
在大数据领域,hadoop是必须学习和掌握的一项技术,hadoop里面包含了三个最主要的组件:HDFS用于数据存储、YARN用于资源的管理、MapReduce用于分布式计算。但是在当前的企业应用中,基本上都已经抛弃了MapReduce,而是基于Spark、Flink进行计算,但是这两个服务用于生产环境时都会选择在YARN上运行,并使用HDFS作为数据存储。
那么接下来就简单介绍一下Hadoop的安装:
首先进行机器资源分配,我是在自己虚拟机中进行安装测试的,使用VirtualBox构建了三台虚拟机:
| 主机名 | 主机IP | 资源划分 |
|---|---|---|
| mylinux01 | 192.168.0.112 | ResourceManager、NodeManager、NameNode、DataNode |
| mylinux02 | 192.168.0.113 | NodeManager、DataNode、SecondaryNameNode |
| mylinux03 | 192.168.0.114 | NodeManager、DataNode |
资源划分好了,接下来做主机名和IP映射,分别在每台机器上编辑hosts文件进行配置
[root@mylinux01 ~]# vim /etc/hosts
192.168.0.112 mylinux01
192.168.0.113 mylinux02
192.168.0.114 mylinux03
由于hadoop是集群化部署,为了方便集群管理,需要配置三台虚拟机免密登录,这样在安装完软件之后对于服务的启停管理会非常方便,只需要在主节点机器上设置免密能登录到其他两台机器就可以,生成密钥全程回车,然后将生成的密钥复制到三台机器上,注意要通过主机名进行设置。过程如下:
[root@mylinux01 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:JXPGZBNoPe6cuNxMhMwBkr90xgFmZlc4BxeoT98prf4 root@mylinux01
The key's randomart image is:
+---[RSA 2048]----+
| ..BooBOo |
| .* .O=+. |
| . *oB=. |
| + O*o |
| . *S* + . |
| . o B + |
| . = o |
| o + |
| ...E |
+----[SHA256]-----+
[root@mylinux01 ~]#
# 这里注意三台机器都要设置,本机也要
[root@mylinux01 ~]# ssh-copy-id mylinux01
[root@mylinux01 ~]# ssh-copy-id mylinux02
[root@mylinux01 ~]# ssh-copy-id mylinux03
hadoop运行需要jdk,安装jdk并设置环境变量:
[root@mylinux01 ~]# vim /etc/profile
export JAVA_HOME=/root/jdk1.8.0_161
export JRE_HOME=/root/jdk1.8.0_161/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/jre/lib/ext
[root@mylinux01 ~]# source /etc/profile
下载安装包并上传到虚拟机,我这里选择的是hadoop官网上最新的二进制包:hadoop-3.3.6.tar.gz,选择一个合适目录进行解压,然后进入解压后的目录修改相关配置文件。
- 编辑 hadoop-env.sh 文件:
[root@mylinux01 hadoop-3.3.6]# vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/root/jdk1.8.0_161
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 编辑 core-site.xml 文件:
