
一、环境配置
1.Anaconda以及Tensorflow的安装
1.anaconda以及Tensorflow的安装:
https://blog.csdn.net/qq_33505204/article/details/81584257
2.Anaconda详细安装及使用教程:
https://blog.csdn.net/ITLearnHall/article/details/81708148
3.windows平台下,TensorFlow的安装、卸载以及遇到的各种错误:
https://blog.csdn.net/qq_27245699/article/details/81050035

2.CONDA环境安装
CONDA环境安装:
conda : data science package & environment manager
创建环境:conda create –name python3 python=3
切换环境:
windows :activate python3
linux/macos : source activate python3
官方地址: https://www.anaconda.com/download/
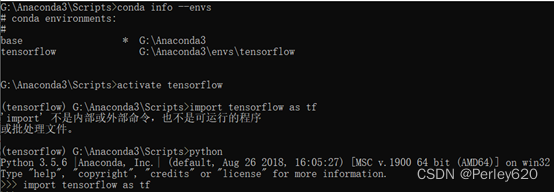
3.测试是否成功
import tensorflow as tf
hello=tf.constant('hello')
sess=tf.Session()
print(sess.run(hello))
from keras import backend
print(backend._BACKEND)
常用命令
显示环境 conda info –envs
进入环境 activate tensorflow
pip uninstall keras
pip uninstall keras-preprocessing -y
pip install keras
二、认识TensorFlow
tensor: 张量
operation:(op): 专⻔门运算的操作节点,所有操作都是⼀个op
图:graph:你的整个程序的结构
会话:运算程序的图
import tensorflow as tf
############ 去除警告
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
# 实现一个加法运算
a = tf.constant(5.0)
b = tf.constant(6.0)
sum1 = tf.add(a, b)
with tf.Session() as sess:
print(sess.run(sum1))
1.图 Graph()
图默认已经注册,一组表示 tf.Operation计算单位的对象和tf.Tensor
表示操作之间流动的数据单元的对象
获取调用:
- tf.get_default_graph()
- op、sess或者tensor 的graph属性
创建图:
- tf.Graph() :使用新创建的图
import tensorflow as tf
############ 去除警告
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
# 创建一张图,上下文环境
# 图包含了一组op和tensor
# op:只要使用tensorflow的API定义的函数都是OP
# tensor:就指代的是数据
g = tf.Graph()
print(g)
with g.as_default():
c = tf.constant(11.0)
print(c.graph)
# 实现一个加法运算
a = tf.constant(5.0)
b = tf.constant(6.0)
sum1 = tf.add(a, b)
# 默认的这张图,相当于是给程序分配一段内存
graph = tf.get_default_graph()
print(graph)
#只能运行一个图
with tf.Session() as sess:
print(sess.run(sum1))
print(a.graph)
print(sum1.graph)
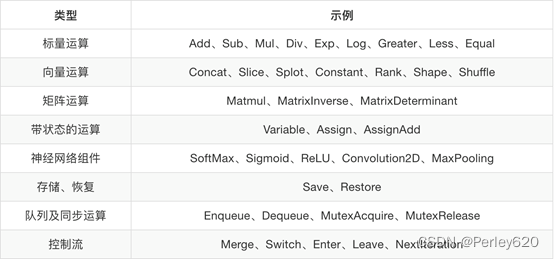
2.会话 Session()


• tf.Session()
运行TensorFlow操作图的类,使用默认注册的图(可以指定运行图)
• 会话资源
会话可能拥有很多资源,如 tf.Variable,tf.QueueBase
和tf.ReaderBase,会话结束后需要进行资源释放
- sess = tf.Session() sess.run(…) sess.close()
- 使用上下文管理器
with tf.Session() as sess:
sess.run(…)
• config=tf.ConfigProto(log_device_placement=True)
• 交互式:tf.InteractiveSession()
import tensorflow as tf
############ 去除警告
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
# 创建一张图,上下文环境
# 图包含了一组op和tensor
# op:只要使用tensorflow的API定义的函数都是OP
# tensor:就指代的是数据
# 实现一个加法运算
a = tf.constant(5.0)
b = tf.constant(6.0)
sum1 = tf.add(a, b)
# 默认的这张图,相当于是给程序分配一段内存
graph = tf.get_default_graph()
print(graph)
# 看出程序在哪里运行
# 只要有上下文环境,就可以方便使用eval()
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as sess:
print(sess.run(sum1))
print(sum1.eval())
print(a.graph)
print(sum1.graph)
会话的run()方法

