
前置知识
看图学源码之 volatile一:从 CPU缓存 到MESI 到 JMM 到 伪共享
volatile
是java 提供的一种最轻量级的同步机制
volatile 变量是可以保证可见性的,并且是对
所有线程的立即可见,即对 volatile 变量的读写是可以立即反映到其他线程的但是 volatile 不是线程安全的
volatile <=> unsafe.loadFence();
本质上:
- CPU 的内存屏障最终是在 C++ 的层面进行的,就是说 java 的 volatile 最终会由C++的 volatile 来进行保证,但是C++ 只会保证编译器不对 volatile 变量进行优化,数据的读取始终读的是内存中的最新的值
写volatile变量时会在变量赋值之后加入storeload屏障- 在汇编解释器中,Java的 volatile 的操作前面会加上编译器屏障保证编译器不优化代码,代码是什么顺序执行的时候就是什么顺序,进而保证可见性(只要禁止了编译器优化,那么一定可见)。
可见性的保证
可见性的保证: 缓存一致性协议
例子先行
public class Volatile_ {
private static int num = 0;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
num = 10;
System.out.println(Thread.currentThread().getName() + "\t" + num);
}).start();
System.out.println(Thread.currentThread().getName() + "\t" + num);
}
}
main 0
Thread-0 10
public class Volatile_ {
private volatile static int num = 0;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
num = 10;
System.out.println(Thread.currentThread().getName() + "\t come in");
System.out.println(Thread.currentThread().getName() + "\t" + num);
}).start();
System.out.println(Thread.currentThread().getName() + "\t" + num);
}
}
main 10
Thread-0 10
缓存一致性协议
当一个线程对共享变量进行写操作的时候,那么此时系统会发消息(MESI协议的消息机制确保)给其他CPU,CPU收到消息之后会将内存中的变量设置为无效。此时再进行读取数据的时候会发现这个共享变量的值是失效的,就从主存中读取这个消息。
那么是怎么发现的呢?
依赖于总线嗅探技术:每个CPU 会不断的嗅探总线上 传播的 数据来检查自己缓存的值是不是过期的,一旦cpu 发现自己的缓存行的地址发生了改变就会将当前处理器的缓存行设置为 无效,当前期再次对这个数据进行操作的时候,就会重新从主内存中把数据读取到 cpu缓存中了
会产生什么问题?
会产生 大量的交互,导致 总线的带宽达到峰值,所以不要滥用 volatile 关键字
JMM中的volatile规则:
- read、load、use动作必须连续出现。
- assign、store、write动作必须连续出现。
所以,使用volatile变量能够保证:
- 每次
读取前必须先从主内存刷新最新的值。 - 每次
写入后必须立即同步回主内存当中。
也就是说,volatile关键字修饰的变量看到的随时是自己的最新值。线程1中对变量v的最新修改,对线程2是可见的。
经典案例分析 DCL
//懒加载
class Singleton{
private static Singleton instance = null;
private Singleton() {
}
public static Singleton getInstance() {
if(instance == null){
instance = new Singleton(); // 这里存在竞态条件:会导致instance引用被多次赋值,使用户得到两个不同的单例。
}
return instance;
}
}
//解决: DCL
class Singleton{
private static volatile Singleton instance = null;
private Singleton() {
}
public synchronized static Singleton getInstance() {
if(instance == null){ //新问题:当instance不为null时,仍可能指向一个"被部分初始化的对象"。
synchronized (Singleton.class){
if(instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
出现问题的根源: instance = new Singleton();
JVM指令:
memory = allocate(); //1:分配对象的内存空间
initInstance(memory); //2:初始化对象(对f1、f2初始化)
instance = memory; //3:设置instance指向刚分配的内存地址
上述操作 2 依赖 操作 1 ,但是 操作3并不依赖于操作2,所以JVM可以以“优化”为目的对它们进行重排序,经过重排序后如下:
memory = allocate(); //1:分配对象的内存空间
instance = memory; //3:设置instance指向刚分配的内存地址
initInstance(memory); //2:初始化对象(对f1、f2初始化)
即引用instance指向内存memory时,这段崭新的内存还没有初始化——即,引用instance指向了一个”被部分初始化的对象”。此时,如果另一个线程调用getInstance方法,由于instance已经指向了一块内存空间,从而if条件判为false,方法返回instance引用,用户得到了没有完成初始化的“半个”单例。
解决:只需要将instance声明为volatile变量:
private static volatile Singleton instance;
在只有DCL没有volatile的懒加载单例模式中,仍然存在着并发陷阱。我确实不会拿到
两个不同的单例了,但我会拿到“半个”单例(未完成初始化)。
volatile 的可见性语义:
-
写入的 volatile 变量在
写完之后能被别的 CPU 在下一次读取中读取到;实现方式
- 读取 volatile 变量不能使用寄存器,每次读取都要去内存拿;
- 禁止 读 volatile 变量 后续操作被重排到读 volatile 之前;
-
写入 volatile 变量之前的操作,其他 CPU 要是看到 volatile 的最新值,那么也能看到写入 volatile 变量之前的操作;
实现方式
- 写 volatile 变量时的 Barrier 保证写 volatile 之前的操作先于写 volatile 变量之前发生
- 如果能用到 StoreLoad Barrier,写 volatile 后一般会触发 Store Buffer 的刷写,所以写操作能「 立即」被别的 CPU 看到
有序性的保证
有序性的保证: 内存屏障
指令重排序:
并不是指任意排序,而是在保证指令依赖的情况下的乱序执行,并可以保证得到正确的结果,比如:①a+1;②a *2;③b=0;④d=0;那么只要保证 ①②相对有序的前提下随意排序①②、③、④即可。
重排序的好处:
主要是编译器和处理器为提高计算机性能做的优化,与其等待阻塞指令(如等待缓存刷入)完成,不如先去执行其他指令。与处理器乱序执行相比,编译器重排序能够完成更大范围、效果更好的乱序优化。
重排序的分类:
- 编译器重排序: 编译器在生成机器码时,可以根据数据依赖性和控制依赖性进行指令重排序。
- 指令并行重排序:它们可以根据指令之间的无关性和依赖性进行指令重排序。乱序执行可以改变指令的执行顺序以提高流水线的利用率和指令级并行性。
- 内存重排序(Memory Reordering):处理器在执行读写内存操作时,可能会对内存的访问顺序进行重排序。这种重排序可以提高内存访问的效率,但可能会导致内存可见性问题,即多线程程序中的读写操作的顺序与程序代码中的顺序不一致。
正因为有重排序才导致了 普通变量 只可以在保证该方法的执行过程中所有依赖赋值结果的地方都能拿到正确的值,但是不能保证变量赋值的顺序和代码执行的顺序是一致的
volatile 禁止指令重排的原理
在生成的指令序列的前后加上 内存屏障 达到 禁止指令重排序的目的
