
MySQL的InnoDB是支持事务的,事务的四大特性ACID底层实现是下面这些组件相互配合实现的:事务的原子性、一致性、持久性是通过redo log和undo log配合实现的;而隔离性是需要mvcc + lock的支持。
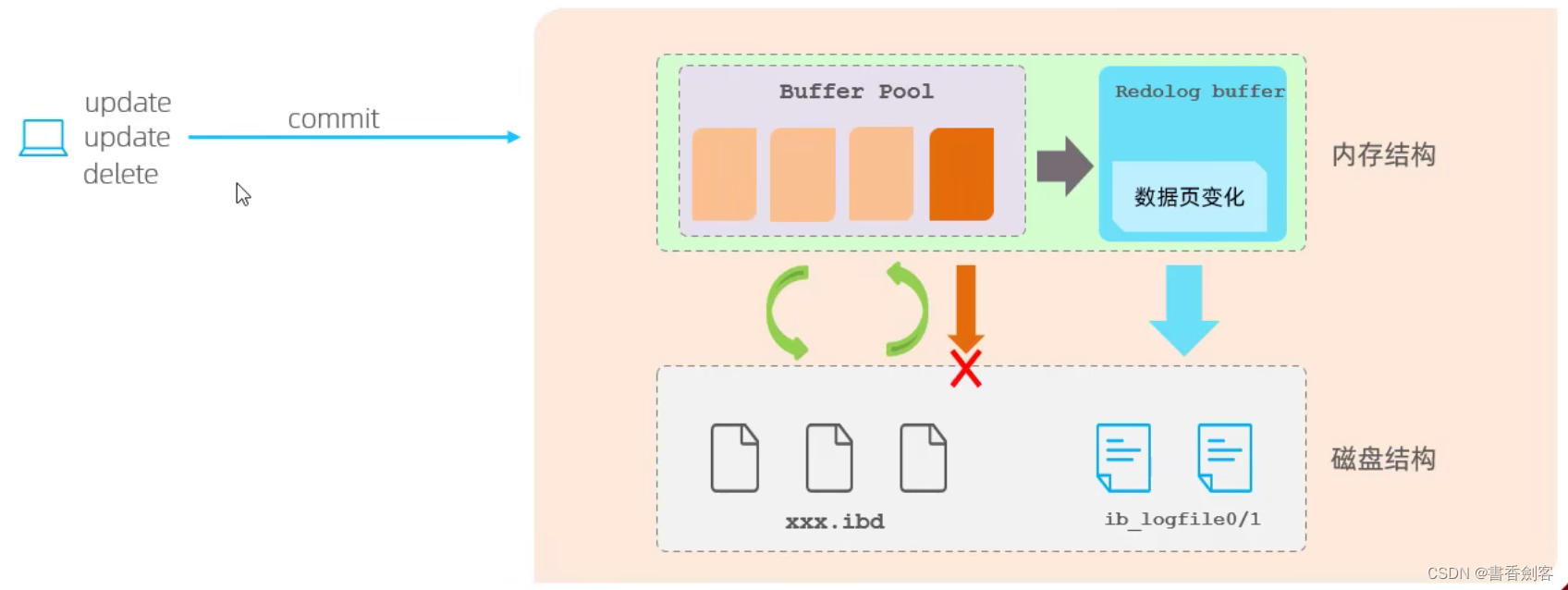
redo log:重做日志,当事务提交时会先把数据的物理修改记录到该日志内,然后修改数据所在的页,如果页不在内存中,那么需要从磁盘将该数据页加载到内存中并对数据页内容进行修改,修改后的数据页被标记为脏页,MySQL会在合适的时机将内存中的脏页数据刷新到磁盘。redo log日志文件由两部分组成,分别是重做日志缓冲(redo log buffer)和重做日志文件(redo log file),事务提交后会把修改信息先写入到redo log再修改内存中的数据页,这样当事务提交过程中出现异常,就可以使用redo log进行数据恢复从而实现事务的持久性,这种先写日志再修改数据的处理方式就是大名鼎鼎的WAL(write ahead logging)
undo log:回滚日志,用于记录数据被修改前的信息,它主要有两个作用,提供回滚和MVCC多版本并发控制。与redo log记录物理日志不同,它记录的是逻辑日志,可以认为delete操作就会记录一条insert,update操作就会记录一条update前的数据,当执行rollback时,就会通过undo log记录的内容进行回滚。undo log在事务提交时并不会立即删除,因为有可能被MVCC使用,undo log采用段的方式进行管理和记录,存放在rollback segment,内部包含1024个段。
下面着重介绍一下MVCC。
MVCC,全称Multi Version Concurrency Control,即多版本并发控制,指维护一个数据的多个版本,使得数据的读写没有冲突。它的实现依赖于数据库记录中的三个隐藏字段、undo log中的记录和Read View。
一、 三个隐藏字段
在创建一个InnoDB引擎的数据表后,系统会在表中自动创建三个隐藏字段:
| 字段名 | 解释 |
|---|---|
| DB_TRX_ID | 最近修改事务的ID,记录插入这条记录或最后一次修改该记录的事务ID |
| DB_ROLL_PTR | 回滚指针,指向这条记录的上一个版本,需要配合undo log才能实现 |
| DB_ROW_ID | 隐藏主键,如果表结构中没有指定主键,将会生成该隐藏字段,如果表中已经有主键那么该隐藏字段就不会创建 |
如我们创建下面这个表结构:
CREATE TABLE `tb_nba` (
`id` int NOT NULL,
`name` varchar(40) DEFAULT NULL,
