
Mybatis
通常来说,做Java后台服务器开发,一般都离不开三个框架(Spring/SpringMVC/Mybatis),还有一些微服务相关的框架
Mybatis是什么
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
Mybatis就是一个帮助我们去自定义SQL语句,然后对数据库中的数据进行增删改查的一个框架,这种框架统一叫做ORM框架
什么是框架?
框架就是模板。好比一个简历模板,简历模板不是一个完整的简历,需要我们自己填充一些内容才能成为一个完整的简历
- 框架定义好了一些功能,这些功能是可用的。
- 框架中可以加入项目自己的功能,这些功能可以利用框架中已经写好的功能
框架是一个软件,是一个半成品软件,定义好了一些基础功能,需要加入你的功能就是完整的。 基础功能是可以重复使用的,是可以升级的
框架的特点:
- 框架一般不是全能的,不能做所有的事情
- 框架一般是针对某一个领域有效。特长在某一个方面,比如Mybatis做数据库操作强,但是不能做其他的事情
- 框架是一个软件
为什么要学习Mybatis呢?
因为JDBC和DBUtils的功能不够强大,并且SQL语句和代码强耦合,所以需要学习Mybatis来应对更加复杂的业务场景。
Mybatis快速入门
如何使用Mybatis呢?
导包
<!-- https://mvnrepository.com/artifact/org.mybatis/mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.6</version>
</dependency>
配置
-
配置一个Mybatis的主配置文件(mybatis-config.xml)
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <!--这个是Mybatis的主配置文件 上面的dtd 文件定义了这个xml文件中的标签的名字,出现的位置,顺序--> <!-- 这个configuration其实就是这个配置文件的头,表示这个配置文件的开始 --> <configuration> <!--environments 这个表示我们的数据源的环境--> <environments default="dev"> <!--id 表示环境的名字--> <environment id="dev"> <!--事务管理器 表示数据库事务交给谁去管理 , Type=JDBC表示交给JDBC去管理--> <transactionManager type="JDBC"/> <!--数据源(连接池)--> <dataSource type="POOLED"> <property name="driver" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/jdbc"/> <property name="username" value="root"/> <property name="password" value="123456"/> </dataSource> </environment> </environments> <!--这个配置的是表示我们Mybatis需要把哪个Mapper加载进来,找到mapper.xml文件的位置--> <mappers> <!--<mapper resource="org/mybatis/example/BlogMapper.xml"/>--> <mapper resource="UserMapper.xml"/> </mappers> </configuration> -
创建一个JavaBean,用于去与数据库里面的记录做一个映射
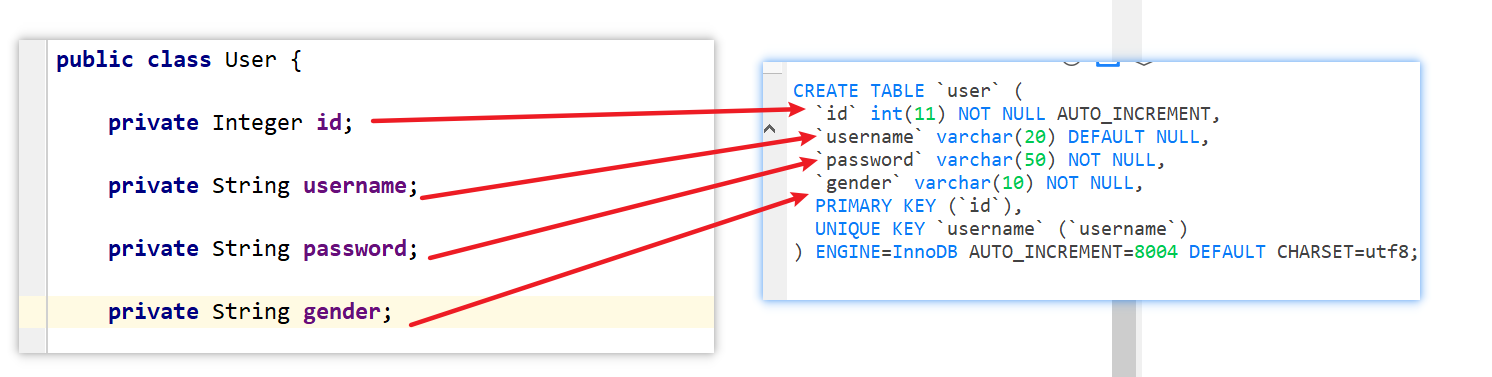
-
创建一个接口和一个xml文件
接口
public interface UserMapper { }xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- 1. 注意:这个命名空间必须是接口的全限定名称 2. 这个配置文件在经过编译后,必须和我们的接口在同一个路径下 为了实现这个目的,有两种手段 2.1 在resources路径下,建立和我们的UserMapper相同的包路径,然后把这个文件放进去 2.2 在我们UserMapper这个接口文件下直接建立这个xml文件,但是必须要在pom文件中加入以下配置 <!-资源文件的配置--> <!--<build>--> <!--<resources>--> <!--<resource>--> <!--<directory>src/main/java</directory>--> <!--<includes>--> <!--<!– 两个* 表示通配 *和我们的 _ 占位比较类似–>--> <!--<include>**/*.xml</include>--> <!--</includes>--> <!--</resource>--> <!--</resources>--> <!--</build> 3. 我们的这个<select>,必须得有resultType,必须得有返回类型,可不可以没有parameterType --> <mapper namespace="UserMapper"> <select id="selectAll" resultType="user.User" > select * from user </select> </mapper>
运用
@Test
public void testSelectAll(){
//第一步 创建sqlSessionFactoryBuilder
SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder();
// 第二步
// ClassLoader classLoader = MybatisTest.class.getClassLoader();
// InputStream inputStream = classLoader.getResourceAsStream("mybatis-config.xml");
InputStream inputStream = null;
try {
inputStream = Resources.getResourceAsStream("mybatis-config.xml");
} catch (IOException e) {
e.printStackTrace();
}
SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(inputStream);
// 第三步 获取sqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
// 第四步 执行sql
List<Object> list = sqlSession.selectList("UserMapper.selectAll");
// 输出
for (Object object : list) {
System.out.println(object);
}
// 关闭资源
sqlSession.close();
}
增 删 改 查
-
优化 我们发现在写方法的时候,我们每次都会去创建sqlSession对象,每次都会去关闭sqlSession对象,所以我们可以把这个过程提取出来,用JUINT的注解去完成提前创建和最后销毁
@BeforeClass public static void init(){ //第一步 创建sqlSessionFactoryBuilder SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder(); // 第二步 // ClassLoader classLoader = MybatisTest.class.getClassLoader(); // InputStream inputStream = classLoader.getResourceAsStream("mybatis-config.xml"); InputStream inputStream = null; try { inputStream = Resources.getResourceAsStream("mybatis-config.xml"); } catch (IOException e) { e.printStackTrace(); } SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(inputStream); // 第三步 获取sqlSession sqlSession = sqlSessionFactory.openSession(); } @AfterClass public static void destory(){ sqlSession.close(); } -
增加
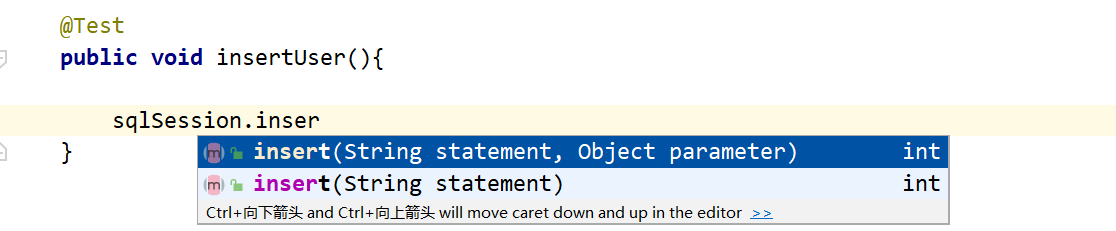
我们从上面可以发现,我们的insert方法不能传递多个值,所以暂时不去使用增加
-
删除
@Test public void testDelete(){ // 这里的传递的字符串必须和配置文件中的namespace以及<insert> <update>标签的id值对应上,中间用.拼接 int affectedRows = sqlSession.delete("UserMapper.deleteUserById", 1); System.out.println(affectedRows); // 我们发现sqlSession默认不会提交,所以我们在做对数据库的数据进行更改、删除、增加的时候,需要手动提交 sqlSession.commit(); }配置文件
<delete id="deleteUserById"> delete from user where id = #{id} </delete> -
改
@Test public void testUpdateUser(){ // sqlSession.insert("") int affectedRows = sqlSession.update("UserMapper.updateGender", "male"); System.out.println(affectedRows); sqlSession.commit(); }<update id="updateGender"> update user set gender = #{gender} </update> -
查
// 根据Id去查询 @Test public void testSelectOneById(){ User user = sqlSession.selectOne("UserMapper.selectOneById", 5); System.out.println(user); }<!--parameterType是什么的时候可以省略呢? 是基本类型的时候可以省略--> <!--mybatis定义了基本类型,除了我们java语法中的基本类型以外,还加入了 String,如果我们想通过Map、对象去传值,那么就不能省略--> <select id="selectOneById" resultType="user.User"> <!-- 这个取值的时候,#{} 里面的名字不作限制 --> select * from user where id = #{id} </select>
补充: 传入对象
插入对象
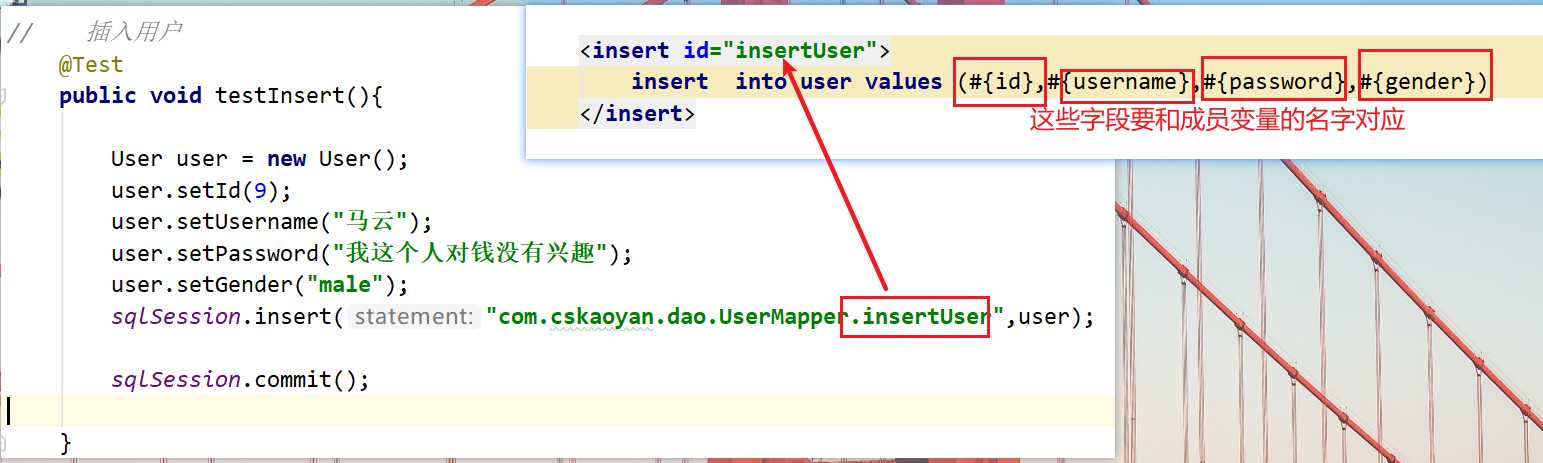
@Test
public void testInsert(){
User user = new User();
user.setId(9);
user.setUsername("马云");
user.setPassword("我这个人对钱没有兴趣");
user.setGender("male");
sqlSession.insert("com.cskaoyan.dao.UserMapper.insertUser",user);
sqlSession.commit();
}
Mapper.xml
<insert id="insertUser">
insert into user values (#{id},#{username},#{password},#{gender})
</insert>
修改也可以传入对象
3. Mybatis的动态代理
我们当前的使用方式是在代码里面直接写sql语句的路径,这种方式其实是很不灵活的,使用起来也很不方便,Mybatis给我们提供了UserMapper接口可以帮助我们生成代理对象,我们通过直接调用接口中的方法,底层就是去调用代理对象里面生成的方法,通过这种方式来实现接口的调用
如何使用
-
配置
<!--resultType记录的是一行记录对应的类型,而不是所有的--> <select id="selectList" resultType="com.cskaoyan.user.User"> select * from user </select> -
运用
接口
List<User> selectList();@Test public void selectList(){ UserMapper userMapper = sqlSession.getMapper(UserMapper.class); List<User> users = userMapper.selectList(); System.out.println(users); }
Mybatis 如何去生成代理对象的呢?