import tensorflow as tf
############ 去除警告
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
# 创建一张图,上下文环境# 图包含了一组op和tensor
# op:只要使用tensorflow的API定义的函数都是OP# tensor:就指代的是数据
# 实现一个加法运算
a = tf.constant(5.0)
b = tf.constant(6.0)
sum1 = tf.add(a, b)
var1=3
## 有重载的机制,默认会给运算符重载成op类型
sum2 = a + var1
print(sum2)
# 训练模型
# 实时的提供数据去进行训练
# placeholder是一个占位符,feed_dict一个字典
plt = tf.placeholder(tf.float32, [2, 3])
plt2=tf.placeholder(tf.float32,[None,3])
print(plt)
# 只要有上下文环境,就可以方便使用eval()# 看出程序在哪里运行
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as sess:
print(sess.run([a,b,sum1,sum2]))
print(sess.run(plt,feed_dict={plt:[[1, 2, 3], [4, 5, 36]]}))
print(sess.run(plt2, feed_dict={plt2: [[1, 2, 3], [4, 5, 36],[3,4,6]]}))
print(sum1.eval())#输出结果
print(a.graph)
print(sum1.graph)
Tensorflow Feed操作
意义:在程序执行的时候,不确定输入的是什么,提前“占个坑”
语法:placeholder提供占位符,run时候通过feed_dict指定参数
3.张量 Tensor
要点:
• Tensorflow基本的数据格式
• 一个类型化的N维度数组(tf.Tensor)
• 三部分,名字,形状,数据类型
(1)张量的形状

(2)数据类型
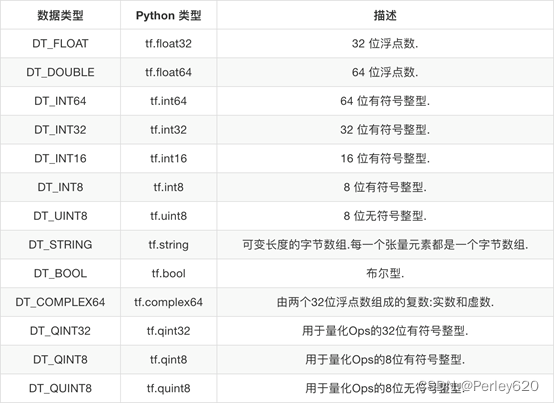
张量属性:
• graph 张量所属的默认图
• op 张量的操作名
• name 张量的字符串描述
• shape 张量形状
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as sess:
print(sess.run([a,b,sum1,sum2]))
print(sess.run(plt,feed_dict={plt:[[1, 2, 3], [4, 5, 36]]}))
print(sess.run(plt2, feed_dict={plt2: [[1, 2, 3], [4, 5, 36],[3,4,6]]}))
print(sum1.eval())#输出结果
print(a.graph)
print(a.shape)
print(a.name)
print(a.op)
张量的动态形状与静态形状

import tensorflow as tf
############ 去除警告
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
#tensorflow中的形状:
# 0维:() 1维:(5) 2维:(5,6) 3维:(2,3,4)2张3行4列的表
# 形状的概念
# 静态形状和动态性状
# 对于静态形状来说,一旦张量形状固定了,不能再次设置静态形状, 不能夸维度修改 1D->1D 2D->2D
# 动态形状可以去创建一个新的张量,改变时候一定要注意元素数量要匹配 1D->2D 1->3D
plt=tf.placeholder(tf.float32,[None,2])
print(plt)
plt.set_shape([3,2])
print(plt)
plt_reshape=tf.reshape(plt,[2,3])
print(plt_reshape)
with tf.Session() as sess:
pass
1、转换静态形状的时候,1-D到1-D,2-D到2-D,不能跨阶数改变形状
2、对于已经固定或者设置静态形状的张量/变量,不能再次设置静态形状
3、tf.reshape()动态创建新张量时,元素个数不能不匹配
4.张量操作
(1)生成张量


(2)张量变换


切片与扩展
tf.concat(values, axis, name=‘concat’)
• 算术运算符
• 基本数学函数
• 矩阵运算
• 减少维度的运算(求均值)
• 序列运算
5.变量OP——模型参数
• 变量也是一种OP,是一种特殊的张量,能够进行存储持久化,它的值就是张量