`team` varchar(40) DEFAULT NULL,
`score` int DEFAULT NULL,
`create_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
insert into tb_nba(`id`,`name`,`team`,`score`,`create_time`)
values(1, 'Jordan', 'Bulls', 32292, '2023-07-12 09:30:22'),
(2, "Kobe", "Laker", 33643, '2023-07-12 09:30:25'),
(3, "Rose", "Bulls", 12010, '2023-07-12 09:30:27'),
(4, "James", "Laker", 38648, '2023-07-12 09:30:34'),
(5, "Duncan", "Spurs", 26496, '2023-07-12 09:30:45'),
(6, "Wade", "Heat", 23165, '2023-07-12 09:30:55'),
(7, "Nash", "Sun", 17387, '2023-07-12 09:31:15'),
(8, "O'Neal", "Laker", 28596, '2023-07-12 09:32:48'),
(9, "Garnett", "Celtics", 26071, '2023-07-12 09:33:22'),
(10, "Pierce", "Celtics", 26397, '2023-07-12 09:34:11');
因为已经明确指定了主键ID,根据规则在创建隐藏字段时就不会创建DB_ROW_ID这个字段,
我们可以通过查看InnoDB文件的结构进行验证,mysql安装后的数据目录在*/var/lib/mysql/data*下,数据库名对应该目录下的一个文件夹名,进入对应的数据库目录后,表名对应一个以ibd扩展名结尾的文件,这里面就存储了InnoDB引擎的所有数据、索引以及表结构信息,通过命令ibd2sdi可以查看内容,执行命令后会返回相关信息,里面有一个columns的数组中就记录了表中的所有字段,刚刚创建的表字段内容如下(已经删除了其他信息):
[root@mylinux01 mydb]# ibd2sdi tb_nba.ibd
"columns": [
{
"name": "id",
......
},
{
"name": "name",
......
},
{
"name": "team",
......
},
{
"name": "score",
......
},
{
"name": "create_time",
......