其实也就是我们在调用Sql语句的时候,我们的Mybatis如何去定位到这个sql语句。
如何去找到这个sql语句的呢?
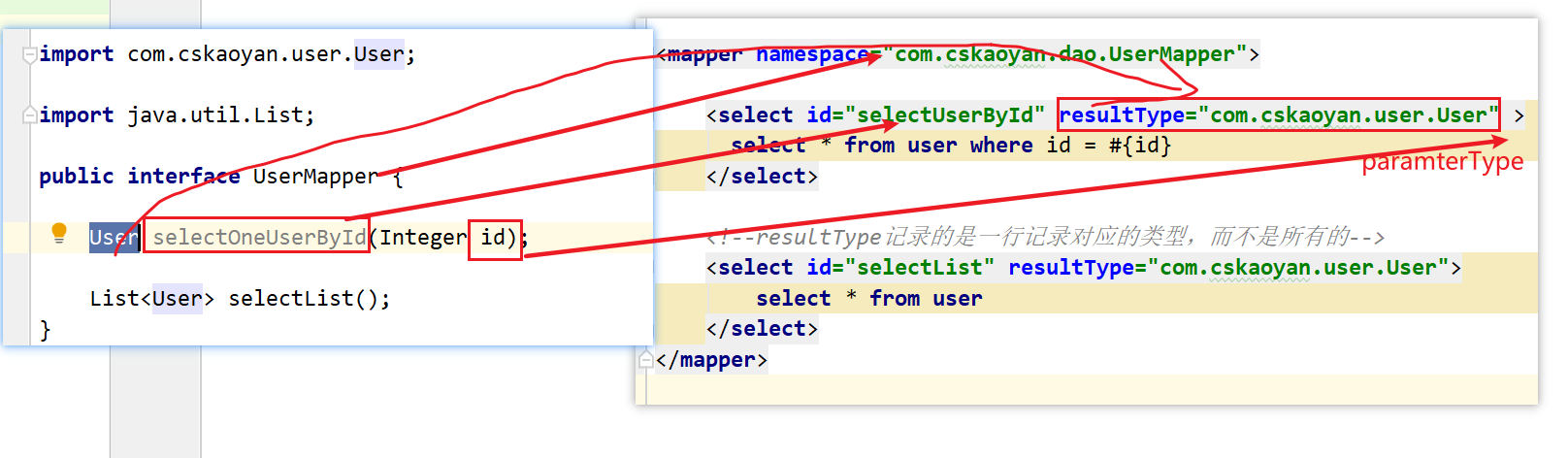
有几个对应关系,大家需要注意下:
- 我们的xml文件中的namespace必须和接口的全限定名称对应
- 我们xml文件中的标签的id值必须和方法名对应
- 我们xml文件中的参数类型(parameterType)和我们的方法的参数对应
- 我们xml文件中的返回值类型(resultType)必须和我们的方法的返回值类型对应
还有一个疑问,就是我们现在生成的代理对象,那么这个代理对象是怎么知道我们要去执行sqlSession.selectList或者是selectOne 或者是sqlSession.update() 呢?
首先需要根据配置文件中的标签来确定这个方法是insert、update、select、delete中的哪个,然后如果标签是update、delete、insert的话,那么就直接执行sqlSession.update(delete、insert) 这类方法,如果是标签是的话,那么就需要看我们方法的返回值类型是一个bean还是多个bean,然后再去执行对应的方法
案例
-
Mapper
public interface UserMapper { User selectOneUserById(Integer id); List<User> selectListUser(); User selectUserByName(String name); Integer insertUser(User user); Integer updateUserByMale(String male); Integer deleteUserById(Integer id); } -
XML
<mapper namespace="com.cskaoyan.dao.UserMapper"> <select id="selectUserById" resultType="com.cskaoyan.user.User" parameterType="int" > select * from user where id = #{id} </select> <!--resultType记录的是一行记录对应的类型,而不是所有的--> <select id="selectListUser" resultType="com.cskaoyan.user.User"> select * from user </select> <select id="selectUserByName" resultType="com.cskaoyan.user.User"> select * from user where username = #{name} </select> <insert id="insertUser" parameterType="com.cskaoyan.user.User"> insert into user values (#{id},#{username},#{password},#{gender}) </insert> <update id="updateUserByMale" parameterType="string"> update user set gender = 'female' where gender = #{gender} </update> <delete id="deleteUserById"> delete from user where id = #{id} </delete> </mapper>
4. 配置
4.1 properties
-
新建一个jdbc.properties配置文件
url=jdbc:mysql://localhost:3306/28_jdbc driverClassName=com.mysql.jdbc.Driver username=root password=123456 -
在我们的mybatis-config.xml文件中引入这个properties配置文件


-
运用
通过${key} 来取值,这个key是properties文件中的键值对的键值
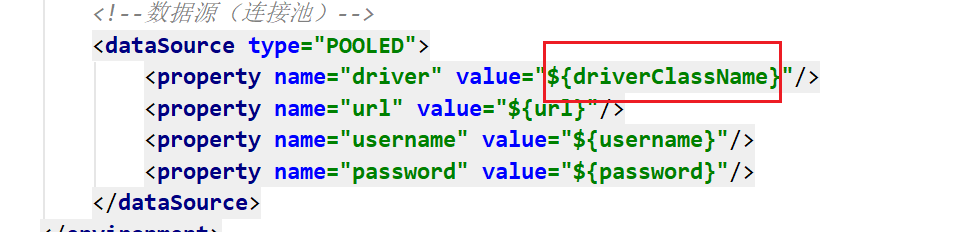
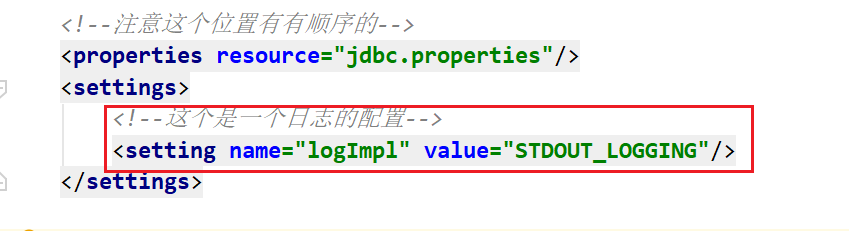
4.2 setting
开启日志
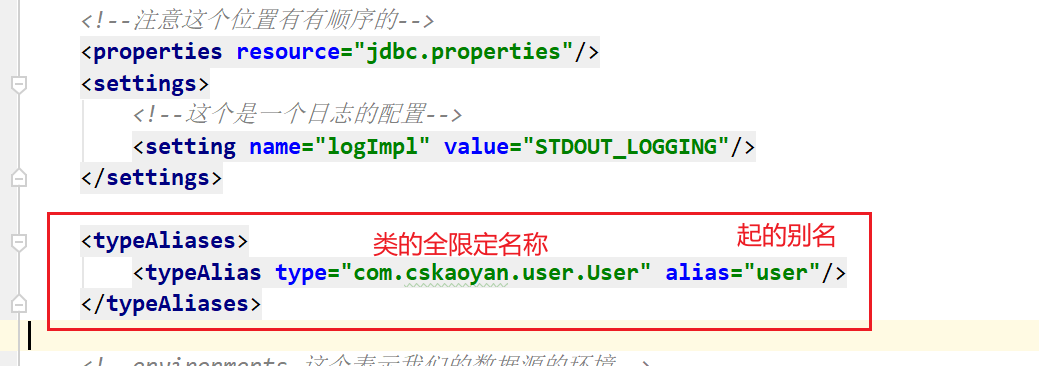
4.3 TypeAlaises
其实就去给一些类起别名
- 配置
- 使用
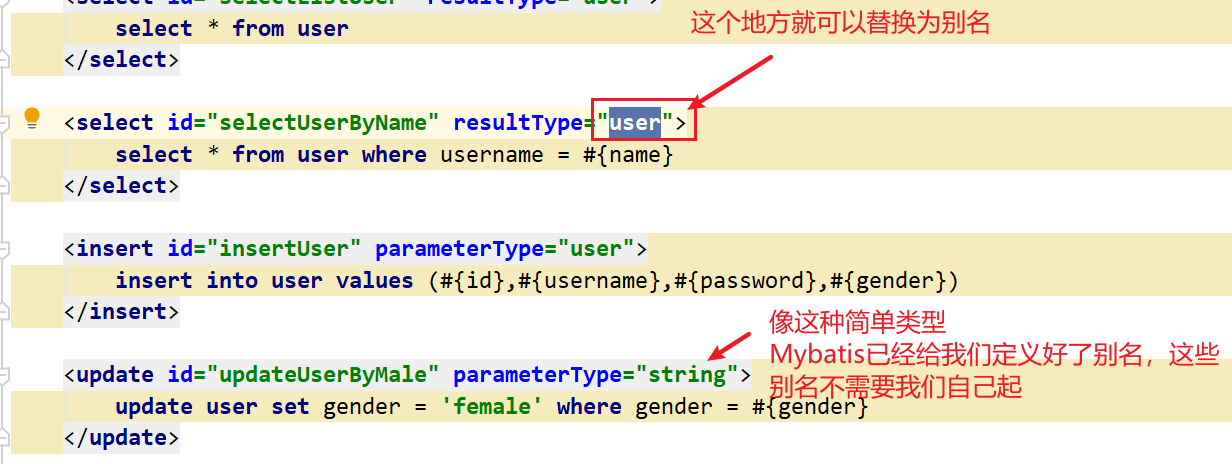
Mybatis给我们定义的内建别名
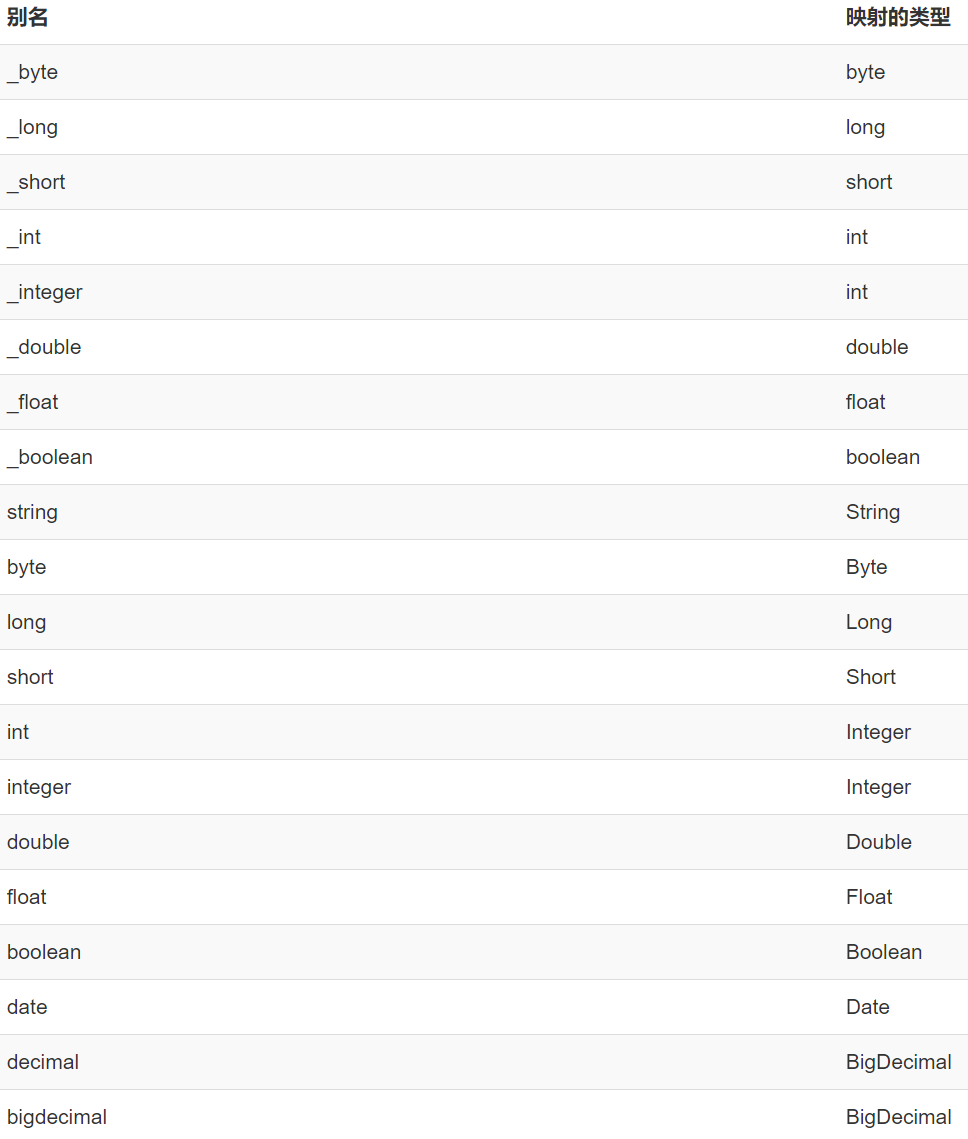
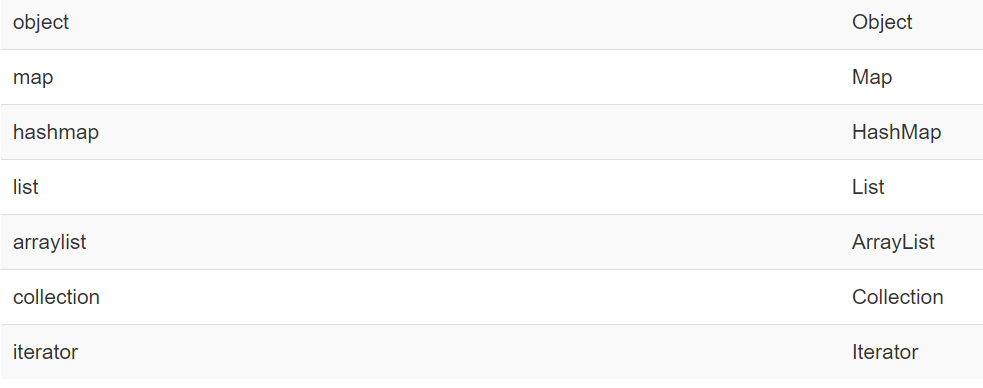
4.4 Mapper映射
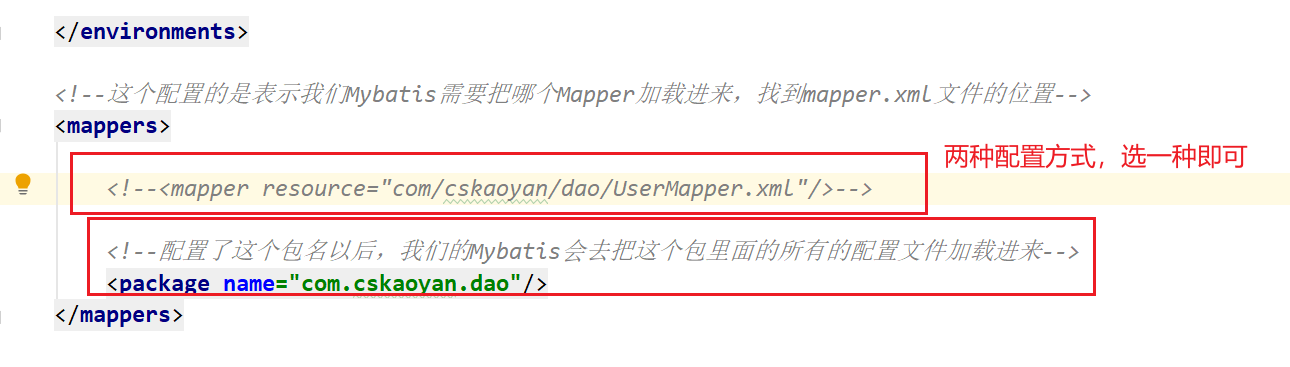
5. 输入映射
输入映射其实就是说我们在使用Mybatis的时候,可以给他传递什么样的参数?如何传递这些参数
5.1 传一个简单类型的参数
mapper
// 传一个简单类型的参数,这个简单参数可以是基本类型和String
User selectUserById(Integer id);
// 这个是使用注解
User selectUserByIdWithParam(@Param("lanzhao") Integer id);
xml
<!--这里我们的resultType可以使用别名,但是看你自己的编程习惯,如果使用全限定名称,可读性更强-->
<select id="selectUserById" resultType="com.cskaoyan.user.User">
select * from user where id = #{lanzhao}
</select>
<select id="selectUserByIdWithParam" resultType="com.cskaoyan.user.User">
