
在 CentOS 8 上配置 PostgreSQL 14 的主从复制,并设置 WAL 归档到特定路径 /home/postgres/archive 的步骤如下:
主服务器配置(主机)
-
配置 PostgreSQL:
- 编辑
postgresql.conf文件:
vim /data/postgres/pgdata/postgresql.conf- 设置以下参数:
listen_addresses = '*' # 允许所有地址连接 wal_level = replica # 设置 WAL 级别为 replica max_wal_senders = 10 # 设置最大 WAL 发送者数量 archive_mode = on # 打开归档模式 archive_command = 'cp %p /home/postgres/archive/%f' # 设置 WAL 归档命令 - 编辑
-
配置客户端认证文件(pg_hba.conf):
- 允许从服务器连接到主服务器:
vim /data/postgres/pgdata/pg_hba.conf- 添加以下行:
host replication replica_user slave_ip/32 trust其中
replica_user是复制用户,slave_ip是从服务器的 IP 地址。 -
创建复制用户:
psql -c "CREATE USER replica_user REPLICATION LOGIN CONNECTION LIMIT 5;" -
创建归档目录:
sudo mkdir -p /home/postgres/archive sudo chown postgres:postgres /home/postgres/archive sudo chmod 700 /home/postgres/archive -
重启 PostgreSQL 服务:
sudo systemctl restart postgresql-14
从服务器配置(从机)
-
停止 PostgreSQL 服务:
sudo systemctl stop postgresql-14 -
清空数据目录:
- 确保
/data/postgres/pgdata/目录是空的。
sudo rm -rf /data/postgres/pgdata/* - 确保
-
使用 pg_basebackup 复制数据:
sudo -u postgres pg_basebackup -h master_ip -D /data/postgres/pgdata/ -U replica_user -v -P -R --wal-method=stream其中
master_ip是主服务器的 IP 地址。这里要加-R 会自动创建standby.signal文件 -
配置
postgresql.conf:vim /data/postgres/pgdata/postgresql.conf- 添加或修改以下行:
primary_conninfo = 'host=master_ip user=replica_user' hot_standby = on
以下是相应的 sed 命令:
4.1. 对于 primary_conninfo,我们将取消注释该行并设置正确的主服务器 IP 地址(在这个例子中是 192.168.1.194)和复制用户(replica_user):
sed -i "/^#primary_conninfo/c\primary_conninfo = 'host=192.168.1.194 user=replica_user'" /data/postgres/pgdata/postgresql.conf
4.2. 对于 hot_standby,我们将取消注释该行并确保它设置为 on:
sed -i "/^#hot_standby =/c\hot_standby = on" /data/postgres/pgdata/postgresql.conf
这些命令会查找以 #primary_conninfo 和 #hot_standby 开头的行,并用新的配置行替换它们。
- 启动 PostgreSQL 服务:
sudo systemctl start postgresql-14
验证复制和归档状态
-
在主服务器上验证复制状态:
sudo -u postgres psql -c "SELECT * FROM pg_stat_replication;" -
在从服务器上验证是否处于恢复模式:
sudo -u postgres psql -c "SELECT pg_is_in_recovery();" -
检查 WAL 归档:
- 确认
/home/postgres/archive目录中是否有 WAL 文件被归档。
- 确认
注意事项
- 确保归档目录
/home/postgres/archive有足够的磁盘空间。 - 定期监控和管理归档目录,以防止其过度增长。
