
目录
引出
本文包括数据库基本概念,查询结构,SQL语句的单表查询和多表查询
数据库基本概念
1.数据库分类
-
关系型数据库:
关系型数据库是最常见的数据库类型,它使用表格来存储数据,并且使用SQL语言进行查询和管理。常见的关系型数据库有MySQL、Oracle、SQL Server、PostgreSQL等。
-
非关系型数据库:
非关系型数据库也称为NoSQL数据库,它不使用表格来存储数据,而是使用键值对、文档、图形等方式来存储数据。常见的非关系型数据库有MongoDB、Redis、Cassandra等。
-
内存数据库:
内存数据库是将数据存储在内存中的数据库,它的读写速度非常快,适用于需要高速读写的场景。常见的内存数据库有Memcached、Redis等。
-
图形数据库:
图形数据库是专门用于存储图形数据的数据库,它使用图形模型来存储数据,并且支持复杂的图形查询。常见的图形数据库有Neo4j、OrientDB等。
-
时间序列数据库:
时间序列数据库是专门用于存储时间序列数据的数据库,它支持高效的时间序列数据存储和查询。常见的时间序列数据库有InfluxDB、OpenTSDB等。
-
列式数据库:
列式数据库是将数据按列存储的数据库,它适用于需要高效查询特定列的场景。常见的列式数据库有HBase、Cassandra等。
2.SQL数据库
SQL数据库是指使用SQL(Structured Query Language)语言进行管理和查询的数据库。SQL是一种标准化的语言,用于管理关系型数据库中的数据。SQL数据库通常使用表格来存储数据,每个表格包含多个列和行,每个列代表一个数据字段,每个行代表一个数据记录。SQL数据库可以使用SQL语言进行数据查询、插入、更新和删除等操作。
常见的SQL数据库有MySQL、Oracle、SQL Server、PostgreSQL等。这些数据库都支持SQL语言,并且提供了丰富的功能和工具,可以满足不同的需求和场景。SQL数据库具有以下特点:
- 数据结构化:SQL数据库使用表格来存储数据,每个表格都有固定的结构和数据类型,方便数据管理和查询。
- 数据关系性:SQL数据库中的数据之间存在关系,可以通过关系进行查询和管理。
- 数据安全性:SQL数据库提供了严格的数据访问控制和权限管理,保证数据的安全性。
- 数据一致性:SQL数据库使用事务来保证数据的一致性,可以在多个操作之间保持数据的完整性。
- 数据可扩展性:SQL数据库可以通过添加新的表格和索引来扩展数据存储和查询的能力。
3.数据库设计的三大范式
第一范式:
原子,列信息不可再分;
第二范式:
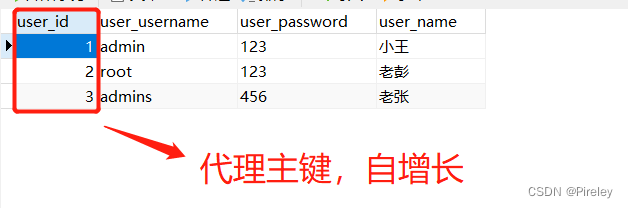
行是唯一的,有主键
代理主键:自增长的整数序列

第三范式:
其他列与主键都相关联,其他列之间无关联
4.查询结构
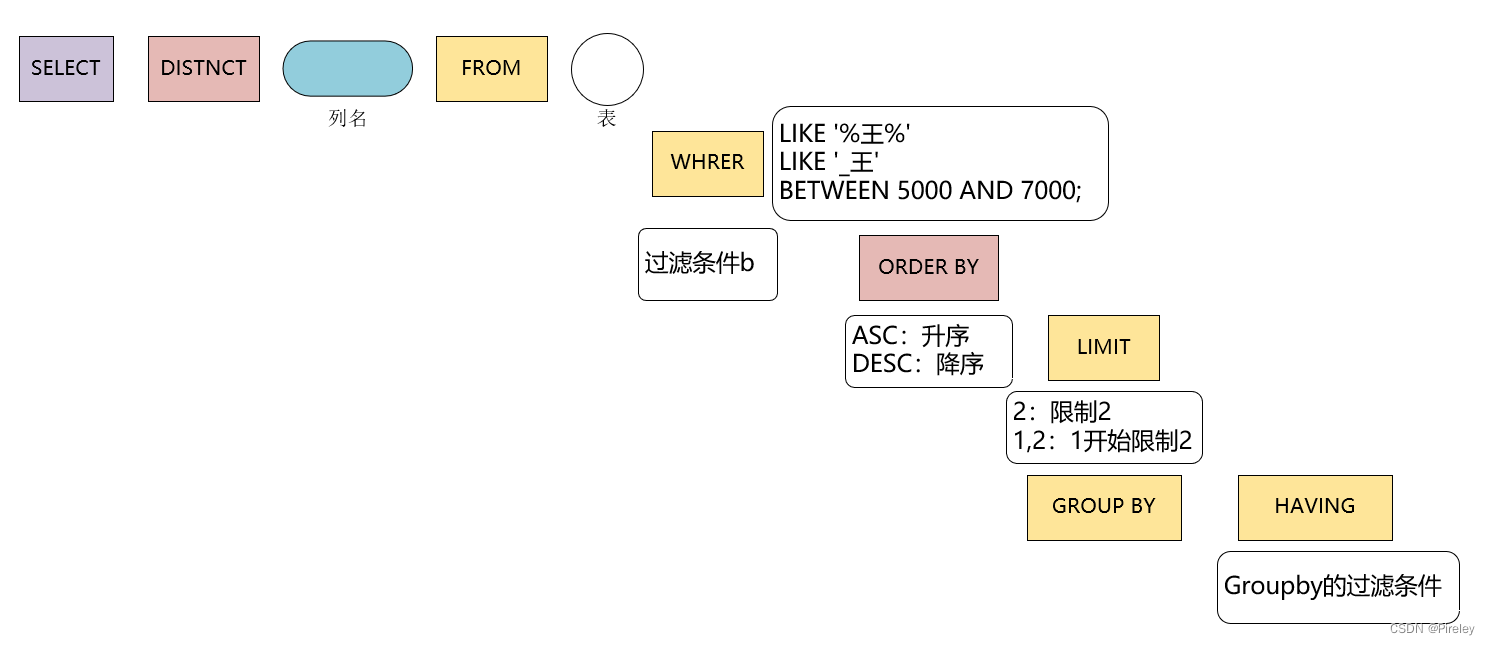
基本语句:SELECT … FROM
AS 别名:as可省略
SELECT e.emp_name 姓名,e.emp_phone AS 电话,emp_id,emp_sal FROM emp_table AS e;
所有字段:*
单表查询SQL语句
1. 创建数据库
SQL数据库的使用
INSERT INTO emp_tab(emp_name,emp_age) VALUES('张三',23);
SELECT * FROM emp_tab;
DELETE FROM emp_tab WHERE emp_id=8;
UPDATE emp_tab SET emp_gender = '女' WHERE emp_id=1;
快速增加数据
INSERT INTO emp_tab(emp_name,emp_age) SELECT emp_name,emp_age+1 FROM emp_tab;
删除数据
-- 先写入mysql的日志文件,然后从表中删除
-- 可恢复,效率低
-- 批量删除可选择:恢复删除和毁坏性删除
DELETE FROM emp_tab;
-- 毁坏性删除(真实项目不要用)
TRUNCATE TABLE emp_tab;
统计记录数量
select count(*) from emp_tab;
2. 基本查询