屏障
硬件层的内存屏障:
- Load屏障,是x86上的
”ifence“指令,在读指令前插入ifence指令,可以让高速缓存中的数据失效,强制当前线程从主内存里面加载数据 - Store屏障,是x86的
”sfence“指令,在写指令后插入sfence指令,能让当前线程写入高速缓存中的最新数据,写入主内存,让其他线程可见。 - mfence:即全能屏障(modify/mix Barrier ),兼具sfence和lfence的功能
- lock 前缀:lock不是内存屏障,而是一种锁。执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU
JMM层的内存屏障:
内存屏障只需要保证store buffer(可以认为是寄存器与
L1 Cache间的一层缓存)与L1 Cache间的相干性
标准的屏障(是和硬件挂钩的)
- Store:将处理器缓存的数据刷新到内存中。
- Load:将内存存储的数据拷贝到处理器的缓存中。
| 屏障类型 | 简称 | 指令示例 | 说明 |
|---|---|---|---|
| LoadLoad Barriers | 读-读屏障 | Load1;LoadLoad;Load2 | 该屏障确保Load1数据的装载先于Load2及其后所有装载指令的的操作 |
| StoreStore Barriers | 写-写屏障 | Store1;StoreStore;Store2 | 该屏障确保Store1立刻刷新数据到内存(使其对其他处理器可见)的操作先于Store2及其后所有存储指令的操作 |
| LoadStore Barriers | 读-写屏障 | Load1;LoadStore;Store2 | 确保Load1的数据装载先于Store2及其后所有的存储指令刷新数据到内存的操作 |
| StoreLoad Barriers | 写-读屏障 | Store1:StoreLoad:Load2 | 该屏障确保Stor1立刻刷新数据到内存的操作先于Load2及其后所有装载装载指令的操作,它会使该屏障之前的所有内存访问指令(存储指令和访间指令)完成之后,才执行该屏障之后的内存访间。 |
StoreLoad Barriers同时具备其他三个屏障的效果,因此也称之为全能屏障(mfence)
规则:
- 线程每次
使用 volatile 修饰的变量的时候 都要先从主存中刷新最新的值,才能保证其他线程对变量所做的修改 - 线程修改完变量之后要
立即同步到主内存中,用于保证其他线程可以看到自己对 volatile 修饰的变量所做的修改 - volatile 修饰的变量
不会被指令重排序优化,可以保证代码的执行顺序和程序的顺序
- 当第
二个操作是volatile写时,不管第一个操作是什么,都不能重排。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。- 当第
一个操作是volatile读时,不管第二个操作是什么,都不能重排。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。- 当第
一个操作是volatile写,第二个操作是volatile读时,不能重排序
基于保守策略的JMM内存屏障插入策略
为了保证多线程程序的正确性和可靠性,编译器和处理器会在适当的位置插入内存屏障(Memory Barrier)来控制指令重排序和内存可见性
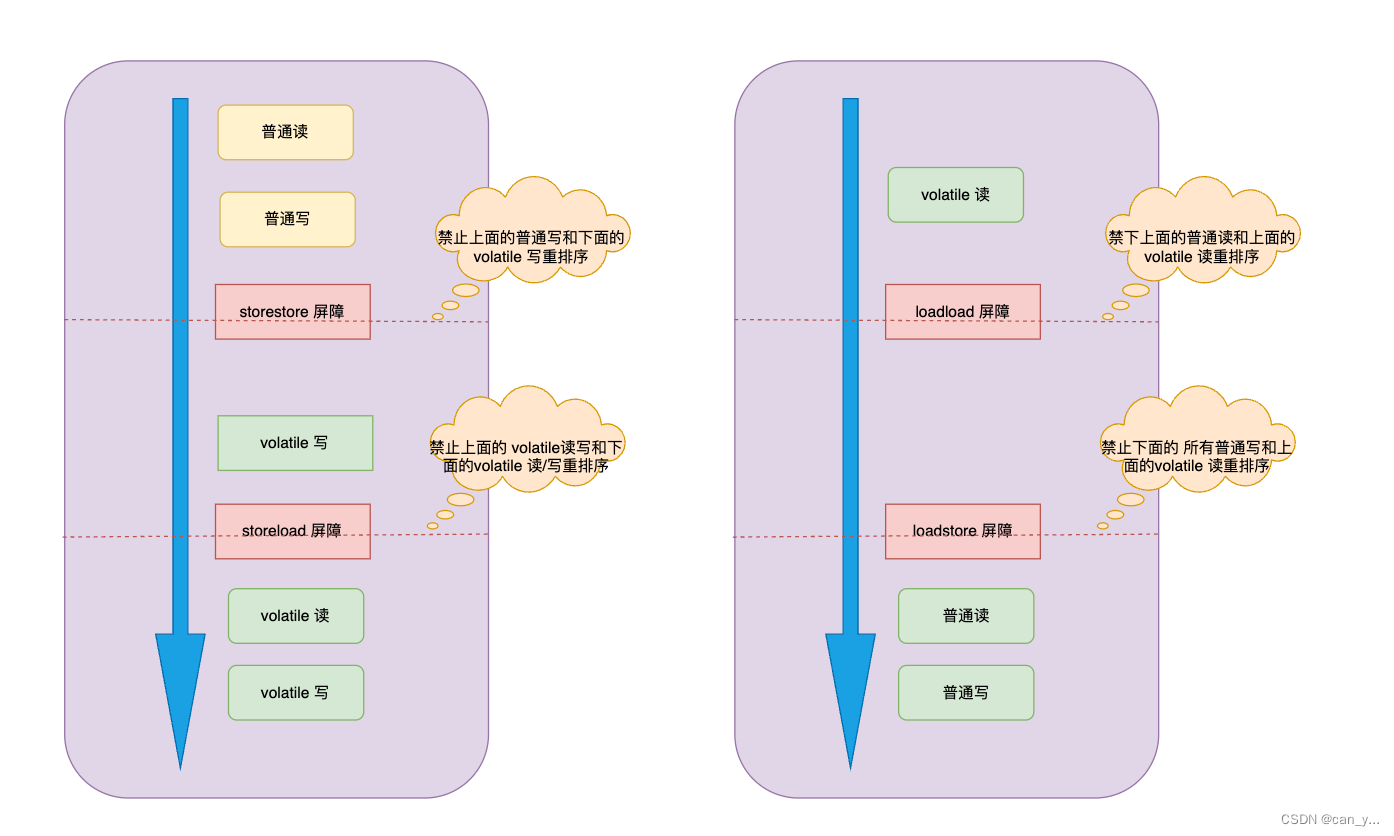
1、volatile写
怎么插入内存屏障的
- 在每个volatile写操作的
前面插入一个StoreStore屏障(写-写 屏障): 为了确保volatile写操作之前的所有存储操作都对其他线程可见,编译器和处理器会在每个volatile写操作之前插入StoreStore屏障,以防止volatile写操作与之前的存储操作重排序。- 在每个volatile写操作的
后面插入一个StoreLoad屏障(写-读 屏障):为了确保volatile写操作的结果对其他线程可见,编译器和处理器会在每个volatile写操作之后插入StoreLoad屏障,以防止volatile写操作与之后的加载操作重排序。
2、volatile读
如何插入内存屏障:
- 在每个volatile读操作的
后面插入一个LoadLoad 和 LoadStore屏障(读-读 和 读-写 屏障):为了确保volatile读操作的结果对其他线程可见,编译器和处理器会在每个volatile读操作之后插入LoadLoad和LoadStore屏障,以防止volatile读操作与之后的加载和存储操作重排序。
3、解锁时
在每个锁的解锁之前插入
StoreStore和StoreLoad屏障:为了确保锁的释放对其他线程可见,编译器和处理器会在每个锁的解锁操作之前插入StoreStore和StoreLoad屏障,以防止解锁操作与之前的存储和加载操作重排序。

无法保证原子性
static volatile int n = 0;
static void increase(){
n++;
}
public static void main(String[] args) {
for (int i = 0; i < 50; i++) {
new Thread(()->{
for (int j = 0; j < 1000; j++) {
increase();
}
}).start();
}
System.out.println(n);
}
}
48803 // 且每次的结果都不一样
字节码角度分析
static void increase(){
n++; //实际上包含了三条指令
}
0 getstatic #2 <com/ry/letusgo/forBAT/Volatile_.n : I> // 1、得到 n 的初始值
//(此时取到的是栈顶元素,volatile 可以保证该值在此时的正确性,但是后续执行 iconst_1 iadd 的时候就不能在多线程的情况下得到保证了,可能会有别的线程改变了这个变量的值,而操作栈顶的值就变为了过期的数据,就会在 最后进行put的时候把较小的值同步会主内存中了)
3 iconst_1
4 iadd // 2、执行++操作
5 putstatic #2 <com/ry/letusgo/forBAT/Volatile_.n : I> // 3、写回内存
8 return
解决方法就是 对
increase()加上锁 或者使用原子类进行累加
即:volatile 在不符合下面的条件的时候仍然是要加锁的:
- 运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值
- 变量不需要与其他的状态变量共同参与不变约束
特别说明:Long 和 double
允许虚拟机将没有被 volatile 修饰的64位数据的划分为 两次32位 的操作进行,允许虚拟机实现自行选择是否要保证64位数据类型的load、store、read、write 的四个操作的原子性。
要是有多个线程共享一个未被声明为 volatile 的 long 或者 double 的变量,并且同时对他们进行读取和修改操作,那么某些线程可能会读到一个既不是原值又不是其他线程修改值的 代表了“半个变量”的数值。但是这样的情况非常少见,《深入理解Java虚拟机》一本书说到:只有在32位的windows 系统才会有可能出现这样的情况;所以基本不需要为long double 专门声明为 volatile(除非有明显线程竞争)
源码分析:
字节码角度看
通过
javac 类名.java将类编译为class文件,再通过javap -v 类名.class命令反编译查看字节码文件
volatile和非 volatile变量没有任何区别,从Java虚拟机规范可知,某个字段是否是volatile变量是通过用来描述字段属性的access_flags来决定的,通过特定的标识位来识别(flags: ACC_PUBLIC, ACC_STATIC, ACC_VOLATILE)
static volatile int n = 0;
static volatile int n;
descriptor: I
flags: ACC_STATIC, ACC_VOLATILE
从javap的输出分析可知,并没有专门针对volatile变量的特殊字节码指令,其处理逻辑还是在属性读写的字节码指令中,相关的指令有四个: _getstatic/_putstatic,_getfield/_putfield
读操作
其实对于volatile变量来说,在读取的时候,并没有做处理。
_getstatic / _getfield适用于所有类型的字段属性读取;其实对于volatile变量来说,在读取的时候,并没有做处理
void TemplateTable::getfield(int byte_no) {
