}else{
// 找到了要删除的节点
System.out.println(t);
if (t.left!=null && t.right!=null){
System.out.println("该节点有两个儿子节点");
t.element = findMin(t.right); // 用右侧的最小数据代替当前的数据
System.out.println("用右侧最小数据代替当前数据后的节点");
System.out.println(t);
// 还要把3节点删除
t.right = remove(t.element, t.right);
}else {
System.out.println("该节点只有一个儿子节点");
// 如果该节点只有1个儿子
t = (t.left != null) ? t.left : t.right;
System.out.println("删除原有节点后,该节点被儿子节点替换后");
System.out.println(t);
}
return t;
}
}
删除只有一个儿子的节点4

删除有两个儿子的节点

二叉查找树的深度

如果向一棵树输入预先排好序的数据,那么一连串insert操作将花费二次的时间,而链表实现的代价会非常巨大,因为此时的树将只由那些没有左儿子的节点组成。一种解决办法就是要有一个称为平衡(balance)的附加的结构条件:任何节点的深度均不得过深。许多一般的算法都能实现平衡树。
但是,大部分算法都要比标准的二叉查找树复杂得多,而且更新要平均花费更长的时间。不过,它们确实防止了处理起来非常麻烦的一些简单情形。下面,我们将介绍最古老的一种平衡查找树,即AVL树。
AVL(Adelson-Velskii和Landis)树——平衡条件(balance condition)的二叉查找树
AVL(Adelson-Velskii和Landis)树是带有**平衡条件(balance condition)**的二叉查找树。这个平衡条件必须要容易保持,而且它保证树的深度须是O(1ogN)。最简单的想法是要求左右子树具有相同的高度。如图4-28所示,这种想法并不强求树的深度要浅。
另一种平衡条件是要求每个节点都必须有相同高度的左子树和右子树。虽然这种平衡条件保证了树的深度小,但是它太严格而难以使用,需要放宽条件。
一棵AVL树是其每个节点的左子树和右子树的高度最多差1的二叉查找树(空树的高度定义为-1)。在图4-29中,左边的树是AVL树,但是右边的树不是。

插入元素-旋转(rotation)
因此,除去可能的插入外(我们将假设懒惰删除),所有的树操作都可以以时间O(logN)执行。当进行插入操作时,我们需要更新通向根节点路径上那些节点的所有平衡信息,而插人操作隐含着困难的原因在于,插入一个节点可能破坏AVL树的特性(例如,将6插入到图4-29中的AVL树中将会破坏关键字为8的节点处的平衡条件)。如果发生这种情况,那么就要在考虑
这一步插入完成之前恢复平衡的性质。事实上,这总可以通过对树进行简单的修正来做到,我们称其为旋转(rotation)。
在插入以后,只有那些从插入点到根节点的路径上的节点的平衡可能被改变,因为只有这些节点的子树可能发生变化。当我们沿着这条路径上行到根并更新平衡信息时,可以发现一个节点,它的新平衡破坏了AVL条件。我们将指出如何在第一个这样的节点(即最深的节点)重新平衡这棵树,并证明这一重新平衡保证整个树满足AVL性质。

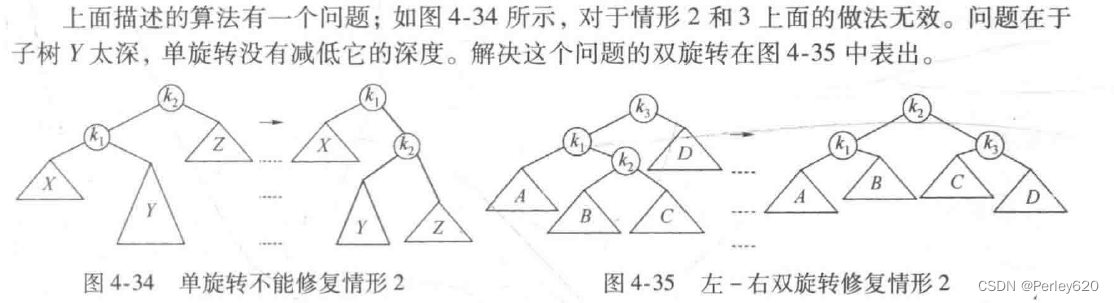
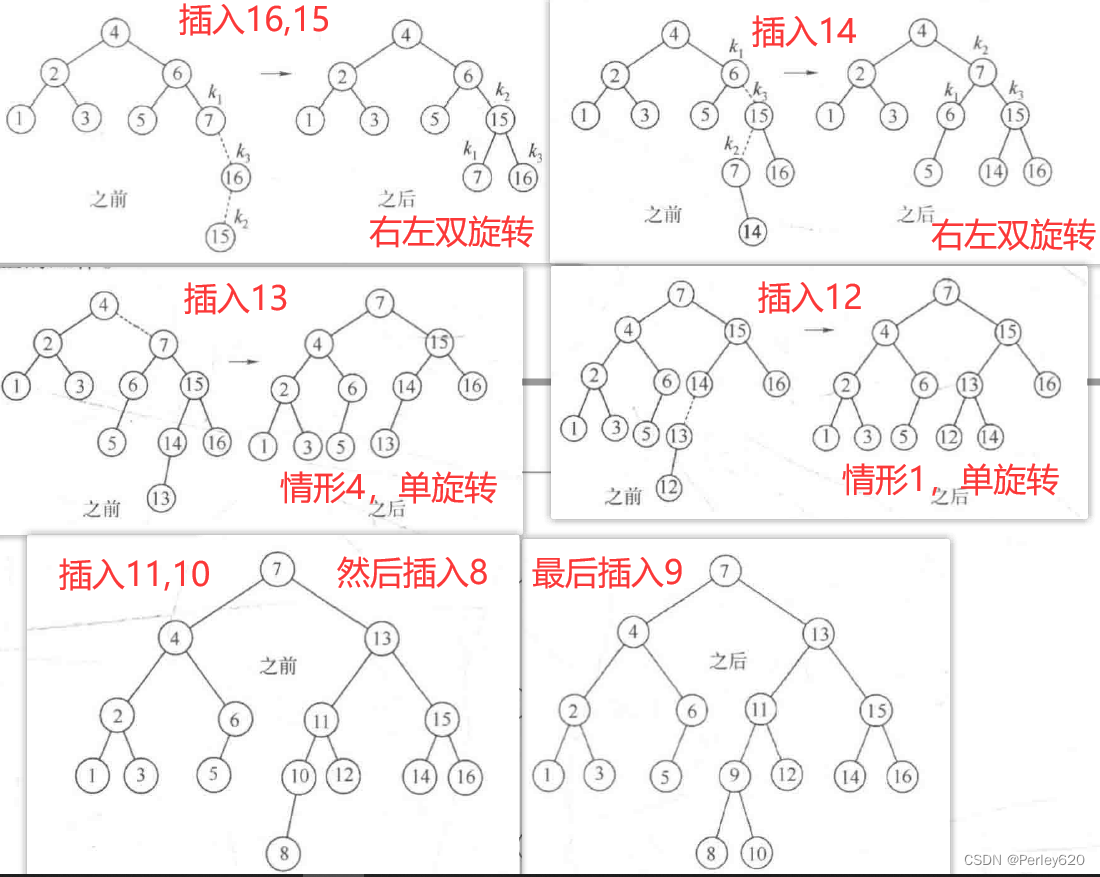
单旋转:左左,右右
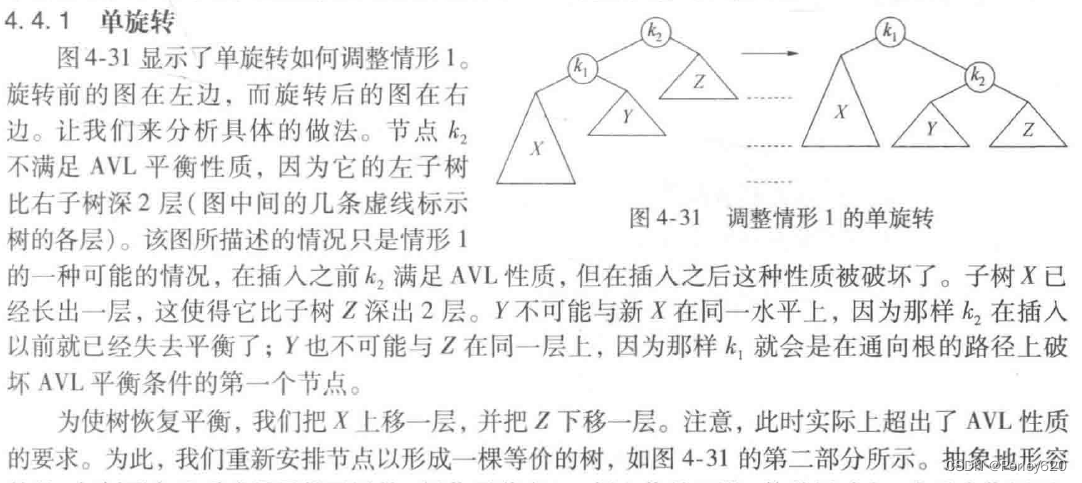
图4-32显示了在将6插人左边原始的AVL树后节点8便不再平衡。于是,我们在7和8之间做一次单旋转,结果得到右边的树。