变量的初始化
tf.global_variables_initializer() 添加一个初始化所有变量的op,在会话中开启
import tensorflow as tf
############ 去除警告
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
a=tf.constant([1,2,3,4])
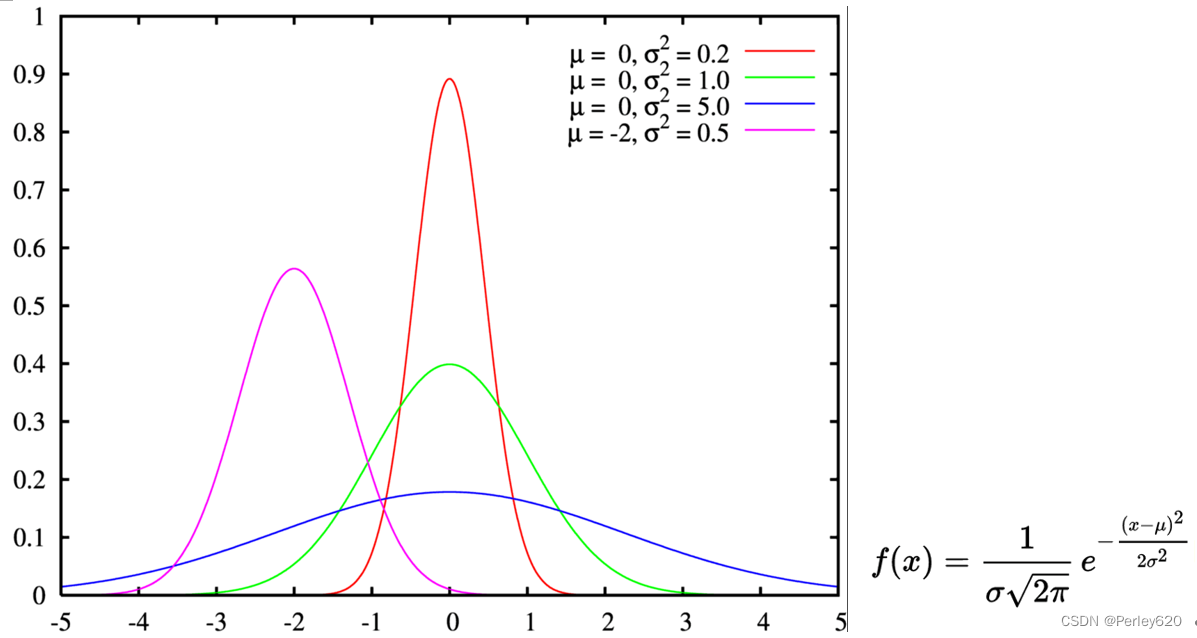
var = tf.Variable(tf.random_normal([2,3],mean=0,stddev=1.0))
print(a,var)
#必须做一个显示的初始化
init_op=tf.global_variables_initializer()
with tf.Session() as sess:
#必须运行初始化op
sess.run(init_op)
print(sess.run([a,var]))
pass
# 变量op
# 1、变量op能够持久化保存,普通张量op是不行的
# 2、当定义一个变量op的时候,一定要在会话当中去运行初始化
# 3、name参数:在tensorboard使用的时候显示名字,可以让相同op名字的进行区分
作用域——使得代码图清晰

tf.variable_scope(<scope_name>)
创建指定名字的变量作用域
观察变量的name改变?嵌套使用变量作用域
观察变量的name改变?
tensorflow变量作用域的作用:
• 让模型代码更加清晰,作用分明
增加变量显示——观察变化
1.收集变量
tf.summary.scalar( name =” ”, tensor )
收集对于损失函数和准确率等单值变量,name为变量名字,tensor为值
tf.summary.histogram( name =” ”, tensor )
收集高纬度的变量参数
tf.summary.image( name =” ”, tensor )
收集输入的图片,张量能显示图片
2.合并变量,写入事件文件
merged = tf.summary.merge_all( )
运行合并:summary = sess.run( merged ) 每次迭代都需要运行
添加: filewriter.add_summary(summary,i) i表示第几次的值
目的:
观察模型的参数,损失等变量值的变化
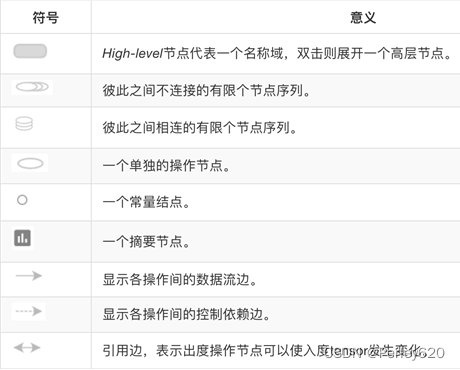
6.事件文件与可视化
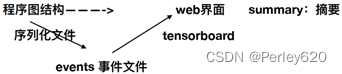

