
目录
课程内容
一、JDK体系结构与跨平台特性介绍
1、JDK体系结构
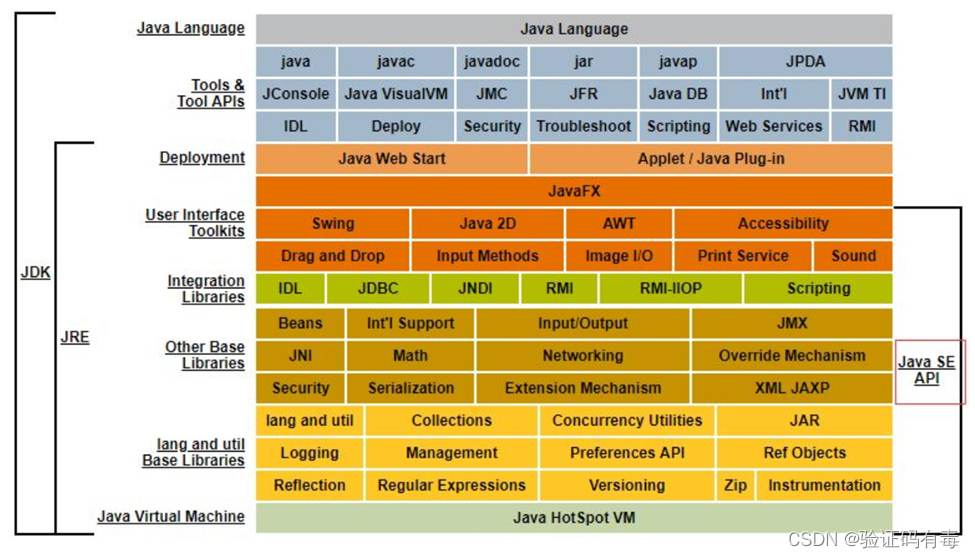
- JDK:即Java Development Kit,翻译为“Java 语言的软件开发工具包(SDK)”
- JRE:Java Runtime Environment,翻译为“Java运行时环境”,顾名思义,JRE可以让计算机系统运行Java应用程序(Java Application)
2、JDK常用的基础命令描述
- javac:Java编译器,将Java源代码换成字节码
- java:Java解释器,直接从类文件执行Java应用程序代码
- javadoc:根据Java源代码及其说明语句生成的HTML文档
- jdb:Java调试器,可以逐行地执行程序、设置断点和检查变量
- javah:产生可以调用Java过程的C过程,或建立能被Java程序调用的C过程的头文件
- javap:Java反汇编器,显示编译类文件中的可访问功能和数据,同时显示字节代码含义
- jar:多用途的存档及压缩工具,是个java应用程序,可将多个文件合并为单个JAR归档文件
3、Java语言的跨平台特性
严格来说Java的跨平台不算什么神奇的东西,如果你还记得下载jdk的过程的话,你会回想起,一般jdk有windows版本跟jdk版本。跨平台的本质,其实是jdk在不同系统平台调用对应系统的Api而已。附上一段C/C++跨平台的示例代码:
C++:编写跨平台程序的关键,C/C++中的内置宏定义
分两部分:
操作系统判定:
Windows: WIN32
Linux: linux
Solaris: __sun
编译器判定:
VC: _MSC_VER
GCC/G++: __GNUC__
SunCC: __SUNPRO_C和__SUNPRO_CC
预编译命令:
#ifdef #endif: 顾名思义,该命令是在编译之前的阶段,作用的if-else。以此实现"选择编译内容"的能力
------------------------------------------------------------------------
#include <stdio.h>
#include <iostream>
using namespace std;
int main(int argc,char **argv)
{
int no_os_flag=1;
#ifdef linux // 若为Linux环境,则编译以下代码
no_os_flag=0;
cout<<"It is in Linux OS!"<<endl;
#endif
#ifdef _UNIX // 若为Unix环境,则编译以下代码
no_os_flag=0;
cout<<"It is in UNIX OS!"<<endl;
#endif
#ifdef __WINDOWS_ // 若为Windows环境,则编译以下代码
no_os_flag=0;
cout<<"It is in Windows OS!"<<endl;
#endif
#ifdef _WIN32 // 若为Windows环境,则编译以下代码
no_os_flag=0;
cout<<"It is in WIN32 OS!"<<endl;