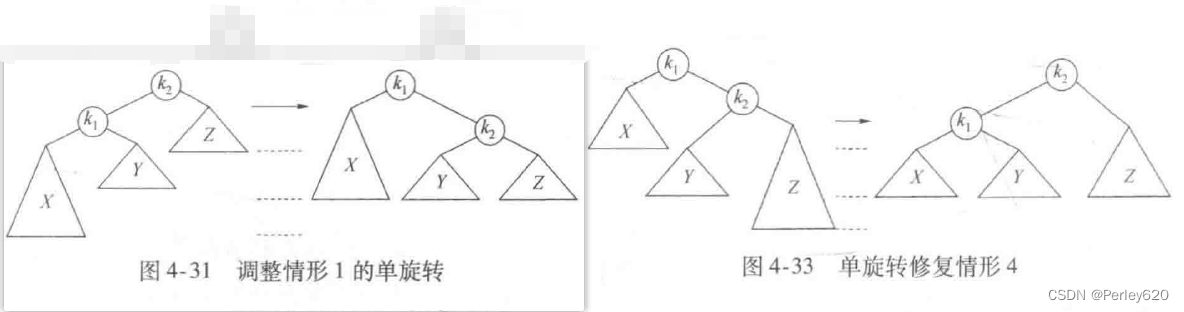
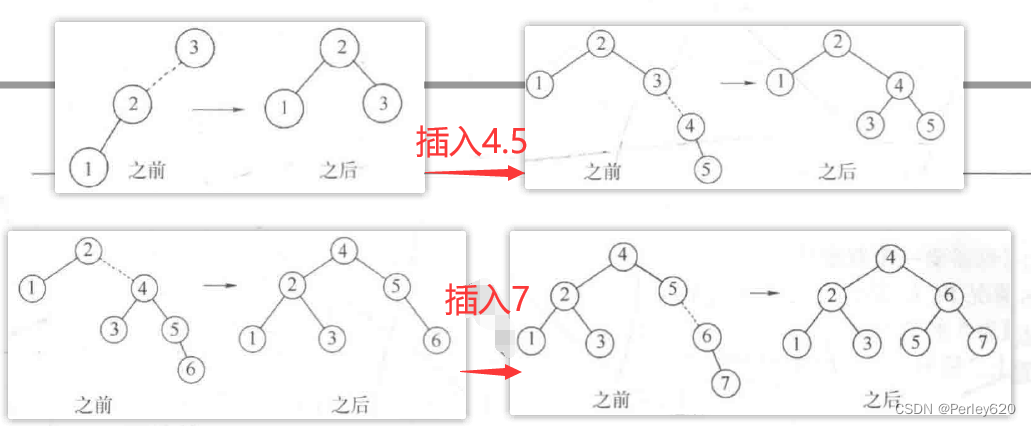
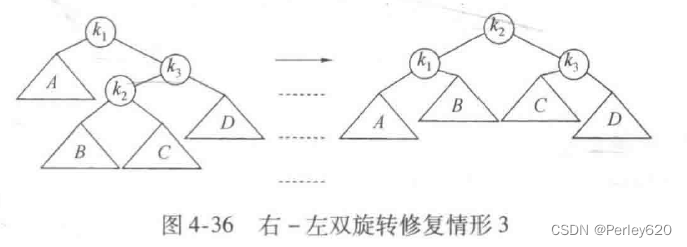
双旋转:左右,右左
树的遍历
7
/ \
4 13
/ \ / \
2 6 11 15
/ \ / / \ / \
1 3 5 9 12 14 16
/ \
8 10
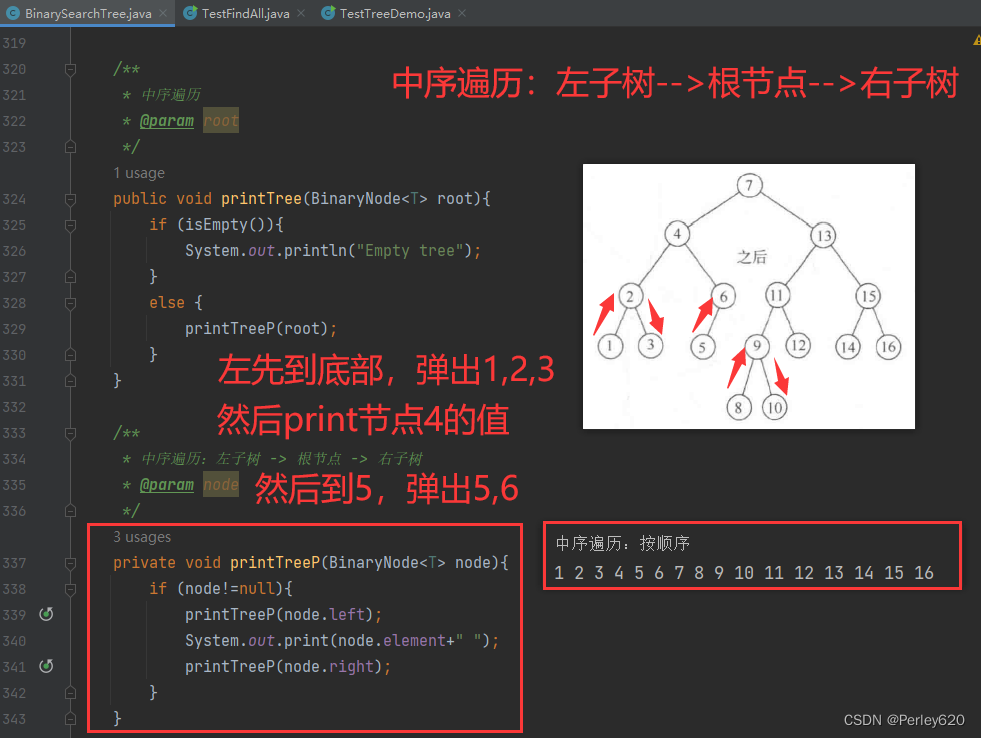
1.中序遍历:依序列
中序遍历(Inorder Traversal)是一种树的遍历方式,它的遍历顺序是先递归地遍历左子树,然后访问根节点,最后递归地遍历右子树。中序遍历的顺序可以表示为:左子树 -> 根节点 -> 右子树。
正如我们前面看到的,这类例程当用于树的时候则称为中序遍历(由于它依序列出了各项,因此是有意义的)。一个中序遍历的一般方法是首先处理左子树,然后是当前的节点,最后处理右子树。这个算法的有趣部分除它简单的特性外,还在于其总的运行时间是O(N)。这是因为在树的每一个节点处进行的工作是常数时间的。每一个节点访问一次,而在每一个节点进行的工作是检测是否ull、建立两个方法调用、并执行println。由于在每个节点的工作花费常数时间以及总共有N个节点,因此运行时间为O(N)。
2.后序遍历:树的深度
后序遍历(Postorder Traversal)是一种树的遍历方式,它的遍历顺序是先递归地遍历左子树,然后递归地遍历右子树,最后访问根节点。后序遍历的顺序可以表示为:左子树 -> 右子树 -> 根节点。
有时我们需要先处理两棵子树然后才能处理当前节点。例如,为了计算一个节点的高度,首先需要知道它的子树的高度程序就是计算高度的。由于检查一些特殊的情况总是有益的——当涉及递归时尤其重要,因此要注意这个例程声明树叶的高度为零,这是正确的。这种一般的遍历顺序叫作后序遍历,我们在前面也见到过。因为在每个节点的工作花费常
数时间,所以总的运行时间也是O(N)。
树的深度是指从根节点到最远叶子节点的路径上的节点数。换句话说,树的深度表示树中最长路径的长度。
在一棵树中,根节点位于第一层,它没有父节点。每个非叶子节点的深度是其父节点的深度加1。叶子节点的深度是从根节点到该叶子节点的路径上的节点数。
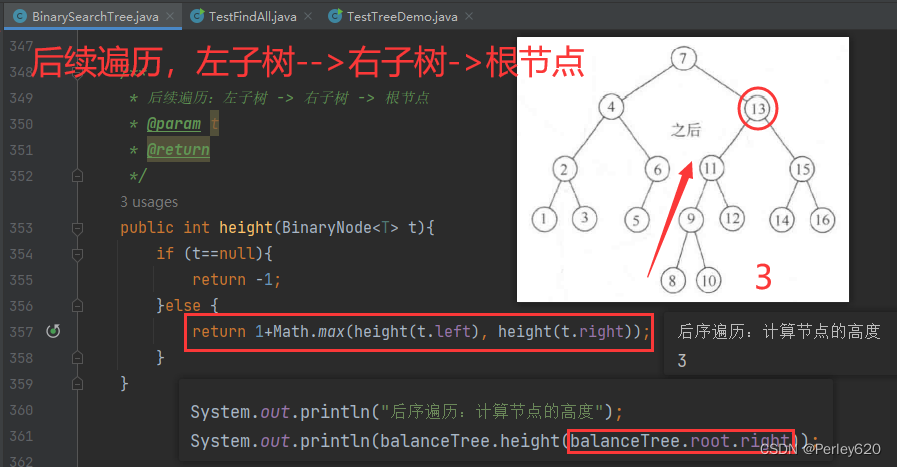
/**
* 后续遍历:左子树 -> 右子树 -> 根节点
* @param t
* @return
*/
public int height(BinaryNode<T> t){
if (t==null){
return -1;
}else {
return 1+Math.max(height(t.left), height(t.right));
}
}
3.先序遍历
先序遍历(Preorder Traversal)是一种树的遍历方式,它的遍历顺序是先访问根节点,然后递归地遍历左子树,最后递归地遍历右子树。先序遍历的顺序可以表示为:根节点 -> 左子树 -> 右子树。
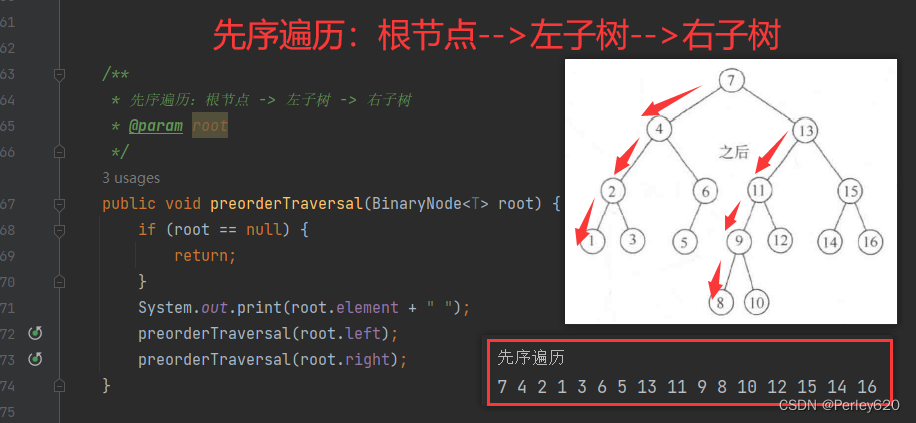
/**
* 先序遍历:根节点 -> 左子树 -> 右子树
* @param root
*/
public void preorderTraversal(BinaryNode<T> root) {
if (root == null) {
return;
}
System.out.print(root.element + " ");
preorderTraversal(root.left);
preorderTraversal(root.right);
}
完整代码