INSERT INTO emp_table(emp_name,emp_num,emp_phone) VALUES ('金','TJU0001','18834528');
INSERT INTO emp_table(emp_name,emp_num,emp_phone) VALUES ('金2','TJU0002','1883455');
INSERT INTO emp_table(emp_name,emp_num,emp_phone) VALUES ('金3','TJU0001','18803426');
-- 基本查询,查姓名,电话
SELECT emp_name 姓名,emp_phone AS 电话,emp_id,emp_sal FROM emp_table;
-- 表格变为e
SELECT e.emp_name 姓名,e.emp_phone AS 电话,emp_id,emp_sal FROM emp_table AS e;
-- 全查询
SELECT e.* FROM emp_table e;
3. 条件查询
SELECT * FROM emp_table AS e WHERE e.emp_id = 1;
SELECT * FROM emp_table AS e WHERE e.emp_sal >5005 AND e.emp_sal < 6000;
SELECT * FROM emp_table AS e WHERE e.emp_sal BETWEEN 5000 AND 7000;
SELECT * FROM emp_table AS e WHERE e.emp_age BETWEEN 25 AND 30;
4.模糊查询
| 通配符 | 作用 | 示例 | 语句 |
|---|---|---|---|
| % | 表示任意字符,0~n个 | 找出名字中有“王”,出现位置不确定 | LIKE ‘%王%’ |
| _ | 只能出现1次的任意字符 | 两个字,最后一个为王 | LIKE ‘_王’ |
-- 找出地址为空的id
SELECT e.emp_id FROM emp_table AS e WHERE e.emp_address is NOT NULL;
-- 找出名字中有“王”,出现位置不确定
-- 通配符 % 表示任意字符,0~n个
-- 名字中包含王
SELECT * FROM emp_table AS e WHERE e.emp_name LIKE '%王%';
-- 通配符 _ 只能出现1次的任意字符,
-- 两个字,最后一个为王
SELECT * FROM emp_table AS e WHERE e.emp_name LIKE '_王';
5. 排序
-- 排序
-- 升序 ASC,降序 DESC
SELECT * FROM emp_table AS e ORDER BY e.emp_age ASC;
SELECT * FROM emp_table AS e ORDER BY e.emp_age DESC;
6. 限制数量
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jicqNV4u-1683814545652)(D:\javalearn\思维导图笔记\mdPictures\image-20230511144701248.png)]](https://img-blog.csdnimg.cn/3e3d9930027142bb9f24b26bffe5b202.png)
-- 限制数量
-- limit 2 ,限制2个
-- LIMIT 1,2, 限制2个,从查询出结果的第几行开始,默认从0开始
SELECT * FROM emp_table AS e ORDER BY e.emp_age ASC LIMIT 2;
SELECT * FROM emp_table AS e ORDER BY e.emp_age ASC LIMIT 1,2;
7. SQL注入漏洞【重要】
输入:a = “admin” , b = “123’ OR 1=’1 “
-- SQL注入漏洞
SELECT * FROM user_table e WHERE e.user_username = 'admin' AND e.user_password ='123';