},
{
"name": "DB_TRX_ID",
"type": 10,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 2,
"ordinal_position": 6,
"char_length": 6,
"numeric_precision": 0,
"numeric_scale": 0,
"numeric_scale_null": true,
"datetime_precision": 0,
"datetime_precision_null": 1,
"has_no_default": false,
"default_value_null": true,
"srs_id_null": true,
"srs_id": 0,
"default_value": "",
"default_value_utf8_null": true,
"default_value_utf8": "",
"default_option": "",
"update_option": "",
"comment": "",
"generation_expression": "",
"generation_expression_utf8": "",
"options": "",
"se_private_data": "table_id=1070;",
"engine_attribute": "",
"secondary_engine_attribute": "",
"column_key": 1,
"column_type_utf8": "",
"elements": [],
"collation_id": 63,
"is_explicit_collation": false
},
{
"name": "DB_ROLL_PTR",
"type": 9,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 2,
"ordinal_position": 7,
"char_length": 7,
"numeric_precision": 0,
"numeric_scale": 0,
"numeric_scale_null": true,
"datetime_precision": 0,
"datetime_precision_null": 1,
"has_no_default": false,
"default_value_null": true,
"srs_id_null": true,
"srs_id": 0,
"default_value": "",
"default_value_utf8_null": true,
"default_value_utf8": "",
"default_option": "",
"update_option": "",
"comment": "",
"generation_expression": "",
"generation_expression_utf8": "",
"options": "",
"se_private_data": "table_id=1070;",
"engine_attribute": "",
"secondary_engine_attribute": "",
"column_key": 1,
"column_type_utf8": "",
"elements": [],
"collation_id": 63,
"is_explicit_collation": false
}
]
二、Read View读视图
读视图就是数据的一个快照,保存着某个时刻的数据信息,根据事务的隔离级别不同,生成读视图的机制也不同,对于读已提交的隔离级别,每次查询都会生成一个读视图;而对于可重复读的隔离级别,只有事务内的第一个查询才会生成读视图,以后的每次查询都使用这个读视图。
在MySQL中需要区分两种读数据的概念:
- 当前读:读取记录都是最新版本,读取时还要保证其他并发事务不能修改当前记录,会对记录进行加锁,如:
使用共享锁实现当前读
select ... from ... lock in share mode;
使用排它锁实现当前读
select ... from ... for update;
增、删、改会自动加排它锁
insert 、delete 、update
- 快照读:简单的select语句就是快照读,读取的是数据可见版本,不加锁,非阻塞,有可能是历史数据。
Read Committed(读已提交):每次select查询都会剩菜一个快照读。
Repeatable Read(可重复读):开启事务后第一个select语句才是快照读的地方,以后读取的数据都是这个查询的快照。
Serializable(序列化):快照读会退化为当前读,因为每个SQL操作都是按顺序执行的。
下面针对快照读以及读视图的概念进行分析:
假设某一条记录发生了三次更新,对应3次事务的执行过程如下:
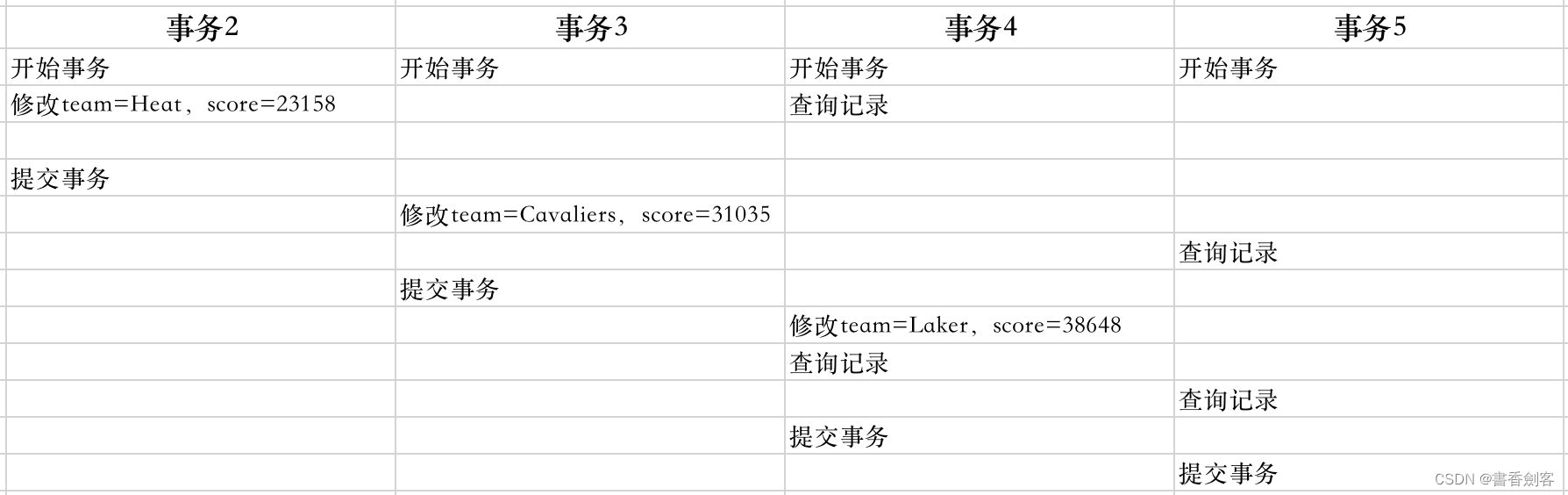
三个事务对表数据的修改就会在undo log中产生版本链,对应的内容如下:
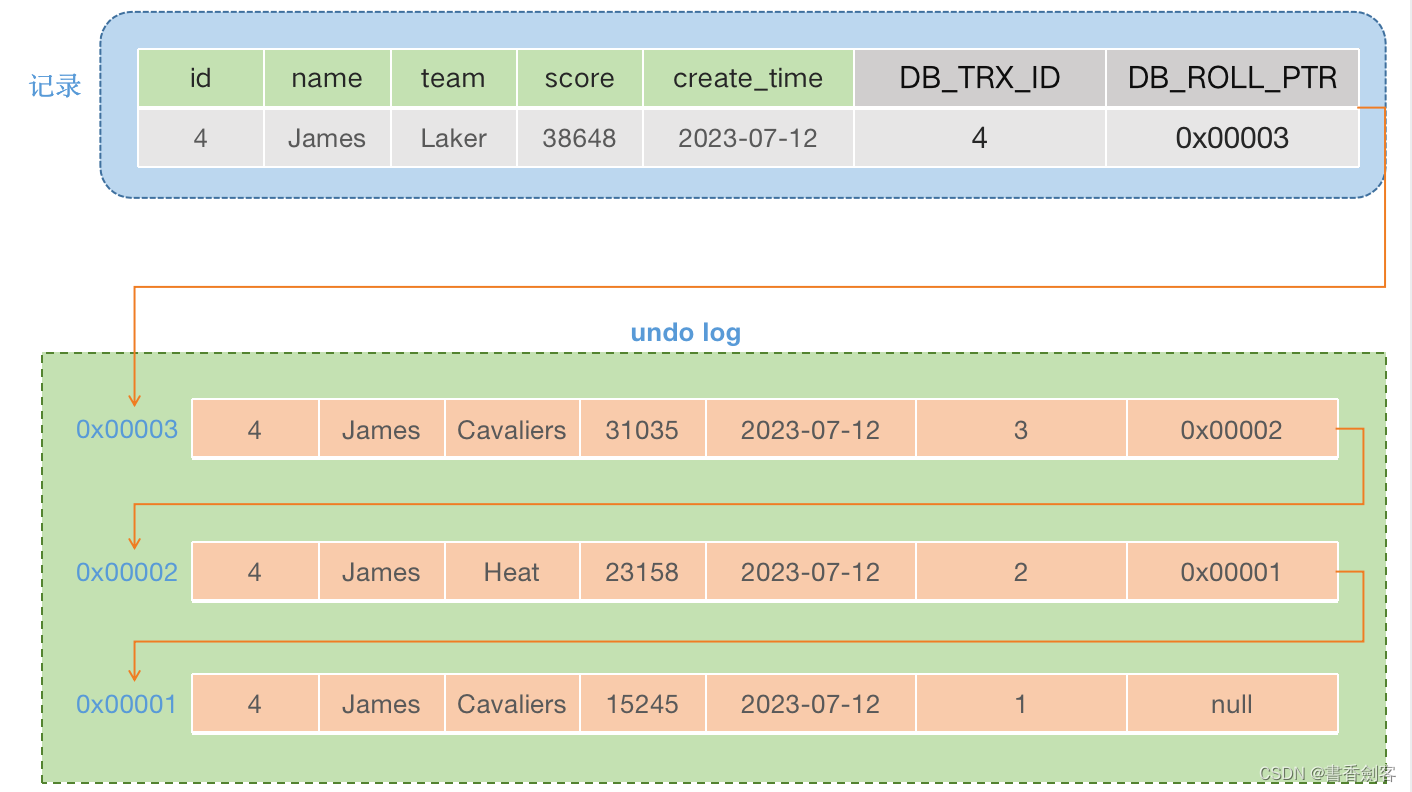
上面的版本链就是当执行多次update操作时产生的,每次执行update操作就会在undo log中产生一条修改前的数据记录,其中事务ID是递增的,回滚指针总是指向前一个事务记录的地址,当事务需要回滚时,就会在记录的回滚指针中找到需要回退的版本记录进行数据回滚。
前面说过要实现MVCC,需要三个隐藏字段、undo log日志和Read View读视图,这里的Read View是执行MVCC提取数据的依据,在Read View中记录并维护系统当前活跃的事务ID,它里面包含四个字段:
| 字段 | 解释 |
|---|---|
| m_ids | 当前活跃的事务ID集合,活跃事务是指还未提交或回滚的事务 |