BinarySearchTree<T extends Comparable<? super T>>实体类
package com.tianju.book.jpa.tree;
import com.baomidou.mybatisplus.extension.api.R;
import com.github.pagehelper.PageHelper;
public class BinarySearchTree<T extends Comparable<? super T> >{
public BinaryNode<T> root; // 根节点
/**
* 内部类,节点,元素,左节点,右节点。类似于链表
* @param <T>
*/
public static class BinaryNode<T>{
T element; // 当前节点的数据
BinaryNode<T> left; // 左侧的节点
BinaryNode<T> right; // 右侧的节点
public BinaryNode(T element) {
this(element,null,null);
}
public BinaryNode(T element, BinaryNode<T> left, BinaryNode<T> right) {
this.element = element;
this.left = left;
this.right = right;
}
@Override
public String toString() {
String leftStr = null;
String rightStr = null;
if (left!=null) {
leftStr = left.element.toString();
}
if (right!=null){
rightStr = right.element.toString();
}
String sTree = " %s\n" +
" / \\\n" +
" %s %s";
System.out.printf(sTree,element.toString(),leftStr,rightStr);
System.out.println();
return "BinaryNode{" +
"element=" + element +
", left=" + leftStr +
", right=" + rightStr +
'}';
}
}
/**
*
* 6
* / \
* 2 8
* / \
* 1 4
* /
* 3
* @return 获得一二叉树
*/
public BinarySearchTree<Integer> getIntegerTree() {
BinaryNode<Integer> root = new BinaryNode<>(6);
root.left = new BinaryNode<>(2);
root.right = new BinaryNode<>(8);
root.left.left = new BinaryNode<>(1);
root.left.right = new BinaryNode<>(4);
root.left.right.left = new BinaryNode<>(3);
return new BinarySearchTree<>(root);
}
/**
* 6
* / \
* 2 8
* / \
* 1 5
* /
* 3
* \
* 4
* @return
*/
public BinarySearchTree<Integer> getIntegerTreeR() {
BinaryNode<Integer> root = new BinaryNode<>(6);
root.left = new BinaryNode<>(2);
