
看JUC工具源码突然发现没用volatile关键字修饰这些变量,哼哼,有点意思。你是在诱惑我小叮当。

为什么count不需要使用volatile修饰,如何保证其可见性?
我们知道AQS实现的锁可见性依赖于对volatile state变量的读写触发内存屏障来保证。
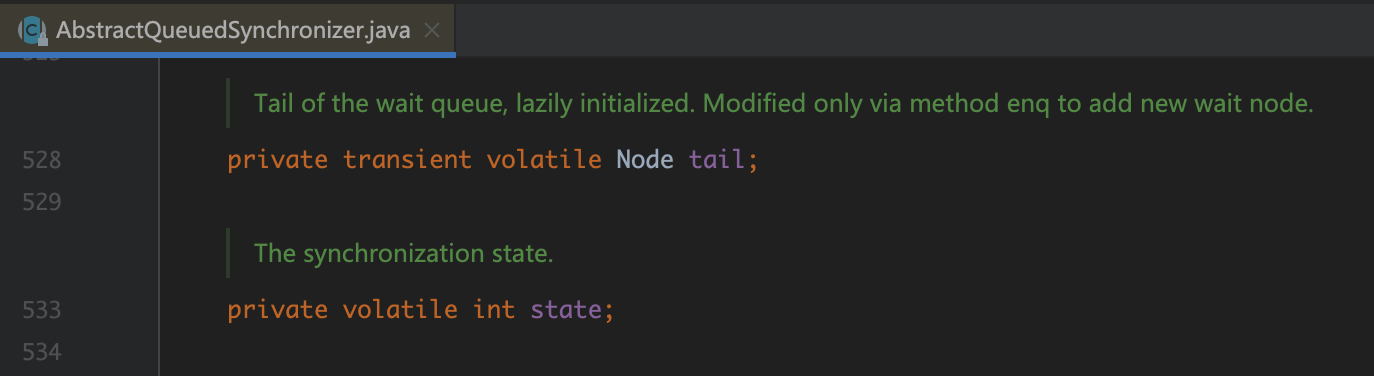
究其原因,是count变量由default修饰,count只对当前类或package中子类方法可见。即,对count的读写方法中都触发了内存屏障操作,也因此得以保证count变量对当前线程可见。

究其原理请听我娓娓道来。
试一试
我们根据上述的理论来编写代码,以验证我们的猜想。
在此之前,你应该知道:
- 以下示例代码都可运行。
- Java内存模型的规则。
例1,volatile变量具有可见性!!!
public static volatile boolean b = true;
new Thread(() -> {
try {Thread.sleep(100);} catch (InterruptedException e) {}
b = false;
}, "线程2").start();
new Thread(() ->{
while (b) { // 可见线程1对b的修改
}
}, "线程2").start();
线程对volatile修饰的变量进行写:
(1)将工作内存修改了的缓存(不仅仅是该变量的缓存)都强制刷新回主内存。
(2)把其他CPU对应缓存行标记为invalid状态,那么在读取这一部分缓存时,必须回主内存读取。这样也
就保证了线程间的可见性。
例2,lock与unlock之间的变量被修改后,仍旧对其它线程不可见!!!(文末解释)
例如:
public static boolean b = true;
new Thread(() -> {
try {Thread.sleep(100);} catch (InterruptedException e) {} // 先让线程2启动并缓存变量b
lock.lock();
b = false; // 如果变量b不是volatile,这里修改解锁后,仍然对其它线程("线程2")不可见
lock.unlock(); // 解锁之后,线程2仍然会继续运行
}, "线程1").start();
new Thread(() ->{
while (b) { // 线程2人就使用缓存中的b变量
}
}, "线程2").start(); // 线程死循环
使用JUC的锁(ReentrantLock)、synchronized都不能保证加解锁范围内的非volatile变量对其它线程可见,需要显示地将变量声明为volatile,或其它线程显示的使用锁或CAS强制读取最新值。
例3,lock与unlock之间的变量被修改后,对有lock与unlock操作的线程可见!!!