数据序列化-events文件
TensorBoard 通过读取 TensorFlow 的事件文件来运行tf.summary.FileWriter(‘/tmp/tensorflow/summary/test/’, graph=default_graph)
返回filewriter,写入事件文件到指定目录(最好用绝对路径),以提供给tensorboard使用开启
Tensorboard –logdir=”./tmp/tensorflow/summary/test/”
一般浏览器打开为127.0.0.1:6006注:修改程序后,再保存一遍会有新的事件文件,打开默认为最新
import tensorflow as tf
############ 去除警告
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
a=tf.constant([1,2,3,4])
var = tf.Variable(tf.random_normal([2,3],mean=0,stddev=1.0))
print(a,var)
#必须做一个显示的初始化
init_op=tf.global_variables_initializer()
with tf.Session() as sess:
#必须运行初始化op
sess.run(init_op)
# 把程序的图结构写入事件文件,graph:把指定的图写进事件文件当中
filewriter=tf.summary.FileWriter('./py_tensflow/', graph=sess.graph)
pass
Tensorboard –logdir=” F:/python/py_tensflow/”
文件路径 ,没有名字
1.在保存的事件文件所在的文件中输入 cmd


2.依次输输入
conda info --envs
activate tensorflow
Tensorboard --logdir=" F:/python/py_tensflow/"
3.火狐浏览器打开
历史记录中打开即可
http://DESKTOP-PJDM5BE:6006
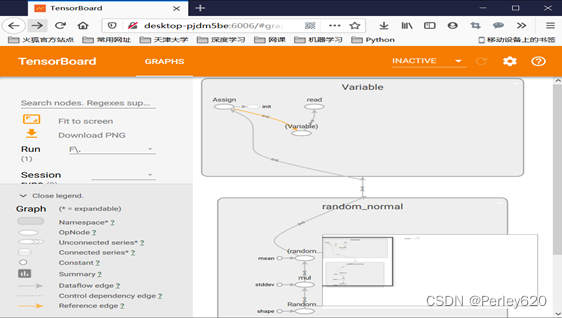
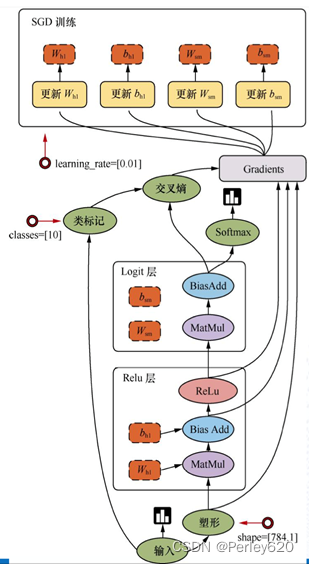
案例:线性回归
Tensorflow运算API
矩阵运算
相乘 tf.matmul(x, w)
平方 tf.square(error)
均值 tf.reduce_mean(error)
梯度下降API