root.right = new BinaryNode<>(8);
root.left.left = new BinaryNode<>(1);
root.left.right = new BinaryNode<>(5);
root.left.right.left = new BinaryNode<>(3);
root.left.right.left.right = new BinaryNode<>(4);
return new BinarySearchTree<>(root);
}
/**
* 调用可获得一颗平衡AVL树
* 7
* / \
* 4 13
* / \ / \
* 2 6 11 15
* / \ / / \ / \
* 1 3 5 9 12 14 16
* / \
* 8 10
* @return 平衡AVL树
*/
public BinarySearchTree<Integer> getBalanceTree() {
BinaryNode<Integer> root = new BinaryNode<>(7);
root.left = new BinaryNode<>(4);
root.left.left = new BinaryNode<>(2);
root.left.left.left = new BinaryNode<>(1);
root.left.left.right = new BinaryNode<>(3);
root.left.right = new BinaryNode<>(6);
root.left.right.left = new BinaryNode<>(5);
root.right = new BinaryNode<>(13);
root.right.left = new BinaryNode<>(11);
root.right.left.left = new BinaryNode<>(9);
root.right.left.left.left = new BinaryNode<>(8);
root.right.left.left.right = new BinaryNode<>(10);
root.right.left.right = new BinaryNode<>(12);
root.right.right = new BinaryNode<>(15);
root.right.right.left = new BinaryNode<>(14);
root.right.right.right = new BinaryNode<>(16);
return new BinarySearchTree<>(root);
}
public BinarySearchTree(BinaryNode<T> root) {
this.root = root;
}
public BinarySearchTree() {
}
public void makeEmpty(){
root = null;
}
public boolean isEmpty(){
return root == null;
}
/**
* 从根节点开始,递归查找,判断x是否在树中
* @param x 判断的元素
* @param node 从哪个节点开始判断
* @return
*/
public boolean contains(T x,BinaryNode<T> node){
if (node==null){// 找完了还没找到
return false;
}
// 进行比较
int compareResult = x.compareTo(node.element);
if (compareResult >0){
// 说明x大于当前节点,则往右走
System.out.println("right: "+x+"--node: "+node.element);