- 在生产环境中,考虑实施更复杂的归档策略。
这些步骤涉及基本的主从复制和 WAL 归档配置,具体需求和环境可能需要额外的调整和优化。
hot_standby = on 这个配置在 PostgreSQL 中 postgresql.conf用于启用热备服务器(Hot Standby)的功能,这是在只读模式下运行的备份服务器。这个功能通常用于以下情况:
示例场景:故障转移和负载平衡
假设您有一个生产数据库环境,其中包含一个主服务器(Primary Server)和一个或多个备份服务器(Standby Servers)。在这个设置中,hot_standby = on 会在备份服务器上使用。
故障转移(Failover)
- 主服务器故障:如果主服务器出现故障,您可以迅速切换到热备服务器。由于热备服务器一直在接收并应用主服务器的 WAL 记录,因此它能够快速升级为新的主服务器,几乎不中断服务。
- 维护期间:在主服务器进行维护或升级期间,可以将流量切换到热备服务器,以保持服务的可用性。
负载平衡(Load Balancing)
- 读取操作分流:在高负载情况下,为了减轻主服务器的压力,可以将读取请求(如报告生成、数据分析等)重定向到热备服务器,从而实现读取操作的负载平衡。
如何工作
- 当
hot_standby设置为on时,备份服务器以只读模式运行,可以接受用户的查询请求,但不允许任何写操作。 - 备份服务器通过流复制(Streaming Replication)或者定期应用 WAL 日志文件来保持与主服务器的数据一致。
优点
- 高可用性:在主服务器不可用时,可以快速切换到热备服务器,保证服务的持续运行。
- 减少主服务器负载:将读取操作重定向到备份服务器,减轻主服务器的负载。
- 即时数据恢复:因为备份服务器持续同步主服务器的数据,所以在需要时可以快速恢复数据。
总之,hot_standby = on 是 PostgreSQL 中用于提高数据库可用性和灵活性的重要配置,特别是在需要高可用性和负载平衡的生产环境中。
报错解决:
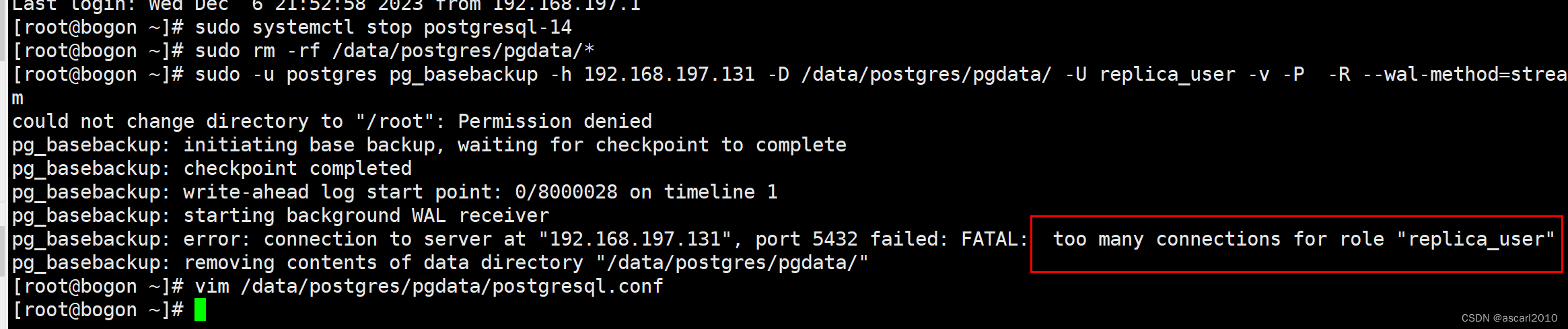
要修改 PostgreSQL 中已经创建的用户的连接限制数,您可以使用 ALTER USER 命令。在您的案例中,如果您想将 replica_user 用户的连接限制从当前值更改为 5,您应该执行以下命令:
ALTER USER replica_user CONNECTION LIMIT 5;
这个命令将更新用户 replica_user 的连接限制数为 5。请确保在执行此命令时您有足够的权限来修改用户设置。
如果您需要在 psql 命令行工具中执行此命令,可以使用以下格式:
psql -c "ALTER USER replica_user CONNECTION LIMIT 5;"
请确保在适当的数据库环境中执行这个命令,或者在命令中指定需要连接的数据库。
相关结果说明:

这个命令 SELECT * FROM pg_stat_replication; 在 PostgreSQL 中用于显示关于当前正在进行的复制进程的信息。这是一种监控和管理数据库复制状态的方法。输出的每一行代表一个活动的复制进程。我将解释每个字段的含义:
-
pid: 这是负责复制的进程的进程ID。
-
usesysid: 用户的系统ID。
-
usename: 正在进行复制的用户的名称。
-
application_name: 连接到数据库的应用程序的名称。
-
client_addr: 正在进行复制的客户端的IP地址。
-
client_hostname: 客户端的主机名(如果可用)。
-
client_port: 客户端连接到服务器的端口号。
-
backend_start: 后台进程开始的时间。
-
backend_xmin: 用于复制的事务ID的最小值(如果可用)。
-
state: 复制的当前状态,例如 “streaming” 表示正在进行流式复制。
-
sent_lsn, write_lsn, flush_lsn, replay_lsn: 这些是日志序列号(LSN),分别表示服务器发送的最后一个日志位置、写入的、刷新的和重放的。
-
write_lag, flush_lag, replay_lag: 这些字段表示写入延迟、刷新延迟和重放延迟。
-
sync_priority: 同步复制的优先级。
-
sync_state: 同步状态,例如 “async” 表示异步复制。
-
reply_time: 最后一次收到复制确认的时间。
在您提供的输出中,有两个复制进程正在进行,都是由用户 replica_user 发起的,分别连接自IP地址 192.168.197.130 和 192.168.197.128。两个进程都处于 “streaming” 状态,表明它们正在活跃地进行数据复制。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/181520.html