getfield_or_static(byte_no, false);
}
/*
此函数的主要作用是获取字段或静态变量的值。
首先,它通过resolve_cache_and_index解析缓存和索引,然后通过jvmti_post_field_access发布jvmti事件,
接着通过load_field_cp_cache_entry加载字段的偏移量和标志。
然后,根据字段的类型,从内存中加载字段的值,并将其压入栈顶。如果字段不是静态的,那么还会重写字节码以提高执行速度。
最后,跳转到Done标签,结束函数的执行
*/
void TemplateTable::getfield_or_static(int byte_no, bool is_static) {
// 状态转换,从栈顶到栈顶
transition(vtos, vtos);
// 定义一些寄存器
const Register cache = rcx;
const Register index = rdx;
const Register obj = c_rarg3;
const Register off = rbx;
const Register flags = rax;
const Register bc = c_rarg3; // 使用与obj相同的寄存器,所以不要混淆它们
// 解析缓存和索引
resolve_cache_and_index(byte_no, cache, index, sizeof(u2));
// 发布jvmti事件
jvmti_post_field_access(cache, index, is_static, false);
// 加载该字段的偏移量,flags,如果是静态字段还需要解析该类class实例对应的oop
load_field_cp_cache_entry(obj, cache, index, off, flags, is_static);
if (!is_static) {
// obj在栈上,将被读取属性的oop放入obj中
pop_and_check_object(obj);
}
// 创建一个field地址对象
const Address field(obj, off, Address::times_1);
// 定义一些标签
Label Done, notByte, notInt, notShort, notChar,
notLong, notFloat, notObj, notDouble;
// 将flags右移
__ shrl(flags, ConstantPoolCacheEntry::tos_state_shift);
// 确保我们在上述移位后不需要屏蔽edx
assert(btos == 0, "change code, btos != 0");
// 对flags进行与操作
__ andl(flags, ConstantPoolCacheEntry::tos_state_mask);
// 判断是否是byte类型
__ jcc(Assembler::notZero, notByte);
// btos
// 读取该属性,并放入rax中
__ load_signed_byte(rax, field);
// 将btos压入栈顶
__ push(btos);
// 重写字节码以提高执行速度
if (!is_static) {
// 将该指令改写成_fast_bgetfield,下一次执行时就会更快
patch_bytecode(Bytecodes::_fast_bgetfield, bc, rbx);
}
// 跳转到Done标签
__ jmp(Done);
// 对于其他类型的处理逻辑类似,这里就不一一注释了
__ bind(notInt);
__ cmpl(flags, ctos);
__ jcc(Assembler::notEqual, notChar);
// ctos
__ load_unsigned_short(rax, field);
__ push(ctos);
// Rewrite bytecode to be faster
if (!is_static) {
patch_bytecode(Bytecodes::_fast_cgetfield, bc, rbx);
}
__ jmp(Done);
__ bind(notChar);
__ cmpl(flags, stos);
__ jcc(Assembler::notEqual, notShort);
// stos
__ load_signed_short(rax, field);
__ push(stos);
// Rewrite bytecode to be faster
if (!is_static) {
patch_bytecode(Bytecodes::_fast_sgetfield, bc, rbx);
}
__ jmp(Done);
__ bind(notShort);
__ cmpl(flags, ltos);
__ jcc(Assembler::notEqual, notLong);
// ltos
__ movq(rax, field);
__ push(ltos);
// Rewrite bytecode to be faster
if (!is_static) {
patch_bytecode(Bytecodes::_fast_lgetfield, bc, rbx);
}
__ jmp(Done);
__ bind(notLong);
__ cmpl(flags, ftos);
__ jcc(Assembler::notEqual, notFloat);
// ftos
__ movflt(xmm0, field);
__ push(ftos);
// Rewrite bytecode to be faster
if (!is_static) {
patch_bytecode(Bytecodes::_fast_fgetfield, bc, rbx);
}
__ jmp(Done);
__ bind(notFloat);
#ifdef ASSERT
__ cmpl(flags, dtos);
__ jcc(Assembler::notEqual, notDouble);
#endif
// dtos
__ movdbl(xmm0, field);
__ push(dtos);
// Rewrite bytecode to be faster
if (!is_static) {
patch_bytecode(Bytecodes::_fast_dgetfield, bc, rbx);
}
#ifdef ASSERT
__ jmp(Done);
__ bind(notDouble);
__ stop("Bad state");
#endif
__ bind(Done);
// [jk] 目前不需要
// volatile_barrier(Assembler::Membar_mask_bits(Assembler::LoadLoad |
// Assembler::LoadStore));
}
/*
此函数的主要作用是快速访问字段。
首先,它进行状态转换,然后如果JVMTI导出可以发布字段访问事件,它会检查是否设置了字段访问监视,如果设置了,就调用VM来处理。
接着,它获取常量池缓存和索引,然后用缓存条目中的字段偏移量替换索引。
然后,它验证并检查对象是否为null,创建一个表示字段地址的对象。
最后,根据字节码类型,从内存中加载字段的值。
*/
void TemplateTable::fast_accessfield(TosState state) {
// 状态转换,从对象引用到特定的类型
transition(atos, state);
// 在这里完成JVMTI的工作,以避免干扰下面的寄存器状态
if (JvmtiExport::can_post_field_access()) {
// 在我们花时间调用VM之前,检查是否设置了字段访问监视
Label L1;
__ mov32(rcx, ExternalAddress((address) JvmtiExport::get_field_access_count_addr()));
__ testl(rcx, rcx);
__ jcc(Assembler::zero, L1);
// 访问常量池缓存条目
__ get_cache_entry_pointer_at_bcp(c_rarg2, rcx, 1);
__ verify_oop(rax);
__ push_ptr(rax); // 在call_VM()破坏它之前保存对象指针
__ mov(c_rarg1, rax);
// c_rarg1: 对象指针在上面复制
// c_rarg2: 缓存条目指针
__ call_VM(noreg,
CAST_FROM_FN_PTR(address,