return contains(x, node.right);
}else if(compareResult <0){
System.out.println("left: "+x+"--node: "+node.element);
return contains(x, node.left); // 往左走
}else {
return true; // 找到了
}
}
/**
* 查找最大值,需要保证不是空树
* @return
*/
public T findMax(){
if (isEmpty()){
System.out.println("空树");
return null;
}
// 根据二叉查找树的定义,最大值就是不断往右找
BinaryNode<T> right = root.right;
T max = root.element;
while (right!=null){
max = right.element;
right = right.right;
}
return max;
}
/**
* 从某个节点开始找最大值
* @param node 开始的节点
* @return
*/
public T findMax(BinaryNode<T> node){
if (isEmpty()){
System.out.println("空树");
return null;
}
if (node!=null){
while (node.right!=null){
node = node.right;
}
return node.element;
}
return null;
}
/**
*
* @param node 开始查找的节点
* @return
*/
public T findMin(BinaryNode<T> node){
if (isEmpty()){
System.out.println("空树");
return null;
}
if (node==null){
return null;
}else if (node.left==null){
return node.element;
}
return findMin(node.left);
}
/**
* 获取insert操作后的运行脚本
*/
String scriptJ = "root";
/**
* 插入元素,和判断是否包含某个元素的思路一样
* @param x 想要插入的元素
* @param t 从哪个节点开始
* @return
*/
public BinaryNode<T> insert(T x,BinaryNode<T> t){
// 最后5又到了这里
if (t==null){
// System.out.println("isHere???");
return new BinaryNode<T>(x);
}
// 从t节点开始把x元素插入到树中
int compareTo = x.compareTo(t.element);
if (compareTo>0){
// x比当前比较的节点的元素大,向右查找
scriptJ = scriptJ + ".right";
// System.out.println("Turn to right:"+t.element);
return insert(x, t.right);
}else if (compareTo<0){
// System.out.println("Turn to left:"+t.element);
scriptJ = scriptJ + ".left";
return insert(x,t.left);
}else {
;
}
return t;
}
/**
* 删除元素
* @param x 要删除的元素
* @param t 开始遍历的节点