select * from user where id = #{lanzhao}
</select>
说明:当我们传一个简单参数的时候
- 假如我们在参数里面加了@Param注解的时候,那么在后面xml文件中取值的时候一定要使用注解里面配置的value值来取值,不然会报错
- 假如没有在参数里面加@Param注解,那么后续在xml文件中去取值的时候,可以#{任意值} ,大括号里面可以是任意值
5.2 传多个简单类型的参数
mapper
/**
* 通过id和username去修改gender的值
*/
Integer updateUserGenderByIdAndName(@Param("id") Integer id,
@Param("username") String username,
@Param("gender") String gender);
xml
<update id="updateUserGenderByIdAndName">
update user set gender = #{gender} where id =#{id} and username =#{username}
</update>
总结:我们发现,在我们使用多个简单类型的参数进行传值的时候,假如我们没有在接口方法的参数前面加上@Param注解的话,后续Mybatis在获取参数的时候,会找不到参数,会报 bindingException(绑定异常),所以我们需要加上@Param注解,这一点和传一个简单类型的参数不一样
5.3 传一个POJO(JavaBean)
mapper
// 这个是通过JavaBean去传值
Integer insertUser(User user);
Integer insertUserWithParam(@Param("user") User user);
xml
<insert id="insertUser" parameterType="com.cskaoyan.user.User">
insert into user values (#{id},#{username},#{password},#{gender})
</insert>
<insert id="insertUserWithParam" parameterType="com.cskaoyan.user.User">
insert into user values (#{user.id},#{user.username},#{user.password},#{user.gender})
</insert>
说明:我们在使用Java对象进行传值的时候,假如我们没有使用@Param注解,那么我们获取值的时候直接在#{成员变量名}, 假如我们使用了@Param注解呢?例如@Param(value= “user”), 那我们在xml文件里面去取值的时候,应该这样来取 : #{user.成员变量名}
5.4 传一个Map
先说明,我们一般传值的时候不用map来传值,为什么呢?阿里巴巴开发手册中写了类似于这么一句话:如果我们使用Map来传值,那么我们对于Map中的键值对是不清楚的,也就是我们不清楚这个Map中到底有哪些键值对,我们并不能直接看到,所以这其实对开发者来说还行,但是对于代码的维护者来说十分不友好,所以一般不采用Map进行传值,如果有这种需求,那么我们也有替代的方案,我们可以把Map中的键值对给他封装到一个JavaBean中,然后采用对象来传值
mapper
// 通过map来传值
List<User> selectListByGenderAndId(Map<String,Object> map);
xml
<select id="selectListByGenderAndId" parameterType="map" resultType="com.cskaoyan.user.User">
select * from user where id > #{id} and gender = #{gender}
</select>
加了@Param之后,规则和JavaBean是一样的
我们使用Map去取值的时候,应该这么取 #{key}
5.5 通过位置传值
这些位置对应的是我们的接口的参数列表里面参数出现的位置,假如是第一个,可以用#{arg0}来取,也可用#{param1}来取
-
#{arg0},#{arg1}, #{arg2}, #{arg3}
-
#{param1}, #{param2}
mapper
// 通过位置来传值
Integer updateUserGenderByIdAndNameByIndex(Integer id, String username, String gender);
xml
<!--第一种-->
<update id="updateUserGenderByIdAndNameByIndex">
update user set gender = #{param3} where id =#{param1} and username =#{param2}
</update>
<!--第二种-->
<update id="updateUserGenderByIdAndNameByIndex">
update user set gender = #{arg2} where id =#{arg0} and username =#{arg1}
</update>
我们通过位置传值,大家觉得好不好用呢?
位置传值其实不好用,容易出错,所以这里不推荐大家使用,在实际的开发中也不推荐大家使用位置传值
5.6 #和$符号的区别
其实,我们也可以通过$符号去取值
我们发现,我们去取值的时候,也可以通过$去取值,对比一下和#去取值的日志
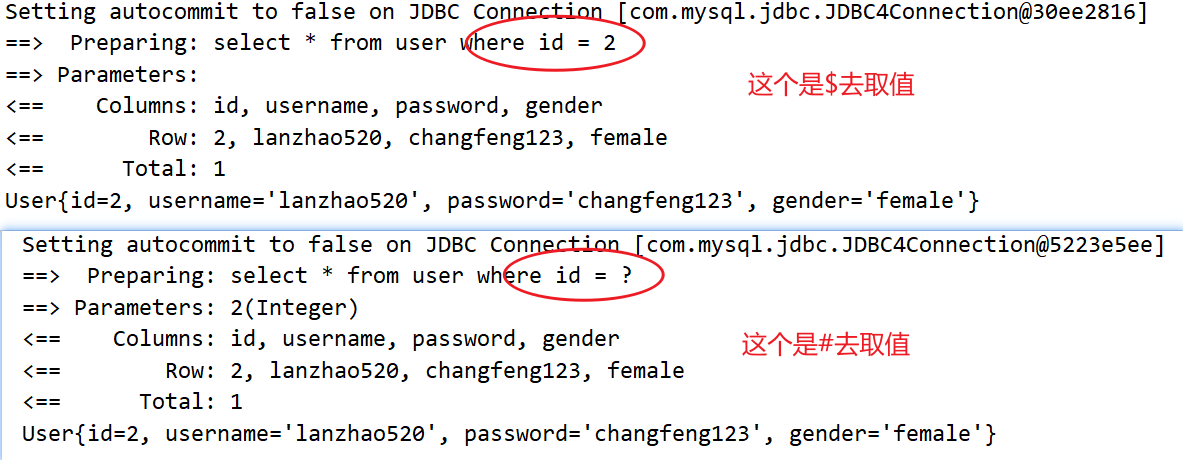
我们发现,$去取值的时候,其实是通过字符串拼接的方式去构建sql语句,底层是statement对象去工作的
而#去取值的时候,是通过 ?占位的方式去构建sql语句的,这个的底层是prepareStatement