例如:
public static boolean b = true;
new Thread(() -> {
try {Thread.sleep(100);} catch (InterruptedException e) {}
lock.lock();
b = false; // 如果变量b不是volatile,这里修改解锁后,仍然对其它线程("线程2")不可见
lock.unlock();
}, "线程1").start();
new Thread(() ->{
while (b) {
lock.lock(); // 单纯的加锁与解锁,就能保证变量b的可见性
lock.unlock(); // 解锁后,在下一次循环当前线程能读到b的最新值
}
}, "线程2").start();
A类的成员变量b,线程1在lock块中修改A.b,在lock块离开前触发volatile的修改,会把修改的值从工作内存flush到主内存中,然后当线程2在lock块中读取A.b,工作内存会被设置无效,所以从主内存中读取它的实际值,这样完成了A.b的可见性。
例4,变量被修改后,对有lock与unlock操作的线程可见!!!
public static boolean b = true;
ReentrantLock lock = new ReentrantLock();
new Thread(() -> {
try {Thread.sleep(100);} catch (InterruptedException e) {}
b = false; // 未使用锁对b进行修改
}).start();
new Thread(() ->{
while (b) { // 脏读,b=true
lock.lock(); // 从主存最新读
lock.unlock();
}
}).start();
在进入锁时,会去主存中读取此时的最新数据,退出锁时将当前更新刷新到主存中。
Java volatile
字节码层面如何处理volatile?
编译源码(javac xxx):
public volatile int a = 0; // Java API volatile
public int b = 0;
反编译(javap -v xxx):
public volatile int a;
descriptor: I
flags: (0x0041) ACC_PUBLIC, ACC_VOLATILE
public int b;
descriptor: I
flags: (0x0001) ACC_PUBLIC
注意:若需要反编译查看ACC_VOLATILE,必须使用非private修饰变量,不然反编译信息会忽略该部分字节码信息。
因此,我们可以得出,字节码层面使用ACC_VOLATILE来表示volatile变量。
JVM层面如何处理volatile?
我们知道 volatile 提供可见性与有序性支持,即内存读和内存写与禁止编译重排序。
可见性,有硬件提供的内存读写屏障:
- Load:内存读,也就是加载操作(load),从内存读到寄存器。
- Store:到内存写,也就是存储操作(store),直接从寄存器写入到内存。
JVM 为了避免编译器和处理器对代码或指令进行重排序,保证 as-if-serial 语义,于是使用了内存屏障。为了保证并发,在简单的硬件屏障读写上进行了细化:
- LoadLoad:操作序列 Load1, LoadLoad, Load2,保证 1、2 顺序读如缓存。
- StoreStore:操作序列 Store1, StoreStore, Store2,保证 1、2 顺序写到内存。
- LoadStore:操作序列 Load1, LoadStore, Store2,保证 1、2 顺序读入缓存再写入内存。
- StoreLoad:操作序列 Store1, StoreLoad, Load2,保证 1、2 顺序写入内存再内存读入缓存。
接着看看 JVM 层面是如何实现 Load Barrier 和 Store Barrier 的:
OpenJDK的/src/hotspot/share/interpreter/bytecodeInterpreter.cpp。
...
CASE(_getfield):
CASE(_getstatic):
{
u2 index;
ConstantPoolCacheEntry* cache;
index = Bytes::get_native_u2(pc+1);
cache = cp->entry_at(index);
...
if (cache->is_volatile()) {
if (support_IRIW_for_not_multiple_copy_atomic_cpu) {
OrderAccess::fence(); // 读之前插入万能内初屏障
}
switch (tos_type) { // 根据字段类型进行读
...
}
}
...