* @return
*/
public BinaryNode<T> remove(T x,BinaryNode<T> t){
if (t==null){
return null; // 要删除的元素未找到
}
int compareTo = x.compareTo(t.element);
if (compareTo>0){
// 要删除的元素比当前节点的元素的值大,往右走
return remove(x, t.right);
}else if (compareTo<0){
return remove(x,t.left); // 往左走
}else{
// 找到了要删除的节点
System.out.println(t);
if (t.left!=null && t.right!=null){
System.out.println("该节点有两个儿子节点");
t.element = findMin(t.right); // 用右侧的最小数据代替当前的数据
System.out.println("用右侧最小数据代替当前数据后的节点");
System.out.println(t);
// 还要把3节点删除
t.right = remove(t.element, t.right);
}else {
System.out.println("该节点只有一个儿子节点");
// 如果该节点只有1个儿子
t = (t.left != null) ? t.left : t.right;
System.out.println("删除原有节点后,该节点被儿子节点替换后");
System.out.println(t);
}
return t;
}
}
/**
* 中序遍历
* @param root
*/
public void printTree(BinaryNode<T> root){
if (isEmpty()){
System.out.println("Empty tree");
}
else {
printTreeP(root);
}
}
/**
* 中序遍历:左子树 -> 根节点 -> 右子树
* @param node
*/
private void printTreeP(BinaryNode<T> node){
if (node!=null){
printTreeP(node.left);
System.out.print(node.element+" ");
printTreeP(node.right);
}
}
/**
* 后续遍历:左子树 -> 右子树 -> 根节点
* @param t
* @return
*/
public int height(BinaryNode<T> t){
if (t==null){
return -1;
}else {
return 1+Math.max(height(t.left), height(t.right));
}
}
/**
* 先序遍历:根节点 -> 左子树 -> 右子树
* @param root
*/
public void preorderTraversal(BinaryNode<T> root) {
if (root == null) {
return;
}
System.out.print(root.element + " ");
preorderTraversal(root.left);
preorderTraversal(root.right);
}
}
测试代码
package com.tianju.book.jpa.tree;
import javax.script.*;
public class TestTreeDemo {
public static void main(String[] args) throws ScriptException {