InterpreterRuntime::post_field_access),
c_rarg1, c_rarg2);
__ pop_ptr(rax); // 恢复对象指针
__ bind(L1);
}
// 访问常量池缓存
__ get_cache_and_index_at_bcp(rcx, rbx, 1);
// 用缓存条目中的字段偏移量替换索引
__ movptr(rbx, Address(rcx, rbx, Address::times_8,
in_bytes(ConstantPoolCache::base_offset() +
ConstantPoolCacheEntry::f2_offset())));
// rax: 对象
__ verify_oop(rax);
__ null_check(rax);
Address field(rax, rbx, Address::times_1);
// 访问字段
switch (bytecode()) {
case Bytecodes::_fast_agetfield:
__ load_heap_oop(rax, field);
__ verify_oop(rax);
break;
// 其他类型的处理逻辑类似,这里就不一一注释了
case Bytecodes::_fast_lgetfield:
__ movq(rax, field);
break;
case Bytecodes::_fast_igetfield:
__ movl(rax, field);
break;
case Bytecodes::_fast_bgetfield:
__ movsbl(rax, field);
break;
case Bytecodes::_fast_sgetfield:
__ load_signed_short(rax, field);
break;
case Bytecodes::_fast_cgetfield:
__ load_unsigned_short(rax, field);
break;
case Bytecodes::_fast_fgetfield:
__ movflt(xmm0, field);
break;
case Bytecodes::_fast_dgetfield:
__ movdbl(xmm0, field);
break;
default:
ShouldNotReachHere();
}
}
写操作
_putstatic / _putfield 这两个字节码指令用于写入静态属性或者实例属性
void TemplateTable::putfield(int byte_no) {
putfield_or_static(byte_no, false);
}
void TemplateTable::putstatic(int byte_no) {
putfield_or_static(byte_no, true);
}
/*
此函数的主要作用是将值写入字段或静态变量。
首先,它通过resolve_cache_and_index解析缓存和索引,然后通过jvmti_post_field_mod发布jvmti事件,
接着通过load_field_cp_cache_entry加载字段的偏移量和标志。
然后,根据字段的类型,从栈顶弹出一个值,然后将这个值写入字段。如果字段不是静态的,那么还会重写字节码以提高执行速度。
最后,如果字段是volatile的,它会执行一个内存屏障,然后跳转到notVolatile标签,结束函数的执行。
*/
void TemplateTable::putfield_or_static(int byte_no, bool is_static) {
// 状态转换,从栈顶到栈顶
transition(vtos, vtos);
// 定义一些寄存器
const Register cache = rcx;
const Register index = rdx;
const Register obj = rcx;
const Register off = rbx;
const Register flags = rax;
const Register bc = c_rarg3;
// 解析缓存和索引
resolve_cache_and_index(byte_no, cache, index, sizeof(u2));
// 发布jvmti事件
jvmti_post_field_mod(cache, index, is_static);
// 加载该字段的偏移量,flags,如果是静态字段还需要解析该类class实例对应的oop
load_field_cp_cache_entry(obj, cache, index, off, flags, is_static);
// 创建一些标签
Label notVolatile, Done;
__ movl(rdx, flags);
__ shrl(rdx, ConstantPoolCacheEntry::is_volatile_shift);
__ andl(rdx, 0x1);
// 字段地址
const Address field(obj, off, Address::times_1);
// 创建一些标签
Label notByte, notInt, notShort, notChar,
notLong, notFloat, notObj, notDouble;
// 对flags进行右移操作
__ shrl(flags, ConstantPoolCacheEntry::tos_state_shift);
// 确保我们在上述移位后不需要屏蔽edx
assert(btos == 0, "change code, btos != 0");
// 对flags进行与操作
__ andl(flags, ConstantPoolCacheEntry::tos_state_mask);
// 判断是否是byte类型
__ jcc(Assembler::notZero, notByte);
// btos
{
// 从栈顶弹出一个btos
__ pop(btos);
// 如果不是静态的,弹出并检查对象
if (!is_static) pop_and_check_object(obj);
// 将rax的值写入字段
__ movb(field, rax);
// 如果不是静态的,将字节码改写为更快的版本
if (!is_static) {
patch_bytecode(Bytecodes::_fast_bputfield, bc, rbx, true, byte_no);
}
// 跳转到Done标签
__ jmp(Done);
}
// 对于其他类型的处理逻辑类似,这里就不一一注释了
__ bind(notByte);
__ cmpl(flags, atos);
__ jcc(Assembler::notEqual, notObj);
// atos
{
__ pop(atos);
if (!is_static) pop_and_check_object(obj);
// Store into the field
do_oop_store(_masm, field, rax, _bs->kind(), false);
if (!is_static) {
patch_bytecode(Bytecodes::_fast_aputfield, bc, rbx, true, byte_no);
}
__ jmp(Done);
}
__ bind(notObj);
__ cmpl(flags, itos);
__ jcc(Assembler::notEqual, notInt);
// itos
{
__ pop(itos);
if (!is_static) pop_and_check_object(obj);
__ movl(field, rax);
if (!is_static) {
patch_bytecode(Bytecodes::_fast_iputfield, bc, rbx, true, byte_no);
}
__ jmp(Done);
}
__ bind(notInt);
__ cmpl(flags, ctos);
__ jcc(Assembler::notEqual, notChar);
// ctos
{
__ pop(ctos);
if (!is_static) pop_and_check_object(obj);
__ movw(field, rax);
if (!is_static) {
patch_bytecode(Bytecodes::_fast_cputfield, bc, rbx, true, byte_no);
}
__ jmp(Done);
}
__ bind(notChar);
__ cmpl(flags, stos);
__ jcc(Assembler::notEqual, notShort);
// stos