[root@mylinux01 hadoop-3.3.6]# vim etc/hadoop/core-site.xml
<configuration>
<!-- 设置默认使用的文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mylinux01:9000</value>
</property>
<!-- 设置本地保存路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-3.3.6/data</value>
</property>
<!-- 设置hdfs web ui 身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive用户身份代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>65536</value>
</property>
</configuration>
- 编辑 hdfs-site.xml 文件:
[root@mylinux01 hadoop-3.3.6]# vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>mylinux02:9868</value>
</property>
</configuration>
- 编辑 mapred-site.xml 文件:
[root@mylinux01 hadoop-3.3.6]# vim etc/hadoop/mapred-site.xml
<configuration>
<!-- 设置MR程序默认运行模式:yarn集群模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>mylinux01:10020</value>
</property>
<!-- MR程序web服务地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>mylinux01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
- 编辑 yarn-site.xml 文件:
[root@mylinux01 hadoop-3.3.6]# vim etc/hadoop/yarn-site.xml
<configuration>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>mylinux01</value>
</property>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://mylinux01:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 配置yarn的web页面可以访问的地址 -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- 配置works信息:
[root@mylinux01 hadoop-3.3.6]# vim etc/hadoop/workers
mylinux01
mylinux02
mylinux03
- 配置hadoop环境变量:
[root@mylinux01 hadoop-3.3.6]# vim /etc/profile
export HADOOP_HOME=/root/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=/root/hadoop-3.3.6/etc/hadoop
[root@mylinux01 hadoop-3.3.6]# source /etc/profile
如上配置文件都修改成功了,需要将hadoop配置文件分发到其他两台机器,退到hadoop解压目录的上一层目录执行如下命令:
[root@mylinux01 ~]# scp -r hadoop-3.3.6/ root@mylinux02:$PWD
[root@mylinux01 ~]# scp -r hadoop-3.3.6/ root@mylinux03:$PWD
目前所有准备工作都已经完成了,在启动集群之前,先执行初始化命令,注意该命令只能在集群初始化一次,如果已有数据的集群使用该命令会导致数据丢失:
[root@mylinux01 ~]# hdfs namenode -format
如果看到如下命令表示初始化成功:
2023-07-10 16:05:01,385 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
2023-07-10 16:05:01,385 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2023-07-10 16:05:01,390 INFO util.GSet: Computing capacity for map NameNodeRetryCache
2023-07-10 16:05:01,391 INFO util.GSet: VM type = 64-bit
2023-07-10 16:05:01,391 INFO util.GSet: 0.029999999329447746% max memory 409 MB = 125.6 KB
2023-07-10 16:05:01,391 INFO util.GSet: capacity = 2^14 = 16384 entries
2023-07-10 16:05:01,461 INFO namenode.FSImage: Allocated new BlockPoolId: BP-931287864-127.0.0.1-1688976301437
2023-07-10 16:05:01,490 INFO common.Storage: Storage directory /root/hadoop-3.3.6/data/dfs/name has been successfully formatted.
2023-07-10 16:05:01,708 INFO namenode.FSImageFormatProtobuf: Saving image file /root/hadoop-3.3.6/data/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2023-07-10 16:05:02,000 INFO namenode.FSImageFormatProtobuf: Image file /root/hadoop-3.3.6/data/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 399 bytes saved in 0 seconds .
2023-07-10 16:05:02,031 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2023-07-10 16:05:02,050 INFO namenode.FSNamesystem: Stopping services started for active state
2023-07-10 16:05:02,050 INFO namenode.FSNamesystem: Stopping services started for standby state
2023-07-10 16:05:02,056 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2023-07-10 16:05:02,057 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/127.0.0.1