}
CASE(_putfield):
CASE(_putstatic):
{
u2 index = Bytes::get_native_u2(pc+1);
ConstantPoolCacheEntry* cache = cp->entry_at(index);
...
if (cache->is_volatile()) {
if (cache->is_volatile()) {
switch (tos_type) { // 根据字段类型进行写
...
}
}
...
OrderAccess::storeload(); // 写之后插入万能内存屏障
}
...
}
根据OrderAccess::fence()的实现,我们可以看到:针对不同架构的处理器,OpenJDK 中提供了不同平台对 OrderAccess::fence() 的代码实现,屏蔽了底层硬件的差异,为 JVM 提供了统一的 CPP 层面的 API。
我们任意找一个 OrderAccess 的实现,比如来看Linux_x86上的实现:
#ifndef OS_CPU_LINUX_X86_ORDERACCESS_LINUX_X86_HPP
#define OS_CPU_LINUX_X86_ORDERACCESS_LINUX_X86_HPP
static inline void compiler_barrier() {
// 内嵌汇编,格式:__asm__ (汇编语句模板: 输出部分: 输入部分: 破坏描述部分)
__asm__ volatile ("" : : : "memory"); // 编译屏障
// volatile :告诉GCC编译器,禁止重排序
// ("" : : : "memory"):告诉GCC编译器,禁止"memory"前后代码重排序、缓存作废,需要时再内存读
}
inline void OrderAccess::loadload() { compiler_barrier(); }
inline void OrderAccess::storestore() { compiler_barrier(); }
inline void OrderAccess::loadstore() { compiler_barrier(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() { compiler_barrier(); }
inline void OrderAccess::release() { compiler_barrier(); }
inline void OrderAccess::fence() {
// always use locked addl since mfence is sometimes expensive 内存屏障消耗的资源大于locked指令
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
// StoreLoad 屏障
// 对指定寄存器+0,空操作,为了使用lock而使用
// x84平台,基于MESI,致使该缓存行中数据在其他CPU中失效
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
compiler_barrier();
}
inline void OrderAccess::cross_modify_fence_impl() {
if (VM_Version::supports_serialize()) {
__asm__ volatile (".byte 0x0f, 0x01, 0xe8\n\t" : : :); //serialize
} else {
int idx = 0;
#ifdef AMD64