tf.train.GradientDescentOptimizer(learning_rate)
梯度下降优化
learning_rate:学习率,一般为
method:
return:梯度下降op
版本一:trainable参数
# trainable参数:指定这个变量能跟着梯度下降一起优化
import tensorflow as tf
############ 去除警告
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
def myregre():
'''
自定义一个线性回归
:return:None
'''
# 1.准备数据,x 特征值 (100,1) y 目标值(100)
x=tf.random_normal([100,1],mean=1.75,stddev=0.5,name="x_data")
# 矩阵相乘必须是二维的
y_true=tf.matmul(x,[[0.7]])+0.8
# 2.建立线性回归模型 1个权重,1个特征,1个偏置 y=x w + b
# 随机给权重和偏置的,让他计算损失,然后在当前状态下优化
# 用变量定义才能优化
weight = tf.Variable(tf.random_normal([1,1],mean=0.0,stddev=1.0),name="w")
bias = tf.Variable(0.0,name="b")
y_predict=tf.matmul(x,weight)+bias
# 建立损失函数,均方误差
loss = tf.reduce_mean(tf.square(y_true-y_predict))
# 4.梯度下降,优化损失 learning_rate 0~1,2,3,5,7
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 定义一个初始化的 op
init_op=tf.global_variables_initializer()
# 通过会话运行程序
with tf.Session() as sess:
# 初始化变量
sess.run(init_op)
# 打印随机初始化的权重和偏置
print("随机初始化的参数权重为: %f 偏置为: %f" % (weight.eval(),bias.eval()))
# 循环训练 运行优化
for i in range(200):
sess.run(train_op)
print("优化为: %f 偏置为: %f" % (weight.eval(), bias.eval()))
pass
return None
if __name__ == '__main__':
myregre()
版本2:变量作用域
import tensorflow as tf
############ 去除警告
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
def myregre():
'''
自定义一个线性回归
:return:None
'''
with tf.variable_scope("data"):
# 1.准备数据,x 特征值 (100,1) y 目标值(100)
x=tf.random_normal([100,1],mean=1.75,stddev=0.5,name="x_data")
# 矩阵相乘必须是二维的
y_true=tf.matmul(x,[[0.7]])+0.8
with tf.variable_scope("model"):
# 2.建立线性回归模型 1个权重,1个特征,1个偏置 y=x w + b
# 随机给权重和偏置的,让他计算损失,然后在当前状态下优化
# 用变量定义才能优化
weight = tf.Variable(tf.random_normal([1,1],mean=0.0,stddev=1.0),name="w")
bias = tf.Variable(0.0,name="b")
y_predict=tf.matmul(x,weight)+bias
with tf.variable_scope("loss"):
# 建立损失函数,均方误差
loss = tf.reduce_mean(tf.square(y_true-y_predict))
with tf.variable_scope("optimizer"):
# 4.梯度下降,优化损失 learning_rate 0~1,2,3,5,7
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 定义一个初始化的 op
init_op=tf.global_variables_initializer()
# 通过会话运行程序
with tf.Session() as sess:
# 初始化变量
sess.run(init_op)
# 打印随机初始化的权重和偏置
print("随机初始化的参数权重为: %f 偏置为: %f" % (weight.eval(),bias.eval()))
# 建立事件文件
filewriter = tf.summary.FileWriter('F:/python/py_tensflow/', graph=sess.graph)
# 循环训练 运行优化
for i in range(200):
sess.run(train_op)
print("优化为: %f 偏置为: %f" % (weight.eval(), bias.eval()))
pass
return None
if __name__ == '__main__':
myregre()
版本3:增加变量显示
import tensorflow as tf
############ 去除警告
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
def myregre():
'''
自定义一个线性回归
:return:None
'''
with tf.variable_scope("data"):
# 1.准备数据,x 特征值 (100,1) y 目标值(100)
x=tf.random_normal([100,1],mean=1.75,stddev=0.5,name="x_data")
# 矩阵相乘必须是二维的
y_true=tf.matmul(x,[[0.7]])+0.8
with tf.variable_scope("model"):
# 2.建立线性回归模型 1个权重,1个特征,1个偏置 y=x w + b
# 随机给权重和偏置的,让他计算损失,然后在当前状态下优化
# 用变量定义才能优化
weight = tf.Variable(tf.random_normal([1,1],mean=0.0,stddev=1.0),name="w")
bias = tf.Variable(0.0,name="b")
y_predict=tf.matmul(x,weight)+bias
with tf.variable_scope("loss"):
# 建立损失函数,均方误差
loss = tf.reduce_mean(tf.square(y_true-y_predict))
with tf.variable_scope("optimizer"):
# 4.梯度下降,优化损失 learning_rate 0~1,2,3,5,7
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 1、收集tensor
tf.summary.scalar("losses", loss)
tf.summary.histogram("weights", weight)
# 定义合并Tensor的op
merged = tf.summary.merge_all()
# 定义一个初始化的 op
init_op=tf.global_variables_initializer()
# 通过会话运行程序
with tf.Session() as sess:
# 初始化变量
sess.run(init_op)
# 打印随机初始化的权重和偏置
print("随机初始化的参数权重为: %f 偏置为: %f" % (weight.eval(),bias.eval()))
# 建立事件文件
filewriter = tf.summary.FileWriter('F:/python/py_tensflow/', graph=sess.graph)
# 循环训练 运行优化
for i in range(200):
sess.run(train_op)
# 运行合并的tensor
summary = sess.run(merged)
filewriter.add_summary(summary,i)
print("优化为: %f 偏置为: %f" % (weight.eval(), bias.eval()))
pass
return None
if __name__ == '__main__':
myregre()
7.模型保存和加载