通过以上我们得知,使用#去取值更安全,而使用$符号有sql注入的风险
那么问题来了,我们的$取值的方式是不是完全没有用武之地呢?
其实它有特殊的作用,有几个地方可以用的上,而 # 取代不了他
-
首先,我们的$符号,可以传递表名、列名,而#做不到
mapper
List<User> selectListByTableName(@Param("tableName") String tableName);xml
<select id="selectListByTableName" resultType="com.cskaoyan.user.User"> select * from ${tableName} </select> -
其次,我们在使用order by 、group by 这样的关键字的时候,假如我们order by、group by后面的参数是通过外界传入的,那么这个时候
#是取值有问题的,只能通过$ 来取值我们发现,order by可以通过#取到值,但是这个取到的值好像不正确,为啥不正确呢?
其实是我们的sql在进行预编译的时候,我们发现我们的sql语句是
select * from user order by ? desc limit 1,那么后面的desc没有生效,导致我们取到的结果是升序排序的第一行记录总结:其实就是order by 后面不能通过 #{} 来取值,只能通过
来
取
值
,
但
是
通
过
{} 来取值,但是通过
来取值,但是通过符号来取值的话,是不是会有sql注入的风险,这个风险来自于用户给你输入一些非法字符串,你想一下在现实生活中,我们有哪些网站是把这个排序的字段交给用户去输入的?
例如

他的这些排序的方式,其实排序的字段没有交给用户自己去输入,而是给用户提供了一些固定的排序的按钮,这些按钮后面就是对应着相应的字段,但是由于这个字段不是用户自己输入的,而是由程序员在开发程序的时候自己定义好的,所以我们在使用order by的时候才能避免这种sql注入的风险
- 实际开发中会用的$有分页,排序,like模糊查询等。(重点)
- 实际开发中,若动态查询表名,列名,拼接的sql则必须用$,否则会解析异常
6. 输出映射
6.1 简单对象
我们可以去Mybatis官网查询这些简单类型的别名
mapper
// 根据用户的id,获取用户的username
String selectUsernameById(@Param("id") Integer id);
// 查询一共有多少行记录
Integer selectCount();
xml
<select id="selectUsernameById" resultType="java.lang.String">
select username from user where id = #{id}
</select>
<select id="selectCount" resultType="int">
select count(1) from user
</select>
6.2 JavaBean
当我们的输出对象是一个JavaBean的时候,我们的resultType=“ ” ,引号内必须得配置这个输出映射对象的全限定名称,或者是这个全限定名称的别名
-
案例一
查询用户列表
mapper
List<User> selectUserList();xml
<select id="selectUserList" resultType="com.cskaoyan.user.User"> select * from user </select> -
案例二
假如我们要求查询出来的对象的成员变量名和数据库中表的字段的名字对应不上的话,那么我们可以通过在sql语句里面起别名的方式来解决

mapper
List<UserVO> selectUserVOList();
xml
<select id="selectUserVOList" resultType="com.cskaoyan.user.UserVO">
select id as id ,username as name ,password as passwd, gender as gender from user
</select>
我们通过使用as给列取别名的方式来解决了这个问题,这个别名就是我们JavaBean里面的字段名。
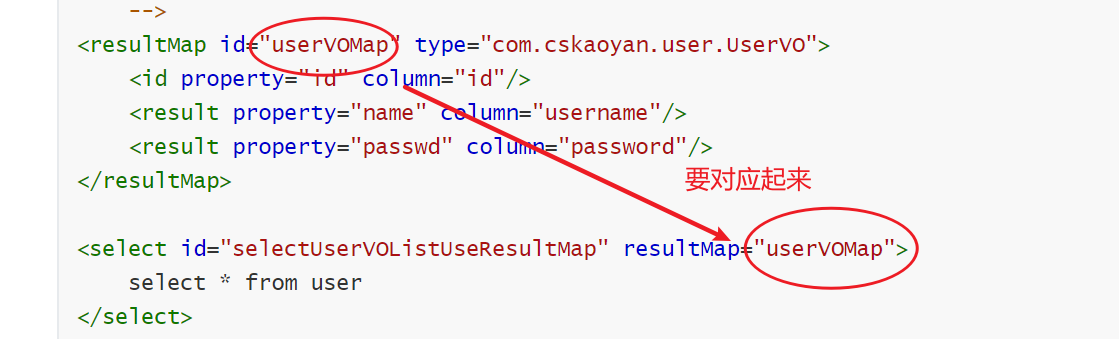
6.3 ResultMap
其实我们使用ResultMap也能解决这个问题,如何解决呢?
mapper
List<UserVO> selectUserVOListUseResultMap();
xml
<!--
id: 这个是resultMap的名字,在我们其他的sql片段中使用的时候要使用这个id的值
type:这个是指我们的resultMap映射为哪个对象
<id : 这个是指我们表里面的主键映射
property: 这里配置我们的JavaBean中的字段名字
column: 这个配置列名
javaType: 这个指的是我们的JavaBean中的字段的类型
jdbcType: 这个指的是我们数据库表中的字段的类型
javaType和jdbcType要对应起来,这两个可以省略
result: 如果是普通字段,就使用result标签就好了
这个resultMap此处显得有点繁琐,但是其实看起来比起别名要直观一些,而且在我们进行多表查询的时候很有用
-->
<resultMap id="userVOMap" type="com.cskaoyan.user.UserVO">
<id property="id" column="id"/>
<result property="name" column="username"/>
<result property="passwd" column="password"/>
</resultMap>
<select id="selectUserVOListUseResultMap" resultMap="userVOMap">
select * from user
</select>
注意一下:
7. DynamicSQL
动态SQL是什么呢?