__asm__ volatile ("cpuid " : "+a" (idx) : : "ebx", "ecx", "edx", "memory");
#else
// On some x86 systems EBX is a reserved register that cannot be
// clobbered, so we must protect it around the CPUID.
__asm__ volatile ("xchg %%esi, %%ebx; cpuid; xchg %%esi, %%ebx " : "+a" (idx) : : "esi", "ecx", "edx", "memory");
#endif
}
}
#endif // OS_CPU_LINUX_X86_ORDERACCESS_LINUX_X86_HPP
综上,我们便知道 storeload 开销是四种屏障中最大的,且在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能(见代码)。
Java CAS
Java层面CAS API,Unsafe#CAS
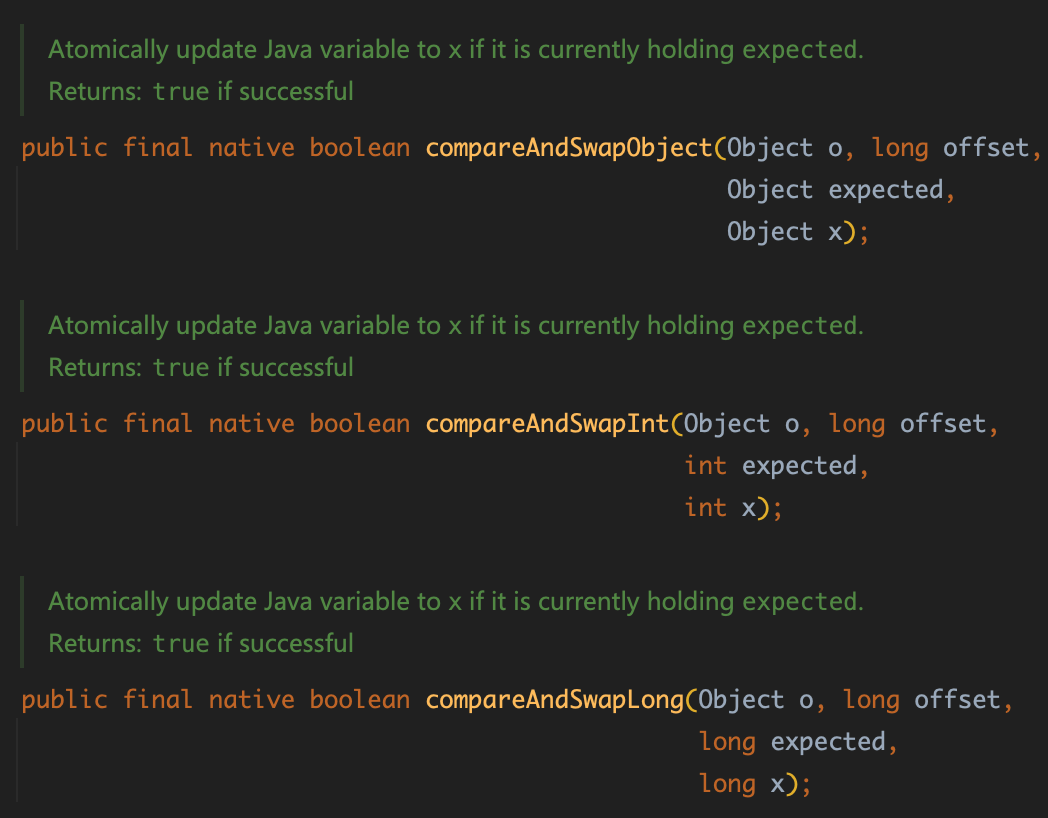
JVM层面CAS
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
Atomic::cmpxchg(x, addr, e)
Linux_x86_JVM平台中对CAS接口C++的实现:
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP(); // multi processor的缩写,mp核心数
// 内嵌汇编
// volatile:禁用GCC编译优化
// LOCK_IF_MP:判断当前系统是否为多核处理器决定是否为cmpxchg指令添加lock前缀
// cmpxchgl:CPU原语,实现原子CAS功能
asm volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory"); // 同上内存屏障的实现
return exchange_value;
}
可以得出结论,x86中Java CAS是通过lock+cmpxchg两条指令实现的。使得CAS兼具volatile读写的内存语义与原子性,即我们在前文中所说的CAS保证可见性与原子性。
Java CAS的缺陷
-
ABA问题
介绍的文章较多,也比较基础,不再赘述。
-
没有编译支持(对例2的解释)
我们观察C++中Atomic::cmpxchg实现便可知,多核CPU中光用lock+cmpxchg指令来保证原子、可见和禁止重排序是不够的,还需要C++在asm后紧跟volatile提供禁止GCC重排序功能。而Java volatile与Java CAS相比,Java CAS还缺失了Java volatile具有的禁止重排序功能,为什么???Java CAS用到了C++的volatile吗?没错,至少在JVM的C++层面实现是相同的,但是Java属于编译+解释型语言,Java在编译具有volatile的属性get/set时会自动添加能触发内存屏障的指令!!!而对于Java CAS操作的变量,你就只能每次都手动触发内存屏障!!!使用CAS操作属性,稍有疏漏,必将埋下BUG,如例2。因此,我们Java CAS总是和volatile搭配使用,以获得Java层面的编译支持,提供完整的JMM happens-before语义。
如果你运行过例2的代码后,想必你会发现一些问题:例2中”线程2″一直死循环。
疑问:聪明的你应该会想起,ReentrantLock加解锁中涉及了CAS操作,而CAS操作会清除工作区域的缓存,然而为什么对”线程2″来说却无效呢?