| min_trx_id | 最小活跃事务ID |
| max_trx_id | 预分配事务ID,也是当前最大事务ID+1 |
| creator_trx_id | Read View创建者的事务ID |
| 针对以上四个字段,版本链数据访问规则是下面这样的: |
- trx_id == creator_trx_id 成立,可以访问该版本;说明数据是当前这个事务更改的。
- trx_id < min_trx_id 成立,可以访问该版本;说明数据已经提交了。
- trx_id > max_trx_id 成立,不可以访问该版本;说明该事务是在Read View生成后才开启的。
- min_trx_id <= trx_id <= max_trx_id 成立,如果trx_id不在m_ids中是可以访问该版本的;说明数据已经提交。
上面图片中事务5的两次查询发生时对应的Read View中字段值如下:
事务5第一次查询时产生Read View中各个字段值:
| 字段 | 字段值 |
|---|---|
| m_ids | [ 3, 4, 5 ] |
| min_trx_id | 3 |
| max_trx_id | 6 |
| creator_trx_id | 5 |
如果当前事务的隔离级别是可重复读,那么事务5第二次查询时就不会产生一个新的Read View;如果当前事务隔离级别是读已提交,那么事务5第二次查询时就会产生一个新的Read View,它里面各个字段值:
| 字段 | 字段值 |
|---|---|
| m_ids | [ 4, 5 ] |
| min_trx_id | 3 |
| max_trx_id | 6 |
| creator_trx_id | 5 |
下面使用第一次查询数据时产生的Read View数据来套用一下上面的4条规则:
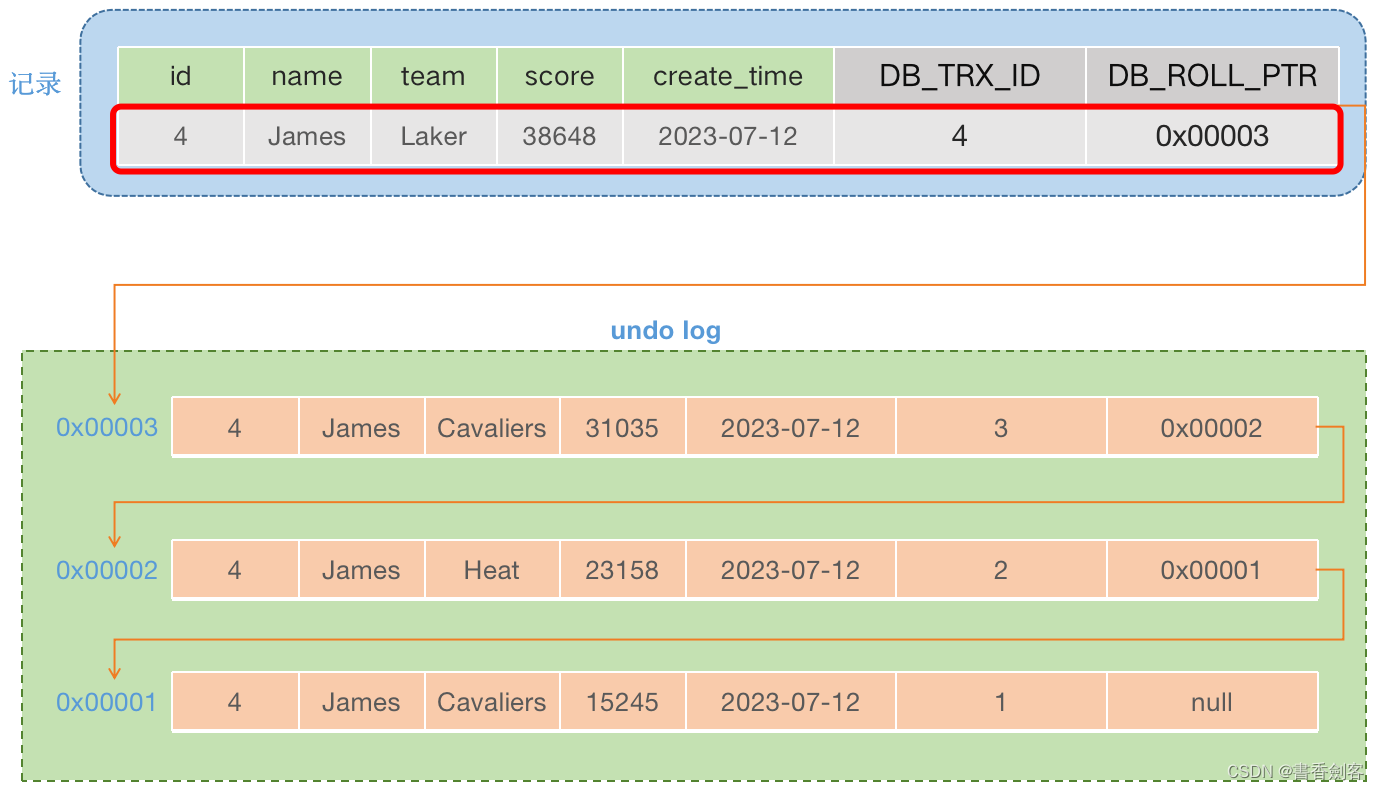 首先使用表中的记录套用比较,当前事务ID为4:
首先使用表中的记录套用比较,当前事务ID为4:
- trx_id = 4,creator_trx_id = 5 ,trx_id != creator_trx_id(期望 trx_id == creator_trx_id)表示第一个条件不成立。
- trx_id = 4,min_trx_id = 3 ,trx_id > min_trx_id(期望 trx_id < min_trx_id)表示第二个条件也不成立。
- trx_id = 4,max_trx_id = 6 ,trx_id < max_trx_id(期望trx_id > max_trx_id)表示第三个条件也不成立。
- min_trx_id = 3 ,trx_id = 4 ,max_trx_id = 6 ,m_ids = [ 3, 4, 5 ],min_trx_id < trx_id < max_trx_id 该条件成立,但是 trx_id 在 m_ids 集合中(期望 min_trx_id <= trx_id <= max_trx_id 且 trx_id not in m_ids)表示第四个条件也不成立。
综合上面的比较结果,表示事务5查看不到表中当前的记录,那么沿着事务链向下走,找到undo log中事务ID为3的这条数据:
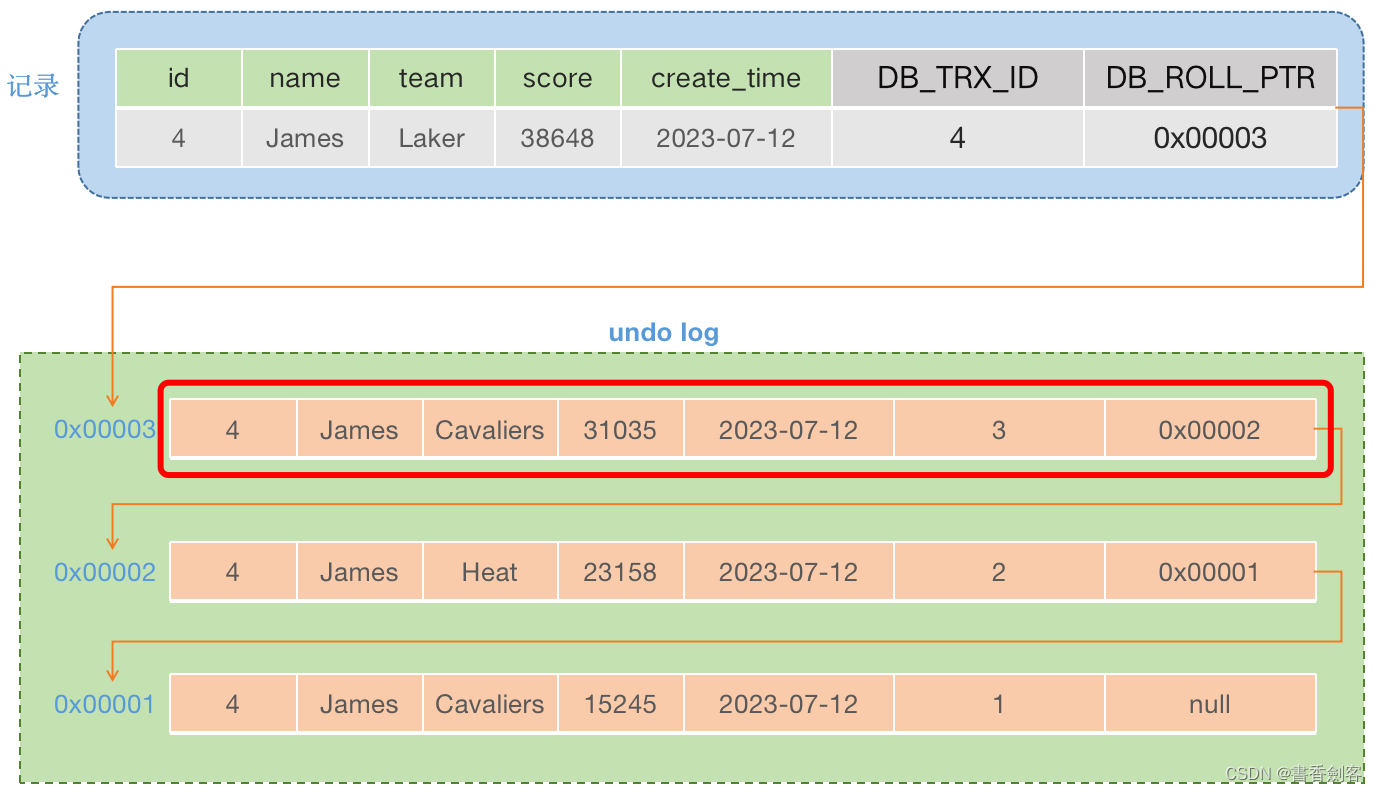

- trx_id = 3,creator_trx_id = 5 ,trx_id != creator_trx_id(期望 trx_id == creator_trx_id)表示第一个条件不成立。
- trx_id = 3,min_trx_id = 3 ,trx_id = min_trx_id(期望 trx_id < min_trx_id)表示第二个条件也不成立。
- trx_id = 3,max_trx_id = 6 ,trx_id < max_trx_id(期望trx_id > max_trx_id)表示第三个条件也不成立。