#endif
if(1==no_os_flag){
cout<<"No OS Defined ,I do not know what the os is!"<<endl;
}
return 0;
}
二、JVM内存模型深度剖析
我发现,不少人会以为下图就是JVM的内存模型:

只能说对了一半,但是不全。在讲解完整的JVM模型之前,先附上一段代码,帮助理解:
public class Math {
public static int count = 1;
public static User user = new User();
public void compute() {
int a = 1;
int b = 2;
int c = (a + b) * 10
return c;
}
public static void main(String[] args) {
Math math = new Math();
math.compute();
}
}
我们来分析一下上面代码,都有哪些元素吧:
- 1个类Math
- 2个静态变量,分别为int基础类型count,以及new出来的User对象user
- 1个main方法
- main方法中有1个new出来的局部变量,Math对象math,它应该存放在堆中
- 1个局部方法,compute()
- compute方法中有3个int类型局部变量
上面提到的【代码元素】,他们在完整的JVM的内存模型的表现如下:

如上图所示,我将图片用一条红色箭头划分成了两部分。结合上面提到的代码元素,看看上图右边部分——JVM完整内存模型:
- 堆:是一块用来动态分配内存的,运行时数据区,是java中重要的内存组成部分,它是所有线程共享的。绝大多数java对象、数组都存储在这里。一个典型的现象就是:new出来的对象会被分配在这里。如上图,无论是Math对象,还是静态User对象,都存放在这里。
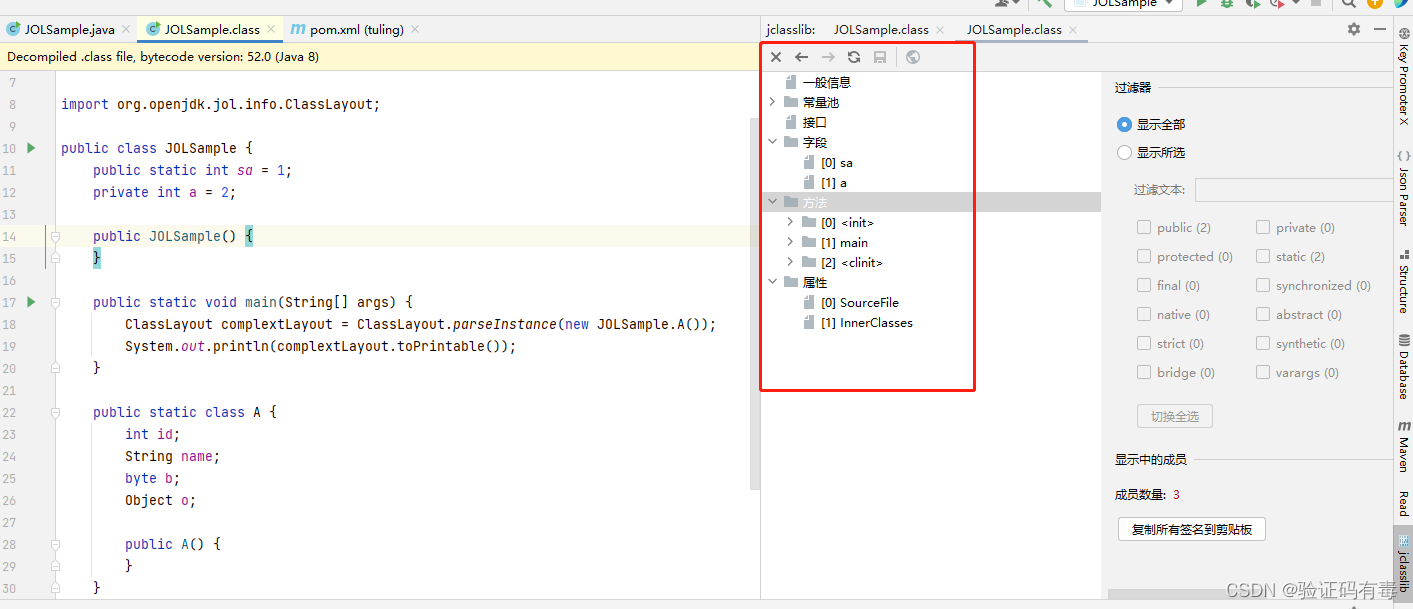
- 方法区/元空间(jdk1.8之前也叫做永久代):是一块用来存储常量、静态变量、类元信息的运行时数据区域,它也是所有线程共享的。与堆不同的是,这里存放的数据,是类级别的,而堆是对象级别。(PS:其实说类元信息什么的有点笼统、抽象,更加详细一点的说法是方法区里存放着类的版本,字段,方法,接口和常量池;常量池里存储着字面量和符号引用,我在下面附上两张类元信息解析图)(常量池具体解释,见下面)
类元信息解析图:(由 jsclasslib插件生成)
再来看看神秘的常量池:

- 栈(线程):java官方又叫虚拟机栈。但是用“线程栈”来描述会比较恰当一点。准确的来说,每一条线程在运行时都会开辟一条自己的“线程栈”,使得不同的线程之间彼此独立。所以,线程栈是用来存放线程在运行时产生的一些数据的内存区域,它是每个线程独有的。
- 本地方法栈:顾名思义,是用来存放本地方法调用链过程的内存区域,它是每个线程独有的。本地方法是什么?即hotspot所有用native修饰的方法。
- 程序计数器:是一个用来记录代码运行位置的内存区域,它也是每个线程独有的。不同于计算机组成原理中我们知道的程序计数器 ,这边的程序计数器的维护是由JVM的【字节码执行引擎】完成的。它的作用,是用来在线程上下文切换的过程中,保存当前线程状态,方便再次获得CPU时间片的时候“还原现场”。