动手试一试:将”线程1″中换成CAS来修改变量b,”线程2″同样不可见b。
主要原因:”线程2″中并没有涉及到任何内存屏障操作,于是”线程2″对变量b便一直缓存读,这也就是导致”线程2″一直循环的原因。也就是说,被CAS操作的变量,以及lock~unlock之间的变量,编译器在编译时是没有额外增加内存屏障操作的。如果读取被CAS修改的变量或lock~unlock之间的变量,且读取线程也没有触发对内存屏障的操作,那么这部分被读取的变量对该线程来说是不具备可见性的。
解决方法:volatile具有编译支持,编译器会对volatile变量的读写自动添加内存屏障,对这部分变量我们对齐添加volatile修饰,也就是CAS要与volatile结合使用。
或者通过其它方式在读取线程手动触发一次内存屏障的操作。比如,lock|unlock、synchronized、CAS等。
——附——
C++ volatile
-
与外部硬件交流(比如 DMA 或 MMIO)——引用设备寄存器的变量时使用,避免编译优化器无意删除重要的访问。
-
禁止编译重排序。
参考:https://docs.oracle.com/cd/E36784_01/html/E36860/codingpractices-1.html
asm volatile (“” : : : “memory”)
给 GCC 内嵌汇编加上一个内存破坏性描述符,禁止优化、禁止缓存读。
-
编译内存屏障:这条语句后面的语句不能被编译器优化到前面去,前面的不能被优化到后面去——这是所有内嵌汇编都具有的效果。
-
禁止所在函数被inline:不管开多高的优化等级, 这也是所有内嵌汇编都具有的效果。但是这一点目前也渐渐被gcc新版本打脸了。。
-
强制内存读:重点,这条语句之后,函数返回前的所有流程(也就是包括了循环语句 跳转到这条语句前面去的场景),对所有地址的访问(包括局部变量地址)都必须去内存里去 load,而不能使用这条语句前寄存器缓存的结果(当然,某些寄存器的结果编译器还是认为还是有效的,例如堆栈寄存器,不然代码没法走下去了)。
参考:https://www.zhihu.com/question/66896665/answer/249586507
lock指令
Intel手册——LOCK前缀使得cache写入内存,同时使得其它核的cache无效化。
- 将当前处理器缓存行的数据写回主存。
- 缓存一致性协议生效:在其他处理器缓存了该数据的缓存行的无效化。
参考:https://stackoverflow.com/questions/27837731/is-x86-cmpxchg-atomic-if-so-why-does-it-need-lock/44273130#44273130
Java volatile
在Java中的语义是:变量读写原子性(例:64 Long)、禁止指令重排序(编译与处理)、跨线程内存可见性(Happens-Before)。
由 C++ volatile、asm volatile (“” : : : “memory”) 和 lock 联合实现,因此 Java volatile 也就实现了:
- (弱)原子性(lock:锁总线),32 位机器上的 long | double 读写原子(64 无需),且不能保证 Java 层面的原子性。观察 x84_64 的实现可以发现,volatile 甚至连单条字节码的读写原子都不能保证(即,用 i++ 生成 3 条字节码举例是错误的❌),只能保证底层代码执行时的单次读写可见性。例如字节码 putfield | getfield 操作 volatile 变量中,C++用了大段落代码来实现,且并未加锁!这期间完全有可能与其它线程并发执行,因此 volatile 想要得到完整的原子性支持必须搭配 synchronized 使用!synchronized 基于互斥锁思想,提供线程安全的临界点。且 synchronized 与 volatile 互补,synchronized 不能为临界区中非 volatile 变量提供编译支持,volatile 能提供编译支持,保证线程之间对该变量的读写可见。
- 禁止重排序(fence:lock+compiler_barrier、compiler_barrier:asm、volatile)。
- 可见性(lock + 【MESI,MOSI,Synapse,Firefly 及 DragonProtocol等】),通过总线锁 + 缓存一致性协议实现。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/180282.html