- min_trx_id = 3 ,trx_id = 3 ,max_trx_id = 6 ,m_ids = [ 3, 4, 5 ],min_trx_id <= trx_id < max_trx_id 该条件成立,但是 trx_id 在 m_ids 集合中(期望 min_trx_id <= trx_id <= max_trx_id 且 trx_id not in m_ids)表示第四个条件也不成立。
综合上面的比较结果,表示事务5查看不到undo log中第一条数据,那么沿着事务链向下走,找到undo log中事务ID为2的这条数据:
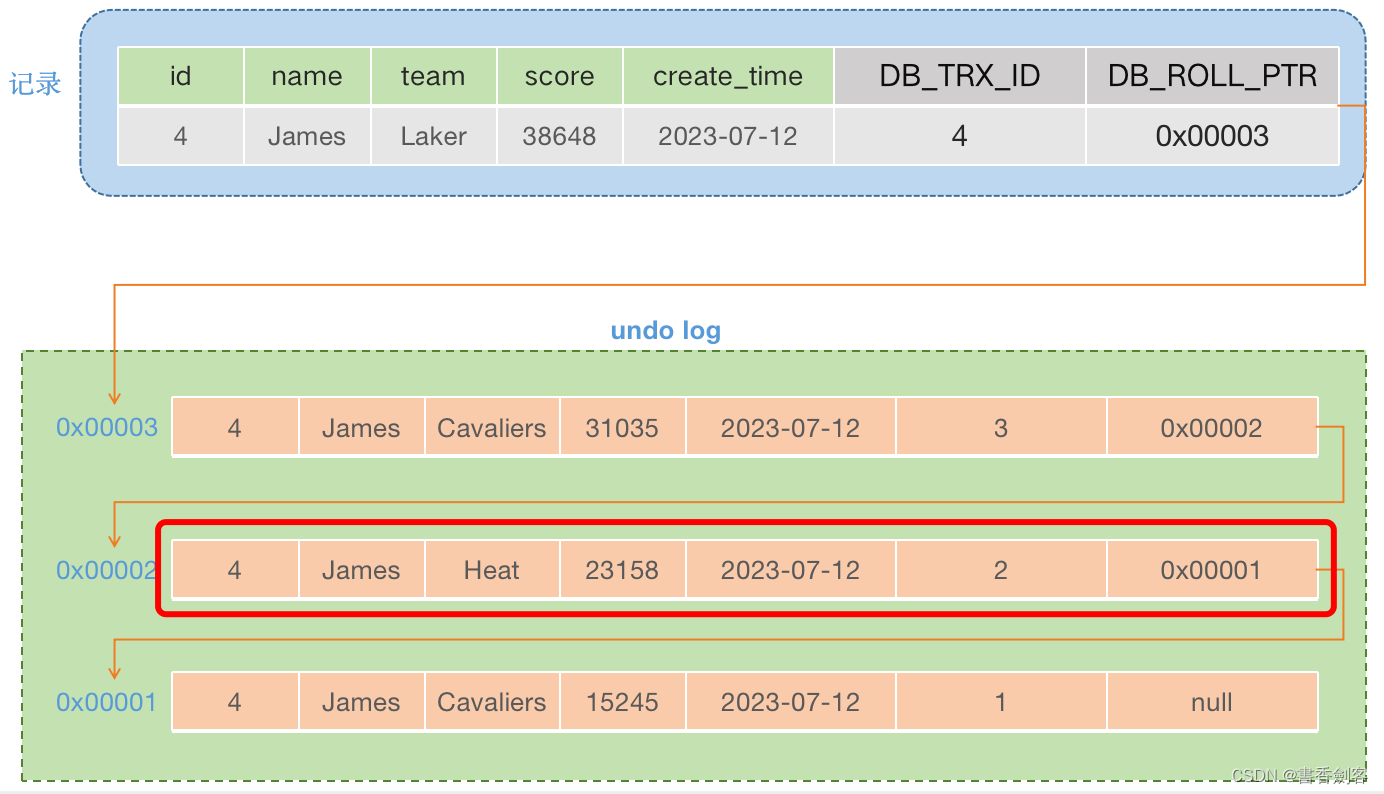
- trx_id = 2,creator_trx_id = 5 ,trx_id != creator_trx_id(期望 trx_id == creator_trx_id)表示第一个条件不成立。
- trx_id = 2,min_trx_id = 3 ,trx_id < min_trx_id(期望 trx_id < min_trx_id)表示第二个条件成立,可以访问数据。
这条记录刚好对应事务2提交后的数据。这样通过MVCC就实现了读已提交,对于事务未提交的数据在其他事务中是看不到的。而对于可重复读这种隔离级别,就是在一个事务中后面的多个查询语句复用第一次查询产生的读视图,通过同一个读视图获取相同版本的数据。
以上内容就是MySQL底层实现事务的ACID原理,总结如下:
redo log 这种先写日志的方式保证了事务的持久性;undo log 可回滚未提交的事务保证了事务的原子性;redo log + undo log 两个日志配合使用实现了事务的一致性;MVCC + Lock 两个配合使用实现了事务的隔离性。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/181865.html