{
__ pop(stos);
if (!is_static) pop_and_check_object(obj);
__ movw(field, rax);
if (!is_static) {
patch_bytecode(Bytecodes::_fast_sputfield, bc, rbx, true, byte_no);
}
__ jmp(Done);
}
__ bind(notShort);
__ cmpl(flags, ltos);
__ jcc(Assembler::notEqual, notLong);
// ltos
{
__ pop(ltos);
if (!is_static) pop_and_check_object(obj);
__ movq(field, rax);
if (!is_static) {
patch_bytecode(Bytecodes::_fast_lputfield, bc, rbx, true, byte_no);
}
__ jmp(Done);
}
__ bind(notLong);
__ cmpl(flags, ftos);
__ jcc(Assembler::notEqual, notFloat);
// ftos
{
__ pop(ftos);
if (!is_static) pop_and_check_object(obj);
__ movflt(field, xmm0);
if (!is_static) {
patch_bytecode(Bytecodes::_fast_fputfield, bc, rbx, true, byte_no);
}
__ jmp(Done);
}
__ bind(notFloat);
#ifdef ASSERT
__ cmpl(flags, dtos);
__ jcc(Assembler::notEqual, notDouble);
#endif
// dtos
{
__ pop(dtos);
if (!is_static) pop_and_check_object(obj);
__ movdbl(field, xmm0);
if (!is_static) {
patch_bytecode(Bytecodes::_fast_dputfield, bc, rbx, true, byte_no);
}
}
#ifdef ASSERT
__ jmp(Done);
__ bind(notDouble);
__ stop("Bad state");
#endif
__ bind(Done);
// 检查是否为volatile存储
__ testl(rdx, rdx);
__ jcc(Assembler::zero, notVolatile);
// 如果是volatile存储,执行内存屏障
volatile_barrier(Assembler::Membar_mask_bits(Assembler::StoreLoad |
Assembler::StoreStore));
__ bind(notVolatile);
}
/* 此函数的主要作用是快速将值写入字段;
首先,它进行状态转换,然后如果JVMTI导出可以发布字段修改事件,它会检查是否设置了字段修改监视,如果设置了,就调用VM来处理。
接着,它获取常量池缓存和索引,然后用缓存条目中的字段偏移量替换索引。然后,它从栈中弹出一个对象,并检查对象是否为null。
接着,根据字节码类型,将一个值写入字段。
最后,如果字段是volatile的,它会执行一个内存屏障,然后跳转到notVolatile标签,结束函数的执行
*/
void TemplateTable::fast_storefield(TosState state) {
// 状态转换,从特定类型到栈顶
transition(state, vtos);
ByteSize base = ConstantPoolCache::base_offset();
// 发布jvmti事件
jvmti_post_fast_field_mod();
// 访问常量池缓存
__ get_cache_and_index_at_bcp(rcx, rbx, 1);
// 使用rdx测试是否易失
__ movl(rdx, Address(rcx, rbx, Address::times_8,
in_bytes(base +
ConstantPoolCacheEntry::flags_offset())));
// 用缓存条目中的字段偏移量替换索引
__ movptr(rbx, Address(rcx, rbx, Address::times_8,
in_bytes(base + ConstantPoolCacheEntry::f2_offset())));
Label notVolatile;
__ shrl(rdx, ConstantPoolCacheEntry::is_volatile_shift);
__ andl(rdx, 0x1);
// 从栈中获取对象
pop_and_check_object(rcx);
// 字段地址
const Address field(rcx, rbx, Address::times_1);
// 访问字段
switch (bytecode()) {
case Bytecodes::_fast_aputfield:
do_oop_store(_masm, field, rax, _bs->kind(), false);
break;
// 其他类型的处理逻辑类似,这里就不一一注释了
case Bytecodes::_fast_lputfield:
__ movq(field, rax);
break;
case Bytecodes::_fast_iputfield:
__ movl(field, rax);
break;
case Bytecodes::_fast_bputfield:
__ movb(field, rax);
break;
case Bytecodes::_fast_sputfield:
// fall through
case Bytecodes::_fast_cputfield:
__ movw(field, rax);
break;
case Bytecodes::_fast_fputfield:
__ movflt(field, xmm0);
break;
case Bytecodes::_fast_dputfield:
__ movdbl(field, xmm0);
break;
default:
ShouldNotReachHere();
}
// 检查是否为volatile存储
__ testl(rdx, rdx);
__ jcc(Assembler::zero, notVolatile);
// 如果是volatile存储,执行内存屏障
volatile_barrier(Assembler::Membar_mask_bits(Assembler::StoreLoad |
Assembler::StoreStore));
__ bind(notVolatile);
}
底层中实际执行的方法: fast_storefield还是 putfield_or_static 他们都判断了是否是 volatile变量,然后执行了 volatile_barrier方法。
void TemplateTable:volatile_barrier(Assembler:Membar_mask_bitsorder_constraint){
if(os::1sMP()){//如果是多处理器系统
membar(order_constraint);
}
}
void membar(Membar_mask_bits order_constraint){
if (os::is_MP()){
//只要包含StoreLoad
if (order_constraint StoreLoad){
//Lock是一个指令前缀,实际执行的一条指令lock add1$0x0,(%rsp);
lock();
addl(Address(rsp,0),0);//Assert the lock#signal here
}
}
}
我们来看一下 volatile_barrier 方法做了什么:
在多处理器系统中使用内存屏障来保证 volatile 变量的有序性。
通过使用 membar 函数中的 lock 指令,可以确保 StoreLoad 操作的原子性,从而避免竞态条件和不确定的结果
HotSpot 源码角度
Java中,静态属性属于类的。操作静态属性,对应的指令为
putstatic
openjdk8根路径/hotspot/src/share/vm/interpreter路径下的bytecodeInterpreter.cpp文件中,处理putstatic和putfield指令的代码:
CASE(_putstatic):
{
...