动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦。
动态SQL其实就是Mybatis给我们提供了一些标签库,那么这些标签库可以根据条件,动态的去变化我们的SQL语句。
Mybatis动态sql给我们提供了很多标签,这些标签都是作用于sql语句的
7.1 where
where标签的作用
- 第一个用法,给sql语句里面拼装一个where关键字
- 假如where标签里面的if标签都没有满足条件的,那么<where> 不会给我么拼接 where关键字
- where标签会自动去除我们where标签里面的第一个and 或者 or关键字
mapper
User selectOneByIdWhere(@Param("id") Integer id);
List<User> selectListBySelective(User user);
xml
<select id="selectOneByIdWhere" resultType="user.User">
select * from user
<where>
id = #{id}
</where>
</select>
<select id="selectListBySelective" resultType="user.User">
select * from user
<where>
<if test="id != null">
and id = #{id}
</if>
<if test="username != null">
or username = #{username}
</if>
<if test="password != null">
and password = #{password}
</if>
<if test="gender != null">
and gender = #{gender}
</if>
</where>
</select>
7.2 if
<if>这个标签就是动态的去给我们的sql语句去做判断,根据传进来的值去做判断。
<if test=“required” >
上面test后面的内容其实就是需要我们跟一个OGNL表达式,这个OGNL表达式的结果是一个Boolean类型的值
== 等于
!= 不等于
gt 大于
lt 小于
gte 大于等于
lte 小于等于
顺便给大家提一下,我们的xml文件中有些特殊字符也不能使用,< > & ,这些要使用转义字符
转义前 转义后
& &
> >
< <
>= >=
<= <=
mapper
// 假如我们传进来的年龄大于20 那么就查询比20大或者等于20的员工,否则就查询比20小的员工
List<Employee> selectList(Employee employee);
xml
<!-- 假如我们传进来的年龄大于等于20 那么就查询比20大或者等于20的员工,否则就查询比20小的员工-->
<select id="selectList" resultType="user.Employee">
select * from employee
<where>
<if test="age gte 20">
and age >= 20
</if>
<if test="age lt 20">
and age < 20
</if>
</where>
</select>
7.3 SQL片段
意义:其实就是把一些反复利用的sql片段给他抽离出来,形成一个sql片段,这个sql片段可以反复利用
xml
<sql id="base_column">
id,age,name,gender
</sql>
<select id="selectListSql" resultType="user.Employee">
select <include refid="base_column"/>
from employee
<where>
<if test="age gte 20">
and age >= 20
</if>
<if test="age lt 20">
and age < 20
</if>
</where>
</select>
7.4 trim
这个标签是可以帮助我们动态去在sql语句里面去增加或者是减少一些字符
mapper
// 根据条件修改用户
Integer updateUserBySelective(Employee employee);
xml
<!--
trim 标签可以动态的帮助我们去增加或者删除sql里面的一些字段
prefix: 指在trim包起来的sql语句的前面去增加指定的字符
suffix: 指在trim包起来的sql语句的后面去增加指定的字符
suffixOverrides: 指在trim包起来的sql语句的后面去除指定的字符
prefixOverrides: 指在trim包起来的sql语句的前面去除指定的字符
update employee set name = #{name}, age = #{age},gender = #{gender}
where id = #{id}
-->
<update id="updateUserBySelective" parameterType="user.Employee">
update employee
<trim prefix="set" suffixOverrides=",">
<if test="name != null">
name = #{name},
</if>
<if test="age != null">
age = #{age},
</if>
<if test="gender != null">
gender = #{gender},
</if>
</trim>
<where>
id = #{id}
</where>
</update>
7.5 set
说明:
<set> 这个标签和 <trim prefix="set" suffixOverrides=","> 等价
<update id="updateUserBySelectiveBySET" parameterType="user.Employee">
update employee
<set>
<if test="name != null">
name = #{name},
</if>
<if test="age != null">
age = #{age},
</if>
<if test="gender != null">
gender = #{gender},
</if>
</set>
<where>
id = #{id}
</where>
</update>
7.6 foreach
最常用的场景
-
in语句
mapper
// foreach 根据id的list去查询用户 例如:select * from employee where id in (1,2,3,4); List<Employee> selectEmployeeByIds(List<Integer> ids);xml
<!-- foreach 表示去循环遍历一个集合 collection:表示这个集合的名称,假如我们传进来的集合没有名称(没有加@Param注解),那么就是list,如果有名称,那么就使用指定的名称 open:表示这个循环以什么开始 close:表示这个循环以什么符号结束 separator: 表示我们循环中的每个元素以什么符号分隔开 index:表示我们每个元素的下标 item:指代我们集合中的每个元素 --> <select id="selectEmployeeByIds" parameterType="int" resultType="user.Employee"> select <include refid="base_column"/> from employee <where> id in <foreach collection="list" open="(" close=")" separator="," index="index" item="id"> #{id} </foreach> </where> </select>说明:如下图所示我们的collection的值和我们传进来的集合的名称一定要对应上,假如你传进来的集合没有指定名称,那么就使用 list
