
volatile
为了后续理解,先简单说下 volatile 关键字。
volatile 修饰变量提供内存可见性,JSR-133 增强了 volatile 的内存语义(happens-before):限制编译器和处理器对 volatile 变量与普通变量的重排序。
JVM 提供的禁止重排序支持,实现原理是内存屏障:读屏障(Load Barrier)和写屏障(Store Barrier)。
内存屏障作用:
- 阻止屏障两侧的指令重排序。
- 强制把写缓冲区 / 高速缓存中的脏数据等写回主内存,或者让缓存中相应的数据失效。
Java 对内存屏障的使用策略:编译器在为 volatile 变量读写生成字节码时,在指令序列中插入内存屏障来禁止处理器重排序,以实现 JSR-133 增强部分的 volatile 内存语义。
- 在每个 volatile 写操作前插入一个 StoreStore 屏障;
- 在每个 volatile 写操作后插入一个 StoreLoad 屏障;
- 在每个 volatile 读操作后插入一个 LoadLoad 屏障;
- 在每个 volatile 读操作后再插入一个 LoadStore 屏障。
伪代码:
StoreStore `volatile变量——写` StoreLoad; // 写前指令都不能重排序,写后volatile读不能重排序
`volatile变量——读` LoadLoad + LoadStore; // 读后指令都不能重排序
内存屏障
x86 上内存屏障的实现:
static inline void compiler_barrier() {
// 内嵌汇编,格式:__asm__ (汇编语句模板: 输出部分: 输入部分: 破坏描述部分)
__asm__ volatile ("" : : : "memory"); // 编译屏障
// volatile :告诉GCC编译器,禁止重排序
// ("" : : : "memory"):告诉GCC编译器,禁止"memory"前后代码重排序、缓存作废,需要时再内存读
}
inline void OrderAccess::loadload() { compiler_barrier(); }
inline void OrderAccess::storestore() { compiler_barrier(); }
inline void OrderAccess::loadstore() { compiler_barrier(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() { compiler_barrier(); }
inline void OrderAccess::release() { compiler_barrier(); }
inline void OrderAccess::fence() {
// always use locked addl since mfence is sometimes expensive 内存屏障消耗的资源大于locked指令
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
// StoreLoad 屏障
// 对指定寄存器+0,空操作,为了使用lock而使用
// x84平台,基于MESI,致使该缓存行中数据在其他CPU中失效
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