int field_offset = cache->f2_as_index();
// cache->is_volatile() -- 判断是否有volatile访问标志修饰
// 调用的是openjdk8根路径/hotspot/src/share/vm/utilities路径下的accessFlags.hpp文件中的方法
if (cache->is_volatile()) {
/*
// Java access flags
bool is_public () const { return (_flags & JVM_ACC_PUBLIC ) != 0; }
bool is_private () const { return (_flags & JVM_ACC_PRIVATE ) != 0; }
bool is_protected () const { return (_flags & JVM_ACC_PROTECTED ) != 0; }
bool is_static () const { return (_flags & JVM_ACC_STATIC ) != 0; }
bool is_final () const { return (_flags & JVM_ACC_FINAL ) != 0; }
bool is_synchronized() const { return (_flags & JVM_ACC_SYNCHRONIZED) != 0; }
bool is_super () const { return (_flags & JVM_ACC_SUPER ) != 0; }
bool is_volatile () const { return (_flags & JVM_ACC_VOLATILE ) != 0; }
bool is_transient () const { return (_flags & JVM_ACC_TRANSIENT ) != 0; }
bool is_native () const { return (_flags & JVM_ACC_NATIVE ) != 0; }
bool is_interface () const { return (_flags & JVM_ACC_INTERFACE ) != 0; }
bool is_abstract () const { return (_flags & JVM_ACC_ABSTRACT ) != 0; }
*/
// volatile变量的赋值逻辑
// 下面一系列的if...else...对tos_type字段的判断处理;是针对java基本类型和引用类型的赋值处理
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
/*
//调用的是openjdk8根路径/hotspot/src/share/vm/oops路径下的oop.inline.hpp文件中的方法
jlong oopDesc::long_field_acquire(int offset) const {
return Atomic::load_acquire(field_addr<jlong>(offset));
}
void oopDesc::release_long_field_put(int offset, jlong value){
Atomic::release_store(field_addr<jlong>(offset), value);
注意:
//OrderAccess是定义在openjdk8根路径/hotspot/src/share/vm/runtime路径下的orderAccess.hpp头文件下的方法,具体的实现是根据不同的操作系统和不同的cpu架构,有不同的实现
强烈建议读一遍orderAccess.hpp文件中30-240行的注释!!!
inline void OrderAccess:release_store(volatile jbyte* p,jbyte v){*p = v;}
/*
// 直接使用了 C/C++ 的 volatile 关键字
inline T Atomic::load_acquire(const volatile T* p) {
return LoadImpl<T, PlatformOrderedLoad<sizeof(T), X_ACQUIRE> >()(p);
}
// 直接使用了 C/C++ 的 volatile 关键字
template <typename D, typename T> inline void Atomic::release_store(volatile D* p, T v) {
StoreImpl<D, T, PlatformOrderedStore<sizeof(D), RELEASE_X> >()(p, v);
}
*/
}
*/
} else if (tos_type == atos) {// 对象类型赋值 if...else...对tos_type字段的判断处理之后
VERIFY_OOP(STACK_OBJECT(-1));
obj->release_obj_field_put(field_offset, STACK_OBJECT(-1));
OrderAccess::release_store(&BYTE_MAP_BASE[(uintptr_t)obj >> CardTableModRefBS::card_shift], 0);
} else if (tos_type == btos) {// byte类型赋值
obj->release_byte_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ltos) {// long类型赋值
obj->release_long_field_put(field_offset, STACK_LONG(-1));
} else if (tos_type == ctos) {// char类型赋值
obj->release_char_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == stos) {// short类型赋值
obj->release_short_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ftos) {// float类型赋值
obj->release_float_field_put(field_offset, STACK_FLOAT(-1));
} else {// double类型赋值
obj->release_double_field_put(field_offset, STACK_DOUBLE(-1));
}
****************************** 写完值后的storeload屏障 ************
OrderAccess::storeload();
} else {
// 非volatile变量的赋值逻辑
if (tos_type == itos) {
obj->int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {
VERIFY_OOP(STACK_OBJECT(-1));
obj->obj_field_put(field_offset, STACK_OBJECT(-1));
OrderAccess::release_store(&BYTE_MAP_BASE[(uintptr_t)obj >> CardTableModRefBS::card_shift], 0);
} else if (tos_type == btos) {
obj->byte_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ltos) {
obj->long_field_put(field_offset, STACK_LONG(-1));
} else if (tos_type == ctos) {
obj->char_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == stos) {
obj->short_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ftos) {
obj->float_field_put(field_offset, STACK_FLOAT(-1));
} else {
obj->double_field_put(field_offset, STACK_DOUBLE(-1));
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(3, count);
}
//此方法 依然是声明在orderAccess.hpp头文件中,在不同操作系统或cpu架构下有不同的实现。
// barriers 屏障
static void loadload();
static void storestore();
static void loadstore();
static void storeload();
static void acquire();
static void release();
static void fence();
//具体的linux 的实现为: 编译器屏障,强制 C++ 编译器使所有内存假设无效
static inline void compiler_barrier() {
__asm__ volatile ("" : : : "memory");
}
inline void OrderAccess::loadload() { compiler_barrier(); }
inline void OrderAccess::storestore() { compiler_barrier(); }
inline void OrderAccess::loadstore() { compiler_barrier(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() { compiler_barrier(); }
inline void OrderAccess::release() { compiler_barrier(); }
...
inline void OrderAccess::fence() {
//首先使用SMP()判断处理器是单核还是多核,如果是单核就没必要每次使用内存屏障,反而更消耗资源
if (os:is_MP()){
#ifdef AMD64
///Lock汇编指令,Lock指令会锁住操作的缓存行。
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
compiler_barrier();
}
}
这里的意思是: 不建议我们使用我们的原语指令 mfence(内存屏障) ,因为 mfence 的资源消耗要比 locked 资源消耗的多;直接判断是不是 AMD64 来对其不同的寄存器 rsp\esp做处理;所以底层方法中 无论如何__asm__ volatile ("" : : : "memory"); 还是 __asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory")完成的效果一样,都是禁止编译器进行优化,并且从内存取数据,而不要从寄存器取数据