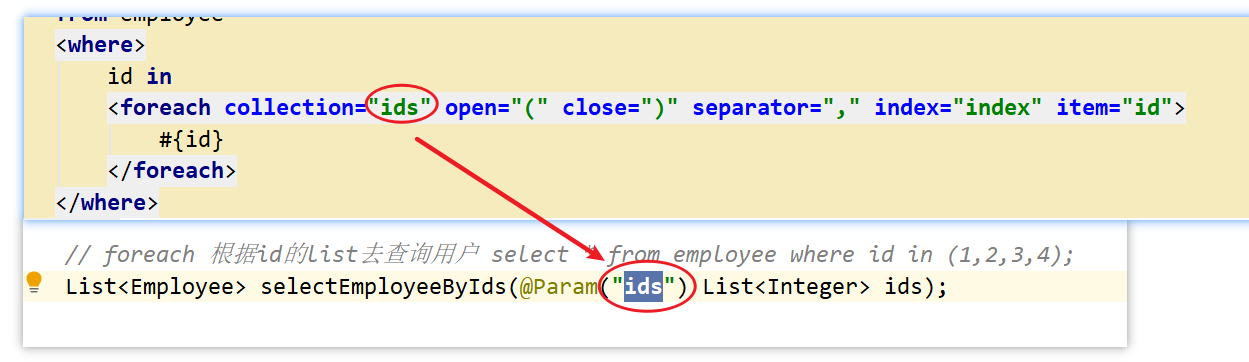
-
批量插入
mapper
// 批量插入 Integer insertBatch(@Param("employeeList") List<Employee> employeeList);xml
<insert id="insertBatch" parameterType="user.Employee"> insert into employee values <foreach collection="employeeList" separator="," item="employee"> (#{employee.id},#{employee.name},#{employee.age},#{employee.gender}) </foreach> </insert>
7.7 choose when
<choose><when> 标签就相当于我们Java中的 if{} else {}
mapper
// 假如我们传进来的年龄大于20 那么就查询比20大或者等于20的员工,否则就查询比20小的员工
List<Employee> selectList(Employee employee);
// 上面是<if>标签
List<Employee> selectListByAge(@Param("age") Integer age);
xml
<!-- 假如我们传进来的年龄大于等于20 那么就查询比20大或者等于20的员工,否则就查询比20小的员工-->
<select id="selectList" resultType="user.Employee">
select * from employee
<where>
<if test="age gte 20">
and age >= 20
</if>
<if test="age lt 20">
and age < 20
</if>
</where>
</select>
<select id="selectListByAge" resultType="user.Employee">
select * from employee
<where>
<choose>
<when test="age gte 20">
and age >= 20
</when>
<otherwise>
and age < 20
</otherwise>
</choose>
</where>
</select>
7.8 selectKey
<selectKey> 这个标签是可以帮助我们做一些事情,在我们的sql语句执行之前或者是之后帮我们额外的执行一条sql语句
例如我们的数据库的主键是自增的,那么我们在插入数据的时候,我们假如不指定这个主键(也就是说把主键交给数据库去维护) 那么在某些业务场景下,假如我们插入了一条数据,我们需要知道这条数据在表中的主键的话,那么就可以使用<selectKey>
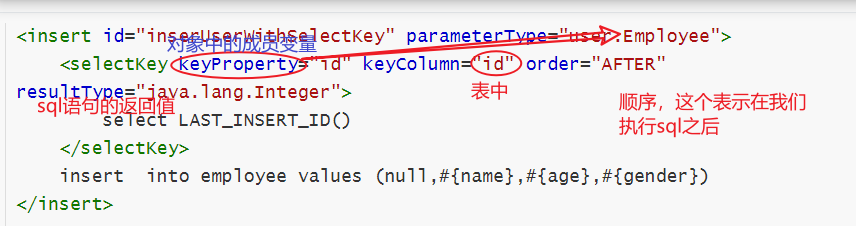
注意一下,我们的这个keyProperty需要和我们传入进来的参数名字对应上,规则和#{}这个里面取值的规则是一样的
// 插入一条员工记录
Integer inserUserWithSelectKey(Employee employee);
// 插入一条员工记录
Integer inserUserWithSelectKey2(@Param("employee") Employee employee);
xml
<insert id="inserUserWithSelectKey" parameterType="user.Employee">
<selectKey keyProperty="id" keyColumn="id" order="AFTER" resultType="java.lang.Integer">
select LAST_INSERT_ID()
</selectKey>
insert into employee values (null,#{name},#{age},#{gender})
</insert>
<insert id="inserUserWithSelectKey2" parameterType=user.Employee">
<selectKey keyProperty="employee.id" keyColumn="id" order="AFTER" resultType="java.lang.Integer">
select LAST_INSERT_ID()
</selectKey>
insert into employee values (null,#{employee.name},#{employee.age},#{employee.gender})
</insert>
7.9 useGeneratedKeys
这个不是一个标签,而是一个属性
<insert useGeneratedKeys="true" ... />
这个属性的意思是说,需不需要我们获取mysql自动帮助我们生成的主键,如果是true,会帮我们获取,如果是false,那么就不会


8 插件介绍
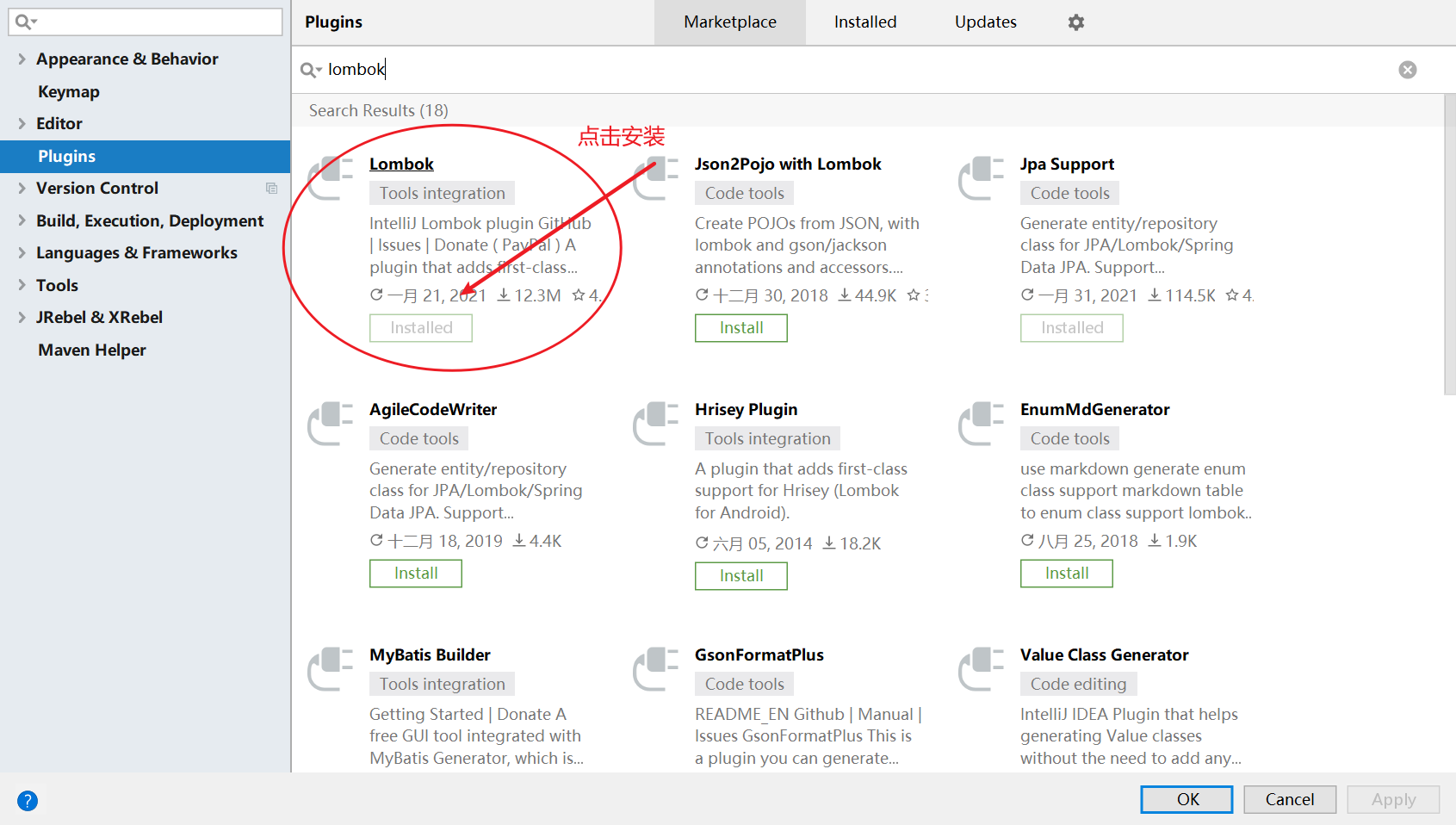
8.1 Lombok
这个工具是用来帮助我们去生成一个JavaBean里面的getter、setter、toString、equals方法的
-
导包
<dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.12</version> </dependency> -
需要我们下载一个插件
-
注解介绍
@Getter // 生成Getter方法 @Setter // 生成Setter方法 @ToString // 生成toString 方法 @NoArgsConstructor // 生成无参构造 @AllArgsConstructor // 生成全参构造 @Data // 生成getter、setter、toString、无参构造、 //equals、hashCode、canEqual这些方法
Lombok好不好呢?
- 好:可以帮助我们很方便的去生成对应的代码(编译的时候生成),大大的简化了我们的代码量,可以让我们的代码看起来更加整洁
- 不好: Lombok有点强制传播性,也就是说,在公司里面去协作开发的时候,假如一个人使用了Lombok,那么是不是要求团队的所有都来使用,这点其实不够友好
8.2 Mybatis的插件
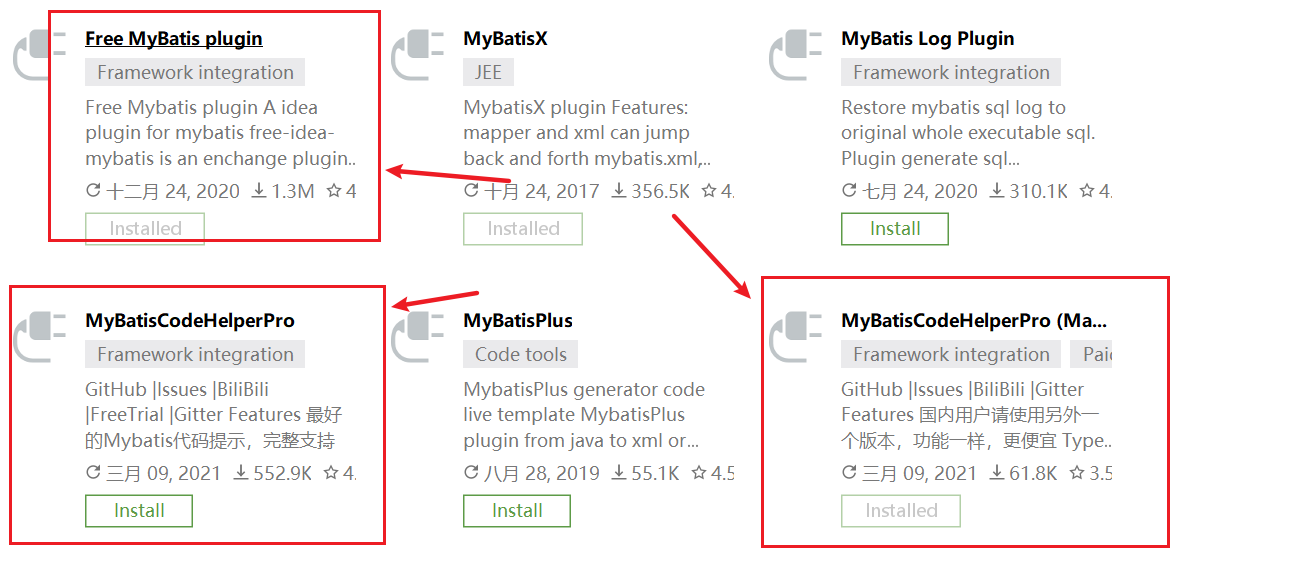
可以选择以上的三个,任意选一个
功能:
-
帮助我们完成mapper文件与xml文件之间的快速跳转
-
帮助我们去在xml文件里面生成<select><insert> <update> <delete>标签
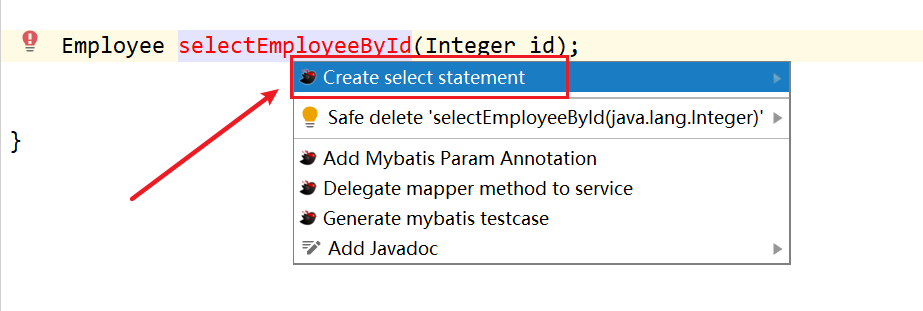
- 可以快速帮助我们去生成@Param注解

-
可以帮助我们去写sql语句,甚至可以帮助我们去排错
-
可以帮助我们去测试sql语句(收费功能)
底层:其实就是用了Java agent 以及去做了一些idea的插件
9 多表查询
9.1 一对一
一对一的数据模型有哪些?