说完图的右边,我们再来说说图的左边部分——线程栈的模型。根据图片的信息,我们可以发现有一下元素:
- 栈帧:一个栈帧对应着一个方法的调用。我们知道方法的调用链跟栈FILO的特性天然契合,所以后调用的栈帧会在先调用的栈帧前面。如main方法栈帧,math.compute方法栈帧
- 局部变量表:存放方法内生成的局部变量。值得注意的是:如果是基础数据类型,则存放的是基础数据;若为引用类型Object数组等,则存放的,是指向堆内存的一个引用。
- 操作数栈:跟CPU的寄存器是差不多的工作原理,存放的是当前操作的数据内容,同时也有计算能力。栈字,FILO特性也可见一斑,这里必然存在“压栈”、“出栈”对象。这个对象是谁呢?即:局部变量表中的值。
- 动态链接:说到动态连接,不得不提一下符号引用。符号引用,在这里,即将compute这个方法的符号替换成指向数据所存内存的指针或句柄等直接引用。对于compute方法来说,这个直接引用则是:方法区常量池中,compute()所有符号所在常量池中的地址。(这里用到常量池,只是为了就是为了一些提供符号的,便于指令的识别)。接着在运行时,这些符号会被转变为compute()方法具体代码在内存中的地址,主要是通过对象头的类型指针去转换引用
- 方法出口:存放调用链某个节点被发起调用时的起始地址
三、GCRoot与STW机制
什么是GCRoot,什么又是STW机制呢?欲知此,我们必须要先知道一个东西,那就是Java的垃圾回收器,GC(Garbage Collector)。
GC的目标区域是哪里呢?堆。说到这里,我们需要补充一下,堆的内存模型。
堆的内存模型以及分代收集理论

堆分为年轻代跟老年代,默认的,他们的比例为1:2。而年轻代,通常又分为3个区域,分别为:eden区,survivor0区,survivor1区,他们默认的比例为:8:1:1。他们的联系与区别如下:
- 年轻代:存放“朝生夕死”的对象,通常我们分配在堆里的新对象,都会先放在年轻代中。在这里发生的GC,叫做MinorGC。
- eden:翻译,伊甸园。何为伊甸园?即迎接新生的地方,所以这里又叫:新生区。
- survivor0、survivor1:这两者其实是同一个东西,没什么区别。只不过,因为年轻代采用的GC算法是“复制”算法,所以为了提升复制效率,通常需要一个空的survivor区,来做中间缓存区。
- 老年代:跟年轻代相反,这里存放的通常都是在前几次(默认15)GC中幸存下来的“老年”对象,所以叫老年代。除了老年对象,这里也可能存放“大对象”,这个在后面会讲解。在这里发生的GC,叫做FullGC/MajorGC。
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将java堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
回到正题,什么是GCRoot跟STW机制呢?这两个东西都是发生在GC过程中的概念。
GCRoot