简单说就是: 告诉我们的CPU,不要优化了,就要串行执行。
其中: addl $0,0(%%rsp) 是把寄存器的值加0,相当于一个空操作(之所以用它,不用空操作专用指令nop,是因为lock前缀不允许配合nop指令使用)
整段代码的意思是:在执行内存屏障操作时,使用原子操作的方式将0与栈指针所指向的内存地址上的值相加,以确保内存操作的顺序和一致性,并通过编译器屏障来防止指令重排优化。
源码角度的核心就是:
lock前缀作用:
1、会保证某个处理器对共享内存的独占使用,即流水线式的顺序执行
2、它将本处理器缓存写入内存,该写入操作会引起其他处理器或内核对应的缓存失效。
3、通过独占内存、使其他处理器缓存失效,达到了“指令重排序无法越过内存屏障”的作用
CPU的角度
Intel 的原语指令:
mfence内存屏障,ifence读屏障,sfence写屏障
Store Barrier
sfence指令实现了Store Barrier,相当于StoreStore Barriers。禁止对sfence指令前后store指令的重排序跨越sfence指令,使所有Store Barrier之前发生的内存更新都是可见的。
Load Barrier
lfence指令实现了Load Barrier,相当于LoadLoad Barriers。禁止对lfence指令前后load指令的重排序跨越lfence指令,配合Store Barrier,使所有Store Barrier之前发生的内存更新,对Load Barrier之后的load操作都是可见的。
Full Barrier
mfence指令实现了Full Barrier,相当于StoreLoad Barriers。禁止对mfence指令前后store/load指令的重排序跨越mfence指令,使**所有Full Barrier之前发生的操作,对所有Full Barrier之后的操作都是可见的。
总结:
volatile:
- 无法保证原子性
- 可以保证可见性:MESI
- 可以保证顺序性:内存屏障
-
volatile 修饰的变量可以立即被所有线程看见,依赖于 JMM中的volatile规则:
read、load、use动作必须连续出现。assign、store、write动作必须连续出现。所以 读取的时候可以直接从内存中读取数据,写的时候可以直接刷新会主存中 -
正是因为 内存屏障的出现 才实现了 禁止指令重排序。
源码分析:
字节码层面上会有 :
-
和普通变量通过
flags标志位,ACC_PUBLIC, ACC_STATIC, ACC_VOLATILE -
处理逻辑还是
_putstatic/_getstatic/_getfield/_putfield这四条指令相关
hotspot源码层面上会有 : 【jdk源码包下面的底层代码】
顺序性:
- 先进行判断是否有volatile访问标志修饰
- 然后进行volatile变量的赋值逻辑,其中会调用c++方法,在该方法中直接使用了 C/C++ 的 volatile 关键字 修饰的变量【C/C++中的volatile关键字,相当于
对这个变量前后插入了内存屏障,其核心作用就是禁止编译器对于这个变量/代码块进行任何优化,禁止重排序、禁止使用寄存器而不取内存值、禁止编译器将其认为无用的代码优化掉。】 - 写完值后会执行
storeload屏障【底层还有别的屏障acquire、storestore...的声明】,各个屏障具体实现是有jdk 源码下的的linux包中实现的
可见性
对于volatile变量来说,处理逻辑还是 _putstatic/_getstatic/_getfield/_putfield这四条指令相关,在读取_get...的时候,并没有做处理,但是在写的是时候_put...,会对 volatile 变量执行volatile_barrier,这个方法会在属性修改完成后,就会执行lock addl $0×0,(%rsp);
lock前缀作用:
1、会保证某个处理器对共享内存的独占使用,即流水线式的顺序执行
2、它将本处理器缓存写入内存,该写入操作会引起其他处理器或内核对应的缓存失效。
3、通过独占内存、使其他处理器缓存失效,达到了“指令重排序无法越过内存屏障”的作用
这样volatile 其他cpu读取的时候就会直接从内存当中加载,而不是使用自己的缓存。
cpu层面上会有 :
三个屏障:mfence内存屏障,ifence读屏障,sfence写屏障,他们的作用都是进行屏障前后的指令重排序,并使屏障之前发生的所有操作对屏障之后的操作可见。
并且对于方法OrderAccess::fence()会对不同架构进行判断,在执行内存屏障操作时,使用原子操作的方式将0与栈指针所指向的内存地址上的值相加,以确保内存操作的顺序和一致性,并通过编译器屏障来防止指令重排优化。——禁止重排序
MESI:
有了缓存一致性协议,还需要volatile吗?
需要
- 并不是所有的硬件架构都提供了相同的一致性保证,JVM需要volatile统一语义
- MESI协议解决了CPU缓存层面的可见性问题,但是可见性问题不仅仅局限于CPU缓存内;JVM自己维护的内存模型中也有可见性问题。使用volatile做标记,可以解决JVM层面的可见性问题。
- 如果不考虑重排序,MESI确实解决了CPU缓存层面的可见性问题;然而,编译器重排序和处理器重排序也会导致可见性问题
内存屏障
作用
内存屏障(Memory Barrier)与内存栅栏(Memory Fence)是同一个概念,不同的叫法,通过volatile标记,可以解决编译器层面的可见性与重排序问题。而内存屏障则解决了硬件层面的可见性与重排序问题。
扩展:
针对上面的:强烈建议读一遍orderAccess.hpp文件中
30-240行的注释!!! 翻译为下;为减少阅读负担,主要内容为:
runtime/orderAccess.hpp
// 内存访问排序模型
// 它是动态等效的C/C++ volatile 的。即,波动性以类似于我们希望在运行时发生的方式限制 编译时 内存访问重新排序。
//说明:
// 术语 'previous'、'subsequent'、 'before'、 'after'、'preceding' 和 'succeeding' 指的是程序顺序。这
// 术语'down' 、 'below'是指相对于程序顺序的向前 load 或 store 运动,而'up' and 'above'是指向后运动。。
//
// 我们定义了四种原始内存屏障操作。
//
LoadLoad: Load1(s); LoadLoad; Load2
// 确保 Load1 完成(获取从内存加载的值)在 Load2 和任何后续加载操作之前。Load1 之前的load可能“不”浮动在 Load2 和任何后续load 操作之下
StoreStore: Store1(s); StoreStore; Store2
// 确保 Store1 在 Store2 和任何后续存储操作之前完成(Store1 对内存的影响对其他处理器可见)。 Store1之前的store 可能“不”浮动在 Store2 和任何后续 store 操作之下。
LoadStore: Load1(s); LoadStore; Store2
// 确保 Load1 在 Store2 和任何后续存储操作之前完成。 Load1 之前的 load 可能“不”浮动在 Store2 和任何后续 store 操作之下。
StoreLoad: Store1(s); StoreLoad; Load2
//确保 Store1 在 Load2 和任何后续加载操作之前完成。Store1之前的store可能"不"浮动在 Load2 和任何后续load 操作之下。//
// 我们定义了两个进一步的操作,“release”和“acquire”
release
// 释放处理器执行后,在释放完成之前,所有处理器都可以看到该释放之前发出的所有内存访问的效果。
// 由它发出的后续内存访问的效果可能会在释放之前可见。
// 即,后续的内存访问可能会浮动在释放上方,但之前的内存访问可能不会浮动在释放下方。
acquire
// 处理器执行 acquire 后,在获取完成后,所有处理器都可以看到该处理器发出的所有内存访问的效果。
// 由它发出的先前内存访问的效果*可能*在获取之后*可见。
// 即,先前的内存访问可能会浮动在获取的下方,但后续的内存访问可能不会浮动在其上方。
fence
// 最后,我们定义一个“fence”操作,从概念上讲,它是释放与获取的结合。
//在现实世界中,这些操作需要一个或多个机器指令,这些指令可以浮动在释放或获取的上方和下方,因此我们通常不能直接连续发出释放-获取。我们知道的所有机器都实现某种内存栅栏指令。
//释放和获取的独立实现分别需要关联的 dummy volatile store and load。为了避免冗余操作,我们可以定义复合运算符:“release_store”、“store_fence”和“load_acquire”。
// sparc RMO ia64 x86
// ---------------------------------------------------------------------
// fence membar #LoadStore | mf lock addl 0,(sp)
// #StoreStore |
// #LoadLoad |
// #StoreLoad
//
// release membar #LoadStore | st.rel [sp]=r0 movl $0,<dummy>
// #StoreStore
// st %g0,[]
//
// acquire ld [%sp],%g0 ld.acq <r>=[sp] movl (sp),<r>
// membar #LoadLoad |
// #LoadStore
//
// release_store membar #LoadStore | st.rel <store>
// #StoreStore
// st
//
// store_fence st st lock xchg
// fence mf
//
// load_acquire ld ld.acq <load>
// membar #LoadLoad |
// #LoadStore
// 仅使用release_store和load_acquire,我们可以实现以下有序序列。
// 1. load, load == load_acquire, load
// or load_acquire, load_acquire
// 2. load, store == load, release_store
// or load_acquire, store
// or load_acquire, release_store
// 3. store, store == store, release_store
// or release_store, release_store
// 上面这些不需要 sparc-TSO 的 membar 指令,也不需要 ia64 的额外指令。
// 相对于前面的存储排序load 需要 store_fence,这意味着 sparc-TSO 下的 store 和 load 之间有一个 membar #StoreLoad。 ia64 需要fence。在 x86 上,我们使用锁定的 xchg。//