学生和学生详情、商品和商品详情、商品和库存
选择商品和库存这个模型
-
建表
商品表
create table products ( id int primary key auto_increment, name varchar(255), price decimal(10,2) )库存表
create table stock( id int primary key auto_increment, num int, product_id int ) -
插入数据
-
创建JavaBean
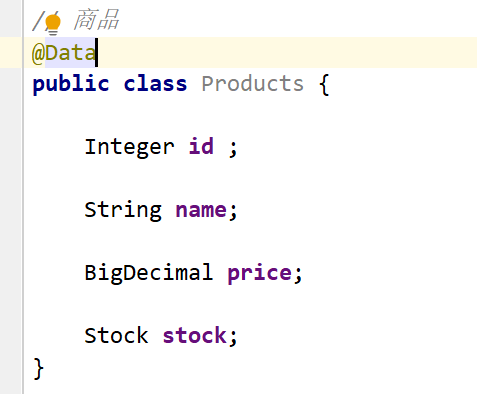
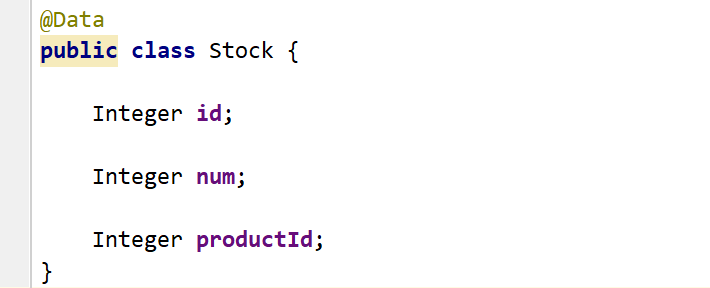
然后去写sql
9.1.1 分次查询
mapper
Products selectById(@Param("id") Integer id);
xml
<!-- 分次查询 -->
<!--
第一次查询: select id,name,price from priducts where id = #{id}
第二次查询: select id,num,product_id from stock where product_id = #{id}
association: 一个复杂类型的关联;许多结果将包装成这种类型
property: 这个是复杂类型成员变量的名字
column: 这个是分次查询的时候需要传递过去的参数列名
javaType: 这个是我们复杂类型成员变量的类型
select:这个是我们分次查询的sql语句的坐标,namespace+id
-->
<resultMap id="productsMap" type="user.Products">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="price" property="price"/>
<association property="stock" javaType="user.Stock" column="id" select="ProductsMapper.selectStockByProductId"/>
</resultMap>
<!--查询入口-->
<select id="selectById" resultMap="productsMap">
select id,name,price from products where id = #{id}
</select>
<select id="selectStockByProductId" resultType="user.Stock">
select id,num,product_id as productId from stock where product_id = #{id}
</select>
9.1.2 连接查询
mapper
Products selectByIdUseCrossQuery(@Param("id") Integer id);
xml
<!-- 连接查询 -->
<resultMap id="productCrossMap" type="user.Products">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="price" property="price"/>
<association property="stock" javaType="user.Stock">
<result column="sid" property="id"/>
<result column="num" property="num"/>
<result column="productId" property="productId"/>
</association>
</resultMap>
<select id="selectByIdUseCrossQuery" resultMap="productCrossMap">
SELECT
p.id as id,
p.name as name,
p.price as price,
s.id as sid,
s.num as num,
s.product_id as productId
FROM
products AS p,
stock AS s
WHERE
p.id = s.product_id
AND p.id = #{id}
</select>
9.2 一对多
模型:班级和学生、省份和城市
采用班级和学生这种模型
-
创建班级表
create table clazz ( id int primary key auto_increment, name varchar(20) ) -
创建学生表
create table stu( id int primary key auto_increment, name varchar(20), age int, gender varchar(20), clazz_id int )
9.2.1 分次查询
mapper
// 一对多分次查询
Clazz selectClazzByIdWithStudents(@Param("id") Integer id);
xml
<resultMap id="clazzCrossMap" type="user.Clazz">
<id column="id" property="id"/>
<result column="name" property="name"/>
<!--
分次查询使用说明:
1. 需要使用collection标签
2. 之前一对一的时候使用的是javaType,这个地方要是使用ofType
-->
<collection property="stuList" ofType="user.Stu" column="id" select="ClazzMapper.selectStuByClazzId"/>
</resultMap>
<select id="selectClazzByIdWithStudents" resultMap="clazzCrossMap">
SELECT
id,
name
from clazz where id = #{id}
</select>
<select id="selectStuByClazzId" resultType="user.Stu">
SELECT
id,name,age,gender,clazz_id as classId
from stu where clazz_id = #{id}
</select>
9.2.2 连接查询
mapper
// 一对多连接查询
Clazz selectClazzByIdWithStudentsLeftJoin(@Param("id") Integer id);
xml
<resultMap id="leftjoinMap" type="user.Clazz">
<id column="id" property="id"/>
<result column="name" property="name"/>
<collection property="stuList" ofType="user.Stu">
<result column="sid" property="id"/>
<result column="sname" property="name"/>
<result column="age" property="age"/>
<result column="gender" property="gender"/>
<result column="classId" property="classId"/>
</collection>
</resultMap>
<select id="selectClazzByIdWithStudentsLeftJoin" resultMap="leftjoinMap">
SELECT
c.id as id,
c.name as name,
s.id as sid,
s.name as sname,
s.age as age,
s.gender as gender,
s.clazz_id as classId
FROM
clazz AS c
LEFT OUTER JOIN stu AS s ON c.id = s.clazz_id
WHERE
c.id = #{id}
</select>
总结

9.3 多对多
其实和一对多是一样的
多对多的模型
学生和课程

9.3.1 分次查询
mapper
// 根据学生id 查询学生信息以及他的选课信息
Stu selectStudentByIdWithCourses(@Param("id") Integer id);
xml
<!-- 多对多分次查询start-->
<resultMap id="stuMap" type="user.Stu">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="age" property="age"/>
<result column="gender" property="gender"/>
<result column="classId" property="classId"/>
<collection property="courseList" ofType="user.Course" select="StuMapper.selectCourseByStuId" column="id"/>
</resultMap>
<select id="selectStudentByIdWithCourses" resultMap="stuMap">
select
id,
name,
age,
gender,
clazz_id as classId
from stu where id = #{id}
</select>
<select id="selectCourseByStuId" resultType="user.Course">
SELECT
c.id AS id,
c.NAME AS name
FROM
s_t AS st
LEFT JOIN course AS c ON c.id = st.c_id
WHERE
st.s_id = #{id}</select>
<!-- 多对多分次查询 end-->
9.3.2 连接查询
连接查询其实就是一条sql语句解决问题
分析:sql语句应该是长这个样子的
-- 多对多连接查询
-- 要通过学生的id去查询出这个学生的信息以及他的选课信息
SELECT
s.id as id,
s.name as name,
s.age as age,
s.gender as gender,
s.clazz_id as classId,
c.id as cid,
c.name as cname
FROM
stu AS s
LEFT JOIN s_t AS st ON s.id = st.s_id
LEFT JOIN course AS c ON st.c_id = c.id
WHERE
s.id = 1;
mapper
// 多对多连接查询
Stu selectStudentByIdCrossJoinWithCourses(@Param("id") Integer id);
xml
<!-- 多对多连接查询 start-->
<resultMap id="stuCrossMap" type="user.Stu">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="age" property="age"/>
<result column="gender" property="gender"/>
<result column="classId" property="classId"/>
<collection property="courseList" ofType="user.Course">
<result column="cid" property="id"/>
<result column="cname" property="name"/>
</collection>
</resultMap>
<select id="selectStudentByIdCrossJoinWithCourses" resultMap="stuCrossMap">
SELECT
s.id as id,
s.name as name,
s.age as age,
s.gender as gender,
s.clazz_id as classId,
c.id as cid,
c.name as cname
FROM
stu AS s
LEFT JOIN s_t AS st ON s.id = st.s_id
LEFT JOIN course AS c ON st.c_id = c.id
WHERE
s.id = #{id}
</select>
<!-- 多对多连接查询 end-->
探讨:关于连接查询应该还是不应该使用呢?(这个是以后开发中遇到的实际的问题)
连接查询,多个表的笛卡尔积
假如A表有100w数据,假如B表也有100w条数据,那么这个时候A X B (笛卡尔积) 就会有1www条数据,这个数据量就很夸张了
考虑一下Mysql单表的查询性能(800w-1000w左右)在这个时候达到峰值,如果数据量再增加,那么Mysql去做查询的时候会很慢,所以一般来说单表设计的时候不要超过这么多条数据
那应不应该使用 连接查询呢?