tf.train.Saver(var_list=None,max_to_keep=5)
var_list:指定将要保存和还原的变量。它可以作为一个dict或一个列表传递.
max_to_keep:指示要保留的最近检查点文件的最大数量。
创建新文件时,会删除较旧的文件。如果无或0,则保留所有检查点文件。默认为5(即保留最新的5个检查点文件。)
例如:saver.save(sess, ‘/tmp/ckpt/test/model’) 路径+名字
saver.restore(sess, ‘/tmp/ckpt/test/model’)
保存文件格式:checkpoint文件
版本4:加载之前训练好的模型
import tensorflow as tf
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
def myregre():
'''
自定义一个线性回归
:return:None
'''
with tf.variable_scope("data"):
# 1.准备数据,x 特征值 (100,1) y 目标值(100)
x=tf.random_normal([100,1],mean=1.75,stddev=0.5,name="x_data")
# 矩阵相乘必须是二维的
y_true=tf.matmul(x,[[0.7]])+0.8
with tf.variable_scope("model"):
# 2.建立线性回归模型 1个权重,1个特征,1个偏置 y=x w + b
# 随机给权重和偏置的,让他计算损失,然后在当前状态下优化
# 用变量定义才能优化
weight = tf.Variable(tf.random_normal([1,1],mean=0.0,stddev=1.0),name="w")
bias = tf.Variable(0.0,name="b")
y_predict=tf.matmul(x,weight)+bias
with tf.variable_scope("loss"):
# 建立损失函数,均方误差
loss = tf.reduce_mean(tf.square(y_true-y_predict))
with tf.variable_scope("optimizer"):
# 4.梯度下降,优化损失 learning_rate 0~1,2,3,5,7
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 1、收集tensor
tf.summary.scalar("losses", loss)
tf.summary.histogram("weights", weight)
# 定义合并Tensor的op
merged = tf.summary.merge_all()
# 定义一个初始化的 op
init_op=tf.global_variables_initializer()
# 定义一个保存模型的实例
saver = tf.train.Saver()
# 通过会话运行程序
# 通过会话运行程序
with tf.Session() as sess:
# 初始化变量
sess.run(init_op)
# 打印随机初始化的权重和偏置
print("随机初始化的参数权重为: %f 偏置为: %f" % (weight.eval(),bias.eval()))
# 建立事件文件
filewriter = tf.summary.FileWriter('F:/python/py_tensflow/', graph=sess.graph)
# 加载模型 ,覆盖模型当中随机定义的参数,从上次训练的参数结果开始
if os.path.exists("./py_tensflow/check_file/checkpoint"):
saver.restore(sess,"F:\python\py_tensflow\check_file\model1")
# 循环训练 运行优化
for i in range(200):
sess.run(train_op)
# 运行合并的tensor
summary = sess.run(merged)
filewriter.add_summary(summary,i)
print("优化为: %f 偏置为: %f" % (weight.eval(), bias.eval()))
saver.save(sess,"F:\python\py_tensflow\check_file\model1")
return None
if __name__ == '__main__':
myregre()
8.自定义命令行参数


2、 tf.app.flags.,在flags有一个FLAGS标志,它在程序中可以调用到我们
前面具体定义的flag_name
3、通过tf.app.run()启动main(argv)函数
# 定义命令行参数
# 1、首先定义有哪些参数需要在运行时候指定
# 2、程序当中获取定义命令行参数
# 第一个参数:名字,默认值,说明
tf.app.flags.DEFINE_integer("max_step", 100, "模型训练的步数")
tf.app.flags.DEFINE_string("model_dir", " ", "模型文件的加载的路径")
# 定义获取命令行参数名字
FLAGS = tf.app.flags.FLAGS
# 循环训练 运行优化
for i in range(FLAGS.max_step):
sess.run(train_op)
# 运行合并的tensor
summary = sess.run(merged)
filewriter.add_summary(summary, i)
print("第%d次优化的参数权重为:%f, 偏置为:%f" % (i, weight.eval(), bias.eval()))
saver.save(sess, FLAGS.model_dir)

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/165117.html