// 4. store, load == store_fence, load
// 使用 store_fence 确保在“感兴趣”区域中完成的所有 store 在后续load 和store 之前都可见。
//
// 常规用法是发出 load_acquire 来进行有序加载。
// 当您只关心先前的存储在release_store之前可见,但不关心与release_store关联的存储何时变得可见时,请对有序存储使用release_store。
// 使用release_store_fence来更新线程状态等值,我们不希望当前线程继续下去,直到所有先前的内存访问(包括新的线程状态)对其他线程可见。
// C++ Volatility 的介绍
// C++ 保证称为“序列点”的操作的排序(定义为 volatile 访问和库I/O函数调用)上保证了顺序。
// 在序列点之前的'副作用'(定义为volatile 访问,库I/O函数调用和对象修改)必须在该序列点处可见。
// 这意味着所有的屏障实现,包括独立的 loadload,storestore,loadstore,storeload,acquire和release都必须包含一个序列点,通常通过一个 volatile 内存访问。保证序列点的其他方式,例如,使用间接调用和Linux的__asm__ volatile。
注意:从6973570开始,我们已经用栈上的易失性存储替换了原来的静态"dummy"字段。我们当前使用的所有编译器版本(SunStudio,gcc和VC++)都尊重这里的易失性语义。如果你使用其他编译器构建HotSpot,你可能需要验证没有编译器重排序发生在易失性访问表示的序列点之间。
// os::is_MP 被认为是冗余的
// 调用此接口的用户不需要在发出操作之前测试os::is_MP()。这个测试由接口的实现进行处理(根据虚拟机版本和平台,测试可能会或者可能不会由实现实际完成)。
// 关于内存排序和缓存一致性的注意事项
// 缓存一致性和内存排序是正交的概念,尽管它们会相互影响。
/*
例如,
所有现有的Itanium机器都是缓存一致的,但是除非硬件看到一个load-acquire指令,否则它可以自由地重新排序关于其他加载的加载
所有现有的SPARC机器都是缓存一致的,不像Itanium,TSO保证硬件按照加载与加载,存储与存储的顺序进行排序。
*/
考虑loadload的实现。如果你的平台不是缓存一致的,那么loadload不仅必须防止硬件加载指令的重新排序,而且它还必须确保后续从可能被其他处理器写入的地址(即,被其他处理器广播的地址)的加载一直到这些处理器和发出loadload的处理器共享的内存的第一级。
// 因此,如果我们有一个多处理器系统,比如说,每个处理器都有一个D$,它看不到其他处理器的写操作,并且有一个可以看到的共享E$,那么loadload屏障就必须确保以下两种情况中的一种:
1、在发出处理器的D$ 中包含来自可能被其他处理器写入的地址的数据的缓存行被无效,以便后续从这些地址的加载进入E$,(它可以通过将这样的缓存行标记为'共享'来做到这一点,尽管如何告诉硬件进行标记是一个有趣的问题)
2、在发出处理器的D$中从未有过这样的缓存行,这意味着所有对共享数据的引用(无论如何识别:参见上文)都绕过了D$(即,从E$满足)。
如果你的机器没有E$,就用'main memory'代替'E$'。
这两种替代方案都很麻烦,所以我们知道的当前机器都没有不一致的缓存。
如果loadload没有这些属性,那么用于发布共享数据结构的store-release序列就无法工作,因为试图读取由另一个处理器新发布的数据的处理器可能会去自己的不一致的缓存中满足读取,而不是去新写入的共享内存。
//注意!!
关于MutexLocker及其朋友们的说明
请参见mutexLocker.hpp。在整个虚拟机中,我们假设MutexLocker及其朋友们的构造函数按照围栏,锁定和获取的顺序执行按此顺序。并且它们的析构函数按照释放和解锁的顺序执行按此顺序。如果它们的实现发生变化,使得这些假设被违反,那么许多代码将会出错。
class OrderAccess : AllStatic {
public:
static void loadload();
static void storestore();
static void loadstore();
static void storeload();
static void acquire();
static void release();
static void fence();
static jbyte load_acquire(volatile jbyte* p);
static jshort load_acquire(volatile jshort* p);
static jint load_acquire(volatile jint* p);
static jlong load_acquire(volatile jlong* p);
static jubyte load_acquire(volatile jubyte* p);
static jushort load_acquire(volatile jushort* p);
static juint load_acquire(volatile juint* p);
static julong load_acquire(volatile julong* p);
static jfloat load_acquire(volatile jfloat* p);
static jdouble load_acquire(volatile jdouble* p);
static intptr_t load_ptr_acquire(volatile intptr_t* p);
static void* load_ptr_acquire(volatile void* p);
static void* load_ptr_acquire(const volatile void* p);
static void release_store(volatile jbyte* p, jbyte v);
static void release_store(volatile jshort* p, jshort v);
static void release_store(volatile jint* p, jint v);
static void release_store(volatile jlong* p, jlong v);
static void release_store(volatile jubyte* p, jubyte v);
static void release_store(volatile jushort* p, jushort v);
static void release_store(volatile juint* p, juint v);
static void release_store(volatile julong* p, julong v);
static void release_store(volatile jfloat* p, jfloat v);
static void release_store(volatile jdouble* p, jdouble v);
static void release_store_ptr(volatile intptr_t* p, intptr_t v);
static void release_store_ptr(volatile void* p, void* v);
static void store_fence(jbyte* p, jbyte v);
static void store_fence(jshort* p, jshort v);
static void store_fence(jint* p, jint v);
static void store_fence(jlong* p, jlong v);
static void store_fence(jubyte* p, jubyte v);
static void store_fence(jushort* p, jushort v);
static void store_fence(juint* p, juint v);
static void store_fence(julong* p, julong v);
static void store_fence(jfloat* p, jfloat v);
static void store_fence(jdouble* p, jdouble v);
static void store_ptr_fence(intptr_t* p, intptr_t v);
static void store_ptr_fence(void** p, void* v);
static void release_store_fence(volatile jbyte* p, jbyte v);
static void release_store_fence(volatile jshort* p, jshort v);
static void release_store_fence(volatile jint* p, jint v);
static void release_store_fence(volatile jlong* p, jlong v);
static void release_store_fence(volatile jubyte* p, jubyte v);
static void release_store_fence(volatile jushort* p, jushort v);
static void release_store_fence(volatile juint* p, juint v);
static void release_store_fence(volatile julong* p, julong v);
static void release_store_fence(volatile jfloat* p, jfloat v);
static void release_store_fence(volatile jdouble* p, jdouble v);
static void release_store_ptr_fence(volatile intptr_t* p, intptr_t v);
static void release_store_ptr_fence(volatile void* p, void* v);
private:
// This is a helper that invokes the StubRoutines::fence_entry()
// routine if it exists, It should only be used by platforms that
// don't another way to do the inline eassembly.
static void StubRoutines_fence();
};
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/180220.html