看情况,假如做得项目数据量很大(面向用户的、例如商城、微信、淘宝),这个时候谨慎使用连接查询,假如是数据量不大的项目(内部管理系统、ORM、物流管理系统、政府网站的管理系统之类的),就不用考虑性能,可以使用连接查询
阿里巴巴开发手册规定了,阿里不允许使用三次连接以及以上的查询
10 懒加载
懒加载是指在使用多表查询的分次查询的时候,可以不立即执行我们的第二个sql语句,而是在我们需要用到里面的成员变量的时候再去执行。
懒加载其实是帮助我们去优化性能的
如何开启呢?
mybatis-config.xml
<!-- 懒加载-->
<setting name="lazyLoadingEnabled" value="true"/>
mapper.xml

发现,当需要用到我们的products里面的stock的时候,才会去执行第二条sql语句,假如不用products里面的stock,那么就不会加载第二条sql语句
11 缓存
缓存,cache
工作的流程
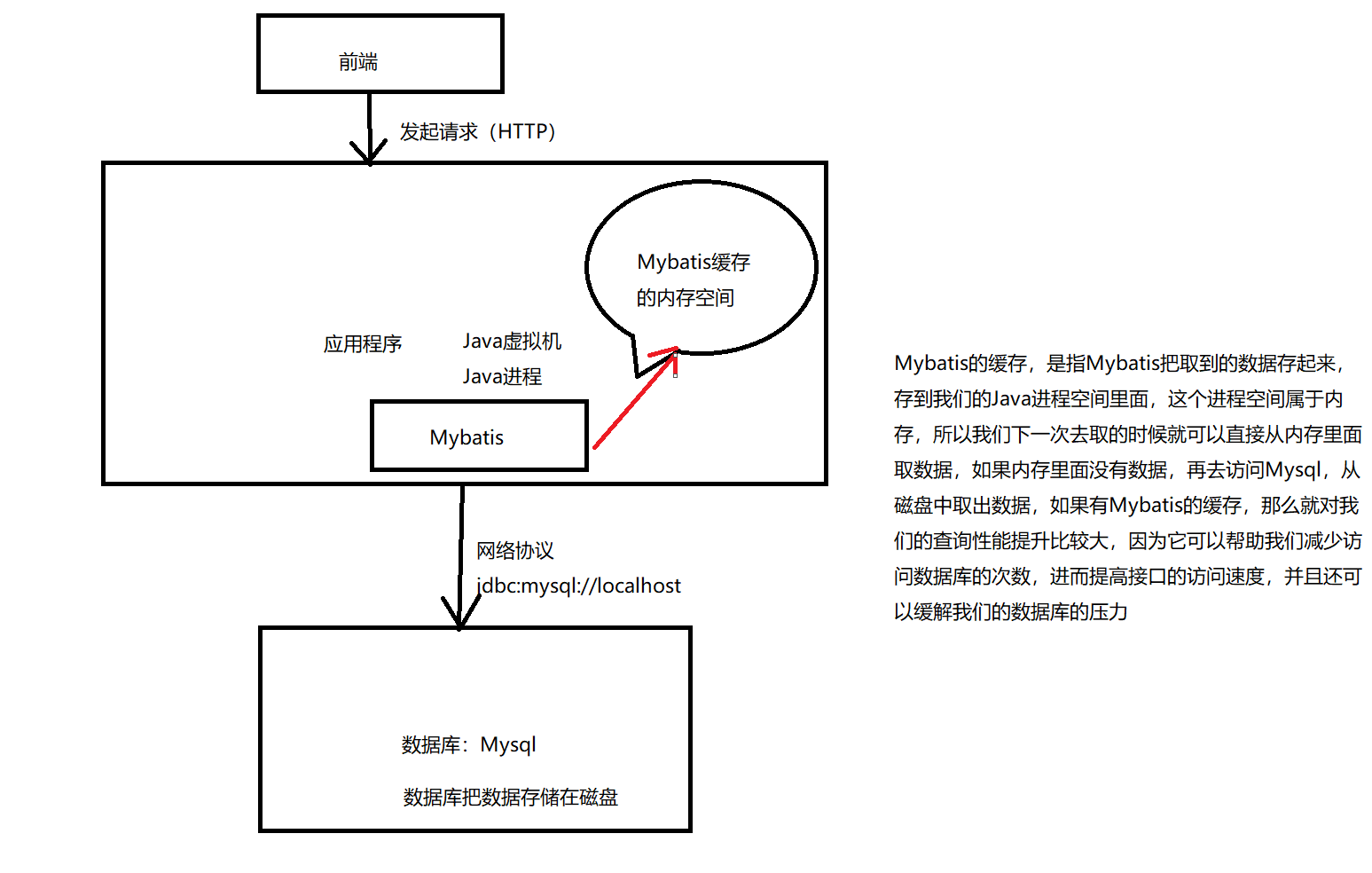
11.1 一级缓存
**一级缓存其实是sqlSession级别的。**也就是假如我们使用同一个sqlSession去多次查询同一个sql语句,并且传入的条件是一样的,那么只有第一次会去查询数据库,后面的请求都会去我们的缓存空间里面去查
// 测试一级缓存
@Test
public void testSelectStuById(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
StuMapper mapper1 = sqlSession.getMapper(StuMapper.class);
StuMapper mapper2 = sqlSession.getMapper(StuMapper.class);
StuMapper mapper3 = sqlSession.getMapper(StuMapper.class);
StuMapper mapper4 = sqlSession.getMapper(StuMapper.class);
Stu stu1 = mapper1.selectStuById(1); //从数据库查
sqlSession.commit(); // 提交了之后会使一级缓存失效
Stu stu2 = mapper2.selectStuById(1); // 从缓存中查
Stu stu3 = mapper3.selectStuById(1); // 从缓存中查
Stu stu4 = mapper4.selectStuById(1); // 从缓存中查
System.out.println(stu1);
System.out.println(stu2);
System.out.println(stu3);
System.out.println(stu4);
}
// 测试一级缓存
@Test
public void testSelectStuById2(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
StuMapper mapper1 = sqlSession.getMapper(StuMapper.class);
Stu stu1 = mapper1.selectStuById(1); //从数据库查
Stu stu2 = mapper1.selectStuById(1); // 从缓存中查
Stu stu3 = mapper1.selectStuById(1); // 从缓存中查
Stu stu4 = mapper1.selectStuById(1); // 从缓存中查
System.out.println(stu1);
System.out.println(stu2);
System.out.println(stu3);
System.out.println(stu4);
}
// 测试一级缓存
@Test
public void testSelectStuById3(){
SqlSession sqlSession1 = MybatisUtils.getSqlSession();
SqlSession sqlSession2 = MybatisUtils.getSqlSession();
SqlSession sqlSession3 = MybatisUtils.getSqlSession();
SqlSession sqlSession4 = MybatisUtils.getSqlSession();
StuMapper mapper1 = sqlSession1.getMapper(StuMapper.class);
StuMapper mapper2 = sqlSession2.getMapper(StuMapper.class);
StuMapper mapper3 = sqlSession3.getMapper(StuMapper.class);
StuMapper mapper4 = sqlSession4.getMapper(StuMapper.class);
Stu stu1 = mapper1.selectStuById(1); //从数据库查
Stu stu2 = mapper2.selectStuById(1); // 从数据库查
Stu stu3 = mapper3.selectStuById(1); // 从数据库查
Stu stu4 = mapper4.selectStuById(1); // 从数据库查
System.out.println(stu1);
System.out.println(stu2);
System.out.println(stu3);
System.out.println(stu4);
}
总结:
/**
* 结论:Mybatis的一级缓存默认是开启的,在这里什么时候一级缓存会生效呢?
* 1. sql语句要是同一个
* 2. 参数列表以及值保持一致
* 3. 我们使用的mapper要取自同一个sqlSession,假如是不同的sqlSession的话,那么就取不到一级缓存
*
* 什么时候一级缓存失效呢?
* 当我们的sqlSession提交或者关闭的时候,就失效了
*
*/
11.2 二级缓存
二级缓存是Namespace级别的。
如何开启二级缓存呢?
默认没有开启。如何开启呢?
-
第一步:要去Mybatis-config.xml文件中开启二级缓存
<!-- 二级缓存总开关--> <setting name="cacheEnabled" value="true"/> -
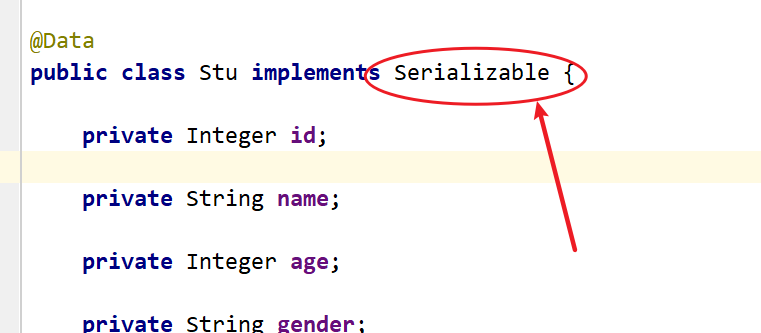
第二步:我们需要把查询的对象进行序列化,也就是实现序列化接口
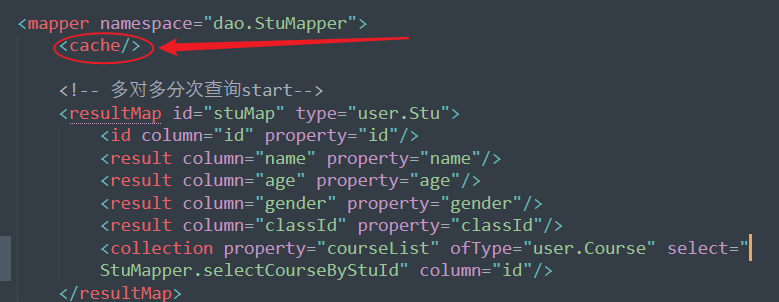
- 第三步:需要在我们需要配置的namespace对应的mapper.xml文件中加入一个标签,<cache/>
测试:
@Test
public void testLevel2Cache(){
SqlSessionFactory factory = MybatisUtils.getFactory();
SqlSession sqlSession1 = factory.openSession();
SqlSession sqlSession2 = factory.openSession();
SqlSession sqlSession3 = factory.openSession();
SqlSession sqlSession4 = factory.openSession();
SqlSession sqlSession5 = factory.openSession();
StuMapper mapper1 = sqlSession1.getMapper(StuMapper.class);
StuMapper mapper2 = sqlSession2.getMapper(StuMapper.class);
StuMapper mapper3 = sqlSession3.getMapper(StuMapper.class);
StuMapper mapper4 = sqlSession4.getMapper(StuMapper.class);
StuMapper mapper5 = sqlSession5.getMapper(StuMapper.class);
Stu stu1 = mapper1.selectStuById(1); //从数据库查
// 存入缓存 这一步不能忘了
sqlSession1.commit();
sqlSession1.close();
Stu stu2 = mapper2.selectStuById(1); // 从数据库查
Stu stu3 = mapper3.selectStuById(1); // 从数据库查
Stu stu4 = mapper4.selectStuById(1); // 从数据库查
Stu stu5 = mapper5.selectStuById(1); // 从数据库查
System.out.println(stu1);
System.out.println(stu2);
System.out.println(stu3);
System.out.println(stu4);
System.out.println(stu5);
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/181120.html