-- 加入 OR 1='1'
SELECT * FROM user_table e WHERE e.user_username = 'admin' AND e.user_password ='123' OR 1='1';
8. 聚合函数(统计)
-- 统计
SELECT sum(e.emp_sal) 工资总和 FROM emp_table e;
SELECT AVG(e.emp_sal) 平均工资 FROM emp_table e;
SELECT MAX(e.emp_sal) 最高工资 FROM emp_table e;
-- 工资大于6000的人数
SELECT COUNT(e.emp_id) FROM emp_table e WHERE e.emp_sal > 6000;
9. 分组查询
分组的过滤条件用HAVING
-- 分组
SELECT e.emp_status FROM emp_tab e GROUP BY e.emp_status;
-- 根据分组字段,显示分组内容,统计
SELECT COUNT(*) 人数, e.emp_status 状态 FROM emp_tab e GROUP BY e.emp_status;
SELECT COUNT(*) 人数, MAX(e.emp_sal) 工资, e.emp_status 状态 FROM emp_tab e GROUP BY e.emp_status;
-- 过滤分组
SELECT COUNT(*) 人数, MAX(e.emp_sal) 工资, e.emp_status 状态 FROM emp_tab e GROUP BY e.emp_status HAVING COUNT(*) > 100 ;
-- 计算平均工资,不得加入1000元以下的人
-- 先where再group by
SELECT COUNT(*) 人数, AVG(e.emp_sal) 平均工资, e.emp_status 状态 FROM emp_tab e
WHERE e.emp_sal > 1000
GROUP BY e.emp_status;
-- 计算低于5000的人的平均工资
SELECT COUNT(*) 人数, AVG(e.emp_sal) 平均工资 FROM emp_tab e WHERE e.emp_sal < 5000 GROUP BY e.emp_status;
-- 计算工资低于5000且年龄小于30的人数,按照状态分组,计算平均工资,最大工资
SELECT COUNT(*), AVG(e.emp_sal),e.emp_status FROM emp_tab e WHERE e.emp_age <= 30 AND e.emp_sal <=5000 GROUP BY e.emp_status;
10. 子查询(嵌套)
嵌套查询
-- 打印最高工资人的名字
-- 单个条件用 =
-- 如果条件多个用in
SELECT e.emp_name,e.emp_sal FROM emp_tab e WHERE e.emp_sal in
(
SELECT MAX(e.emp_sal) FROM emp_tab e
)
-- 1.找出工资最高的员工信息
SELECT * FROM emp_tab e WHERE e.emp_sal in (
SELECT MAX(e.emp_sal) FROM emp_tab e
)
-- 2.找出经理是小李和小张的所有员工
SELECT * FROM emp_tab e WHERE e.emp_manager in (
SELECT e.emp_manager FROM emp_tab e WHERE e.emp_manager = '小李' OR e.emp_manager = '小张'
)
SELECT * FROM emp_tab e WHERE e.emp_manager in (
SELECT e.emp_manager FROM emp_tab e WHERE e.emp_manager in ('小李','小张')
)
-- 3.找出小李和小张的所有员工数
SELECT COUNT(*) 人数, AVG(e.emp_sal) 平均工资 FROM emp_tab e WHERE e.emp_sal < 5000 GROUP BY e.emp_status;