************************************************************/
命令执行完成后如果有以上内容输出,表示集群初始化成功了,接下来就可以启动集群了,hadoop为我们提供了分别启动服务的命令和一键启动的命令,所有命令在sbin目录下:
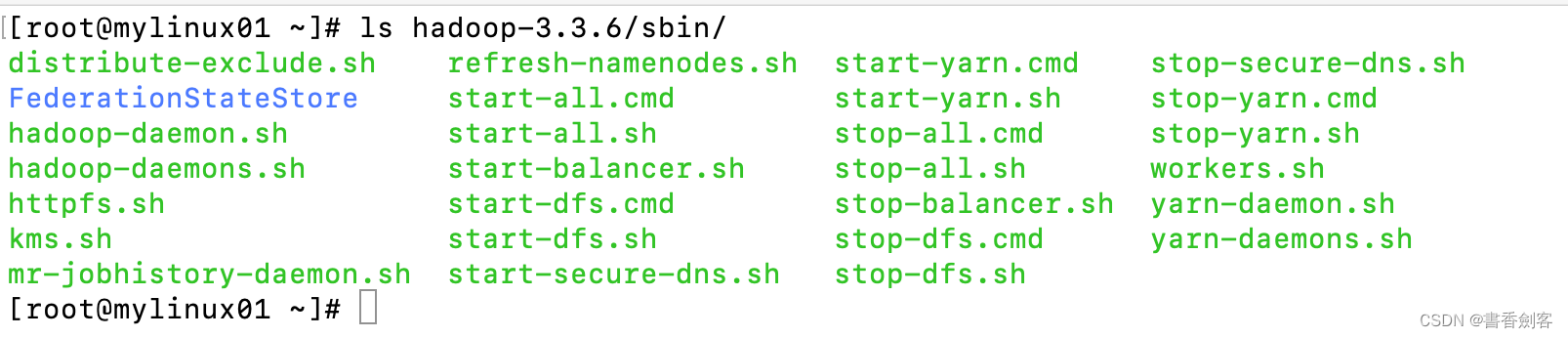
使用start-all.sh就可以同时启动HDFS和YARN:
开启全部服务
[root@mylinux01 ~]# start-all.sh
Starting namenodes on [mylinux01]
上一次登录:一 7月 10 16:25:53 CST 2023pts/0 上
Starting datanodes
上一次登录:一 7月 10 16:27:32 CST 2023pts/0 上
Starting secondary namenodes [mylinux02]
上一次登录:一 7月 10 16:27:35 CST 2023pts/0 上
Starting resourcemanager
上一次登录:一 7月 10 16:27:44 CST 2023pts/0 上
Starting nodemanagers
上一次登录:一 7月 10 16:27:53 CST 2023pts/0 上
[root@mylinux01 ~]#
关闭全部服务
[root@mylinux01 ~]# stop-all.sh
Stopping namenodes on [mylinux01]
上一次登录:一 7月 10 16:32:33 CST 2023pts/0 上
Stopping datanodes
上一次登录:一 7月 10 16:34:33 CST 2023pts/0 上
Stopping secondary namenodes [mylinux02]
上一次登录:一 7月 10 16:34:35 CST 2023pts/0 上
Stopping nodemanagers
上一次登录:一 7月 10 16:34:39 CST 2023pts/0 上
mylinux02: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
mylinux03: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
Stopping resourcemanager
上一次登录:一 7月 10 16:34:44 CST 2023pts/0 上
[root@mylinux01 ~]#
通过jps命令验证服务状态:
第一台机器
[root@mylinux01 ~]# jps
2032 ResourceManager
2705 NameNode
3381 NodeManager
3545 Jps
2847 DataNode
第二台机器
[root@mylinux02 ~]# jps
1761 Jps
1446 DataNode
1545 SecondaryNameNode
1628 NodeManager
第三台机器
[root@mylinux03 ~]# jps
1443 DataNode
1545 NodeManager
1678 Jps
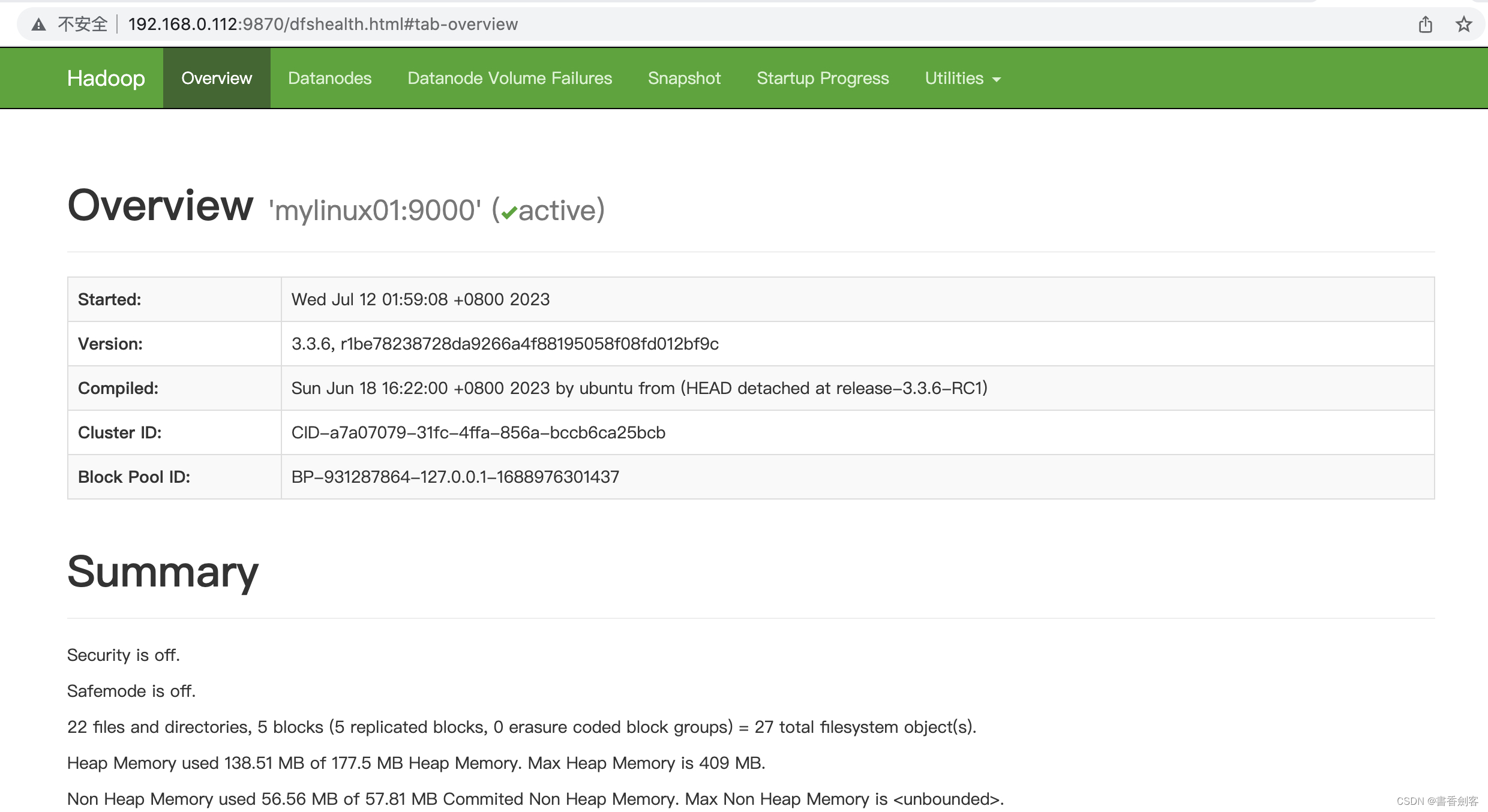
确实三个机器上面都已经启动集群成功,也可以通过页面查看信息,页面是在ResourceManager和NameNode所在的机器,可以通过主机名或IP地址方式访问,通过主机名访问要先配置好host。
查看hdfs的web页面在NameNode上: http://192.168.0.112:9870/dfshealth.html#tab-overview
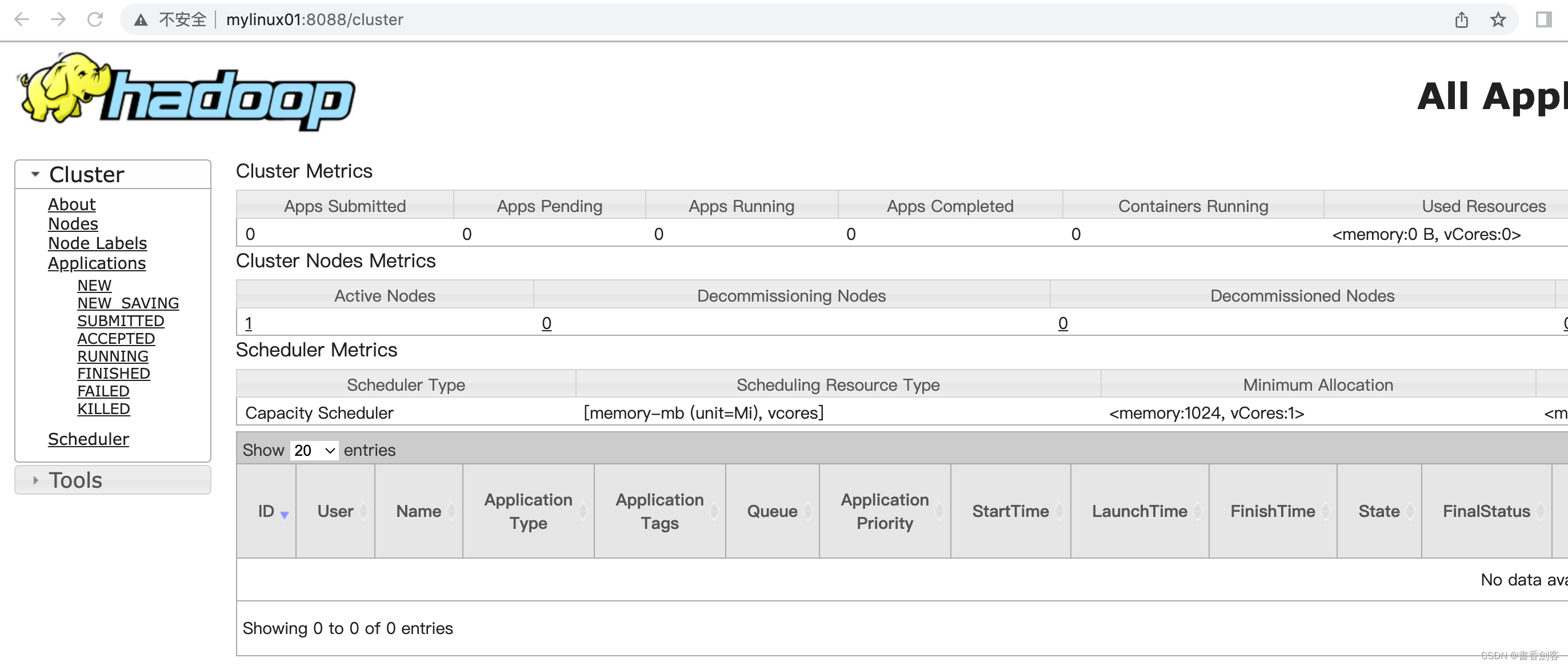
查看yarn的web页面在RescourceManager服务上: http://mylinux01:8088/cluster
至此,整个集群环境已经搭建成功了!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/181866.html