BinarySearchTree.BinaryNode<Integer> root = new BinarySearchTree.BinaryNode<>(1);
BinarySearchTree<Integer> tree = new BinarySearchTree<>(root);
BinarySearchTree<Integer> binarySearchTree = new BinarySearchTree<>().getIntegerTree();
Integer element = binarySearchTree.root.left.element;
System.out.printf("根节点 %d 的左侧节点的元素为 %d ",binarySearchTree.root.element,element);
System.out.println();
String s = " 6\n" +
" / \\\n" +
" 2 8\n" +
" / \\\n" +
"1 4\n" +
" /\n" +
" 3";
System.out.println(s);
System.out.println("contains方法测试:");
boolean contains = binarySearchTree.contains(3, binarySearchTree.root);
System.out.println(contains);
System.out.println("查找最大值");
Integer max = binarySearchTree.findMax();
System.out.println(max);
System.out.println("从某个节点开始找最大值");
Integer max2 = binarySearchTree.findMax(binarySearchTree.root.left);
System.out.println(max2);
System.out.println("查找最小值");
Integer min = binarySearchTree.findMin(binarySearchTree.root);
System.out.println(min);
// System.out.println("插入新的元素");
// BinarySearchTree.BinaryNode<Integer> insert = binarySearchTree.insert(5, binarySearchTree.root);
// System.out.println(insert);
//
// System.out.println(binarySearchTree.scriptJ); // .left.right.right
// System.out.println(binarySearchTree.root.left.right);
//
// System.out.println("执行插入:binarySearchTree."+binarySearchTree.scriptJ + "=insert");
//
// binarySearchTree.root.left.right.right = insert; // 根节点的左右为插入的新节点
//
// System.out.println(binarySearchTree.root.left.right.right);
// System.out.println("执行插入后的节点4:"+binarySearchTree.root.left.right);
//
//
// System.out.println("#######################################");