翻译,即垃圾回收的根节点。它是垃圾回收过程中,用来寻找、标记,垃圾/非垃圾对象的起始点,从它开始遍历,找到所有活动对象并标记它们,将未被标记的对象回收。GCRoot通常为以下对象:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象。如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等
- 方法区中类静态属性引用的对象。例如java类的引用类型静态变量
- 方法区中常量引用的对象。例如字符串常量池里的引用
- 本地方法栈中 JNI 引用的对象
- 被同步锁持有的对象
- Java 虚拟机内部的引用。如基本数据类型对应的class对象,一些常驻的异常对象等,还有类加载器
STW
翻译,即停止世界(Stop The World),该机制是指在进行垃圾回收时,Java虚拟机会暂停应用程序的运行,以便进行垃圾回收操作。这意味着在进行垃圾回收时,应用程序将无法继续执行。这对于需要实时响应的应用程序来说是一个问题,因为它们需要保持持续的响应时间
四、JVM参数设置通用模型
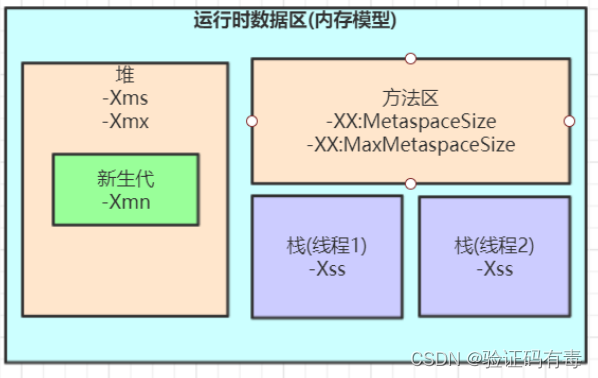
先附上一段我当前线上生产应用的jvm参数:
java ‐Xms4096M ‐Xmx4096M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐jar server.jar
上面这段jvm参数,涉及到的内容刚好跟上图提到的一模一样。接下来解释一下各个参数的意义。
-Xms4096M:初始化堆内存大小为4096M
-Xmx4096M:堆内存最大值为4096M
-Xmn2048M:设置年轻代大小为2048M。PS:增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8
-Xss1M:设置每个线程栈大小为1M。该值设置越小,一个线程栈里能分配的栈帧就越少,但是对JVM整体来说能开启的线程数会更多
-XX:MetaspaceSize=256M:初始化方法区/元空间大小为256M
‐XX:MaxMetaspaceSize=256M:设置方法区/元空间大小最大为256M
五、Class常量池与运行时常量池
学习总结
- JVM的内存模型,可以分为运行时数据区+类加载子系统+字节码执行器。而运行时数据区,则包含:堆(线程共享)方法区/元空间(线程共享),线程栈(每个线程独有一片空间),本地方法栈(每个线程独有一片空间),程序计数器(每个线程独有一片空间)。
- 线程栈又包含多个栈帧。每调用一个方法,则在线程栈上生成一个栈帧。栈帧是用来存放方法运行中产生的一些数据的。这些数据包括:局部变量、操作数栈、动态链接、方法出口。
- 动态链接,跟类加载阶段的静态链接作用一样。只不过后者目标对象是静态方法,而前者则为非静态方法。它是将方法符号,替换为指向数据所存内存的指针或句柄。(读到这里,才发现这东西跟C/C++中提到的虚函数表差不多的意思,后来找到了一篇关于动态链接的博文,算是有点印象了。JVM7:Java虚拟机栈——动态链接(Dynamic Linking))
感谢
感谢【作者:库隐】大佬的博文,JVM7:Java虚拟机栈——动态链接(Dynamic Linking))
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/180544.html