SELECT COUNT(e.emp_id) 员工人数 FROM emp_tab e WHERE e.emp_manager in
(
SELECT e.emp_manager FROM emp_tab e WHERE e.emp_manager in ('小李','小张')
)
多表查询
1.笛卡尔积
-- 多表查询
SELECT * FROM dept_tab d WHERE d.dept_id =
(
SELECT e.emp_dept FROM emp_tab e WHERE e.emp_name = '施沛文'
)
-- 笛卡尔乘积
SELECT COUNT(*) FROM emp_tab,dept_tab;
2.内联结查询
-- 进行过滤,内联结
SELECT * FROM emp_tab e JOIN dept_tab d ON e.emp_dept = d.dept_id
SELECT * FROM emp_tab e ,dept_tab d WHERE e.emp_dept = d.dept_id
3.左联结查询
-- 只能查出有部门的员工
SELECT count(*) FROM
(SELECT * FROM emp_tab e ,dept_tab d WHERE e.emp_dept = d.dept_id) t
-- 查出所有员工的详细信息,两表合并
-- emp_tab 是主要表
SELECT e.*, d.* FROM emp_tab e LEFT JOIN dept_tab d ON e.emp_dept = d.dept_id
-- 统计员工数
SELECT count(t.emp_id) FROM (
SELECT e.*, d.* FROM emp_tab e LEFT JOIN dept_tab d ON e.emp_dept = d.dept_id
) t
-- 查询每个部门的员工,核心是部门
-- 先查部门,再查员工
SELECT d.*,e.* FROM dept_tab d LEFT JOIN emp_tab e ON d.dept_id = e.emp_dept;
4.多表查询语句
left join:以左边的表为基准,通过on的关联条件,查询右边的表来补充数据,如果查询不到,补充上null(重点)
select * from dept left join emp on emp.dept_id = dept.id
right join:以右边的表为基准,通过on的关联条件,查询左边的表来补充数据,如果查询不到,补充上null
select * from dept right join emp on emp.dept_id = dept.id
inner join:以两个表同时作为基准,通过on的关联条件,来查询数据,如果一边查询不到,不会显示该条数据
select * from emp a inner join dept b on a.dept_id=b.id
union:合并结果集(记录合并,自动去重)
select name,gender from head_teacher
union
select name,gender from teacher
union all:合并结果集(记录合并,全部保留)
select name,gender from head_teacher
union all
select name,gender from teacher
in(select 语句):子查询,子查询中的select语句只能返回一个字段
select * from emp where dept_id in (select id from dept where dept_name='内科' or dept_name='外科')
any:表示比较子查询结果集中的任意一条记录
select * from `group` where created_time> any(select created_time from dept)
all:表示比较子查询结果集中的所有的记录