// ScriptEngineManager manager = new ScriptEngineManager();
// ScriptEngine engine = manager.getEngineByName("js");
// Bindings bindings = new SimpleBindings();
//
// bindings.put("binarySearchTree", binarySearchTree);
//
String script = "binarySearchTree.root.left.right.right=insert";
// String script = "binarySearchTree.root";
//
// Object result = engine.eval(script, bindings);
// System.out.println(result);
System.out.println("删除节点");
BinarySearchTree.BinaryNode<Integer> remove = binarySearchTree.remove(4, binarySearchTree.root);
System.out.println(remove);
System.out.println("删除有两个儿子的节点");
BinarySearchTree<Integer> treeR = new BinarySearchTree<>().getIntegerTreeR();
treeR.remove(2, treeR.root);
}
}
树的遍历测试
package com.tianju.book.jpa.tree;
public class TestFindAll {
public static void main(String[] args) {
BinarySearchTree<Integer> balanceTree = new BinarySearchTree<Integer>().getBalanceTree();
System.out.println(" 7\n" +
" / \\\n" +
" 4 13\n" +
" / \\ / \\\n" +
" 2 6 11 15\n" +
" / \\ / / \\ / \\\n" +
" 1 3 5 9 12 14 16\n" +
" / \\\n" +
" 8 10");
System.out.println(balanceTree.root.left.right);
System.out.println("中序遍历:按顺序");
balanceTree.printTree(balanceTree.root);
System.out.println();
System.out.println("后序遍历:计算节点的高度");
System.out.println(balanceTree.height(balanceTree.root.right));
System.out.println("先序遍历");
balanceTree.preorderTraversal(balanceTree.root);
}
}
总结
1.树的出现:解决链表线性访问时间太慢,树的时间复杂度O(logN);
2.二叉树的定义,最多两个儿子节点;
3.二叉查找树,左小,右大,中居中;remove方法,两种,只有一个儿子节点,有两个儿子节点;
4.AVL树,在二叉查找树基础上加平衡条件,旋转方法,单旋转,双旋转;
5.树的遍历方式,中序遍历,左根右;后续遍历,左右根;先序遍历,根左右;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/165063.html