compiler_barrier();
}
可以得出,除了 storeload ,其它几个屏障都只是编译屏障,storeload 具备其它几个屏障的所有功能。即,storeload 相对于其它编译屏障是一个重量级操作。
Unsafe
Unsafe 中有如下 API,看起来挺奇怪。


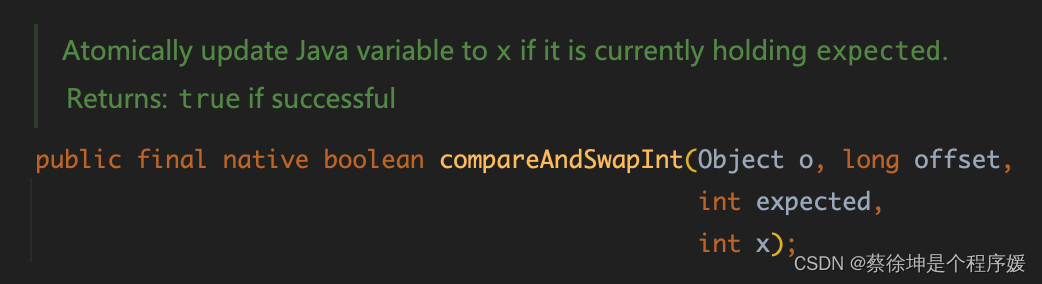
简单的归纳,我们分为 put/get、put/getVolatile、put/getOrdered 以及 compareAndSwap 和 getAndSet。
put/get
作用
基于 value 的内存地址进行读写值。
缺点
不能保证内存可见性,只能用在线程安全情况下的变量身上。
put/getOrdered
作用
基于 value 的内存地址进行读写值,避免重排序。
原理
- getOrder 等效于插入 LoadLoad 屏障,并未用到 LoadStore,即不完整的 volatile。
- putOrder 等效于插入 StoreStore 屏障。
优点
内存读写,避免重排序的发生,延迟写入,性能提升——对延迟要求低的代码可以使用。
缺点
StoreStore 只保证禁止重排序,不保证内存可见性,从而实现一次轻量级的读写,在特定场景能优化性能。
最终一致性——性能提升是有代价的,虽然便宜但写后结果并不会立即被其他线程看到,甚至是自己的线程(通常是几纳秒后被其他线程看到)。
put/getVolatile
作用
基于 value 的内存地址进行读写值,实现 volatile 语义。
原理
- getVolatile 等效于插入 LoadLoad + LoadStore。
- putVolatile 等效于插入 StoreStore、 StoreLoad;。
优点
灵活——等效于给相应的字段加上 volatile 关键字,手动插入内存屏障实现 volatile。
我们知道,对于
int volatile x = 0;, JVM 在任何地方都对变量 x 的读写操作添加内存屏障,以保证内存可见性与防止重排序。
那么问题来了,我们只想在某些特定的地方拥有 volatile 读写的内存语义?那么 put/getVolatile 就安排上了。
根据文章开头对 volatile 的介绍,put/getVolatile 相当于将 volatile 变量的读写拆分为 volatile – write/read 两个步骤,以方便进行手动实现。
缺点
一般都在开发 JDK 时使用。对于这种极值的性能追求,需要开发人员有着强大的编程能力,以及对并发编程有着深入的理解,当然也离不开业务的需要。否则,还是老实使用 volatile,不然多线程业务下出现问题排除起来可不容易。
compareAndSwap
作用
比较当前值与期望值,如果相等,那么替换为指定值,如果不相等,什么也不做。该操作是原子操作
原理
CAS,利用 CPU 原语 cmpxchg 实现无锁原子交换。
优点
线程安全的修改,无锁的无阻塞,性能高。
缺点
ABA、交换会出现失败需要业务层保证成功。
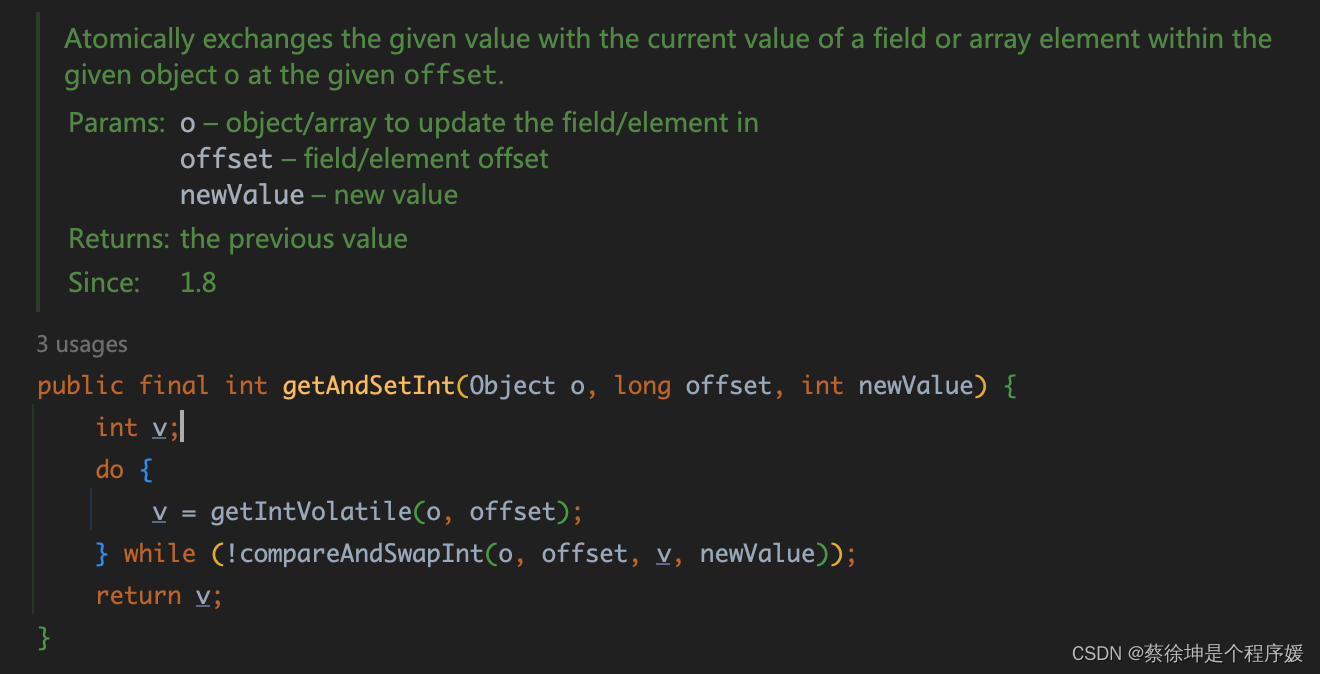
getAndSet
原理
基于 CAS + 循环。
优点
无锁的线程安全的修改,无锁的无阻塞,性能高。保证修改成功。
缺点
ABA。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/180266.html