select * from `group` where created_time> all(select created_time from dept)
练习作业
- 统计员工表中的所有工资高于3000.00的员工信息。
- 查询每个部门经理的员工人数。
- 查询某个员工的详细信息(员工信息+部门信息)
- 找出某个部门中的所有员工信息。
- 找出某几个部门的经理信息。
- 计算某个部门的平均工资。
- 查询出所有部门的所有员工信息。
-- 练习
-- 1.统计员工表中的所有工资高于3000.00的员工信息
SELECT * FROM emp_tab e WHERE e.emp_sal >= 3000;
SELECT COUNT(*) FROM emp_tab e WHERE e.emp_sal >= 3000;
-- 2.查询每个部门经理的员工人数。
SELECT e.emp_manager 经理姓名,COUNT(*) 员工人数 FROM emp_tab e GROUP BY e.emp_manager;
-- 3.查询某个员工的详细信息(员工信息+部门信息)
SELECT e.*,d.* FROM emp_tab e LEFT JOIN dept_tab d ON e.emp_dept = d.dept_id
WHERE e.emp_name = '郑念念';
-- 4.找出某个部门中的所有员工信息。
SELECT * FROM emp_tab e WHERE e.emp_dept = '2';
-- 获得所有部门
SELECT t.dept_name 部门, COUNT(*) 部门人数 FROM
(SELECT d.*,e.* FROM emp_tab e LEFT JOIN dept_tab d ON e.emp_dept = d.dept_id) t
GROUP BY t.dept_name
-- 5.找出某几个部门的经理信息。
-- 部门和经理数量
SELECT tb.dept_name 部门, COUNT(*) 经理数量 FROM
(
-- 获得经理和部门
SELECT t.emp_dept, t.dept_name, t.emp_manager FROM
(SELECT d.*,e.* FROM emp_tab e LEFT JOIN dept_tab d ON e.emp_dept = d.dept_id) t
) tb
GROUP BY tb.dept_name;
-- 如果找测试部和财务部的部门经理
SELECT t.dept_name 部门,t.emp_manager 经理 FROM
(SELECT d.*,e.* FROM emp_tab e LEFT JOIN dept_tab d ON e.emp_dept = d.dept_id) t
WHERE t.dept_name in ('测试部','研发部');
-- 6.计算某个部门的平均工资
-- 测试部平均工资
SELECT AVG(t.emp_sal)测试部工资 FROM
-- 测试部的表格
(SELECT d.*,e.* FROM emp_tab e LEFT JOIN dept_tab d ON e.emp_dept = d.dept_id) t
WHERE t.dept_name = '测试部';
-- 7.查询出所有部门的所有员工信息。
SELECT d.*,e.* FROM emp_tab e LEFT JOIN dept_tab d ON e.emp_dept = d.dept_id
1.去重
-- 部门经理去重
SELECT DISTINCT t.dept_name ,
t.emp_manager
FROM
( SELECT emp_tab.*, -- .*代表表中的所有信息
dept_tab.* FROM emp_tab LEFT JOIN dept_tab ON emp_tab.emp_dept = dept_tab.dept_id ) t
WHERE
t.dept_name = '研发部';
总结
1.SQL数据库基本概念;
2.数据库的三大范式,代理主键;
3.SQL的基本查询语句;
4.多表查询的语句;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/165170.html

