
SpringCloud概述及微服务技术栈的使用
1、SpringCloud的简介
SpringCloud是一系列框架的有序集合。它利用SpringBoot的开发便利性巧妙地简化了分布式系统基础设置的开发,如服务发现与注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用SpringBoot的开发风格做到一键启动和部署。SpringCloud并没有重复制造轮子,它只是将目前各家公司开发比较成熟、经得起考研的服务框架组合起来,通过SpringBoot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者流下了一套简单易懂、易部署和易维护的分布式系统开发工具。
1.1、SpringCloud中的五大核心组件
Spring Cloud的本质是在SpringBoot的基础上,增加了一堆微服务相关的规范,并对应用上下文(ApplicationContext)进行功能增强,既然SpringCloud是规范,那么就需要去实现,目前Spring Cloud规范已有Spring官方,Spring Cloud Netflix,Spring Cloud Alibaba等是实现。 通过组件化的方式,Spring Cloud将这些实现整合到一起构成全家桶式的微服务技术栈。
SpringCloud Netflix组件
| 组件名称 | 作用 |
|---|---|
| Eureka | 服务注册中心 |
| Ribbon | 客户端负载均衡 |
| Feign | 声明式服务端调用(基于Ribbon,将调用方式RestTemplate,改为service接口调用) |
| Hystrix | 客户端容错报保护(熔断降级服务) |
| Zuul | API服务网关 |
Spring Cloud Alibaba组件
| 组件名称 | 作用 |
|---|---|
| Nacos | 服务注册中心 |
| Sentinel | 客户端容错保护 |
Spring Cloud原生及其他组件
| 组件 | 作用 |
|---|---|
| Consul(Eureka替代者) | 服务注册中心 |
| Config | 分布式配置中心 |
| Gateway(Zuul替代者) | API服务网关 |
| Sleuth | 分布式链路追踪 |
1.2、SpringCloud的架构
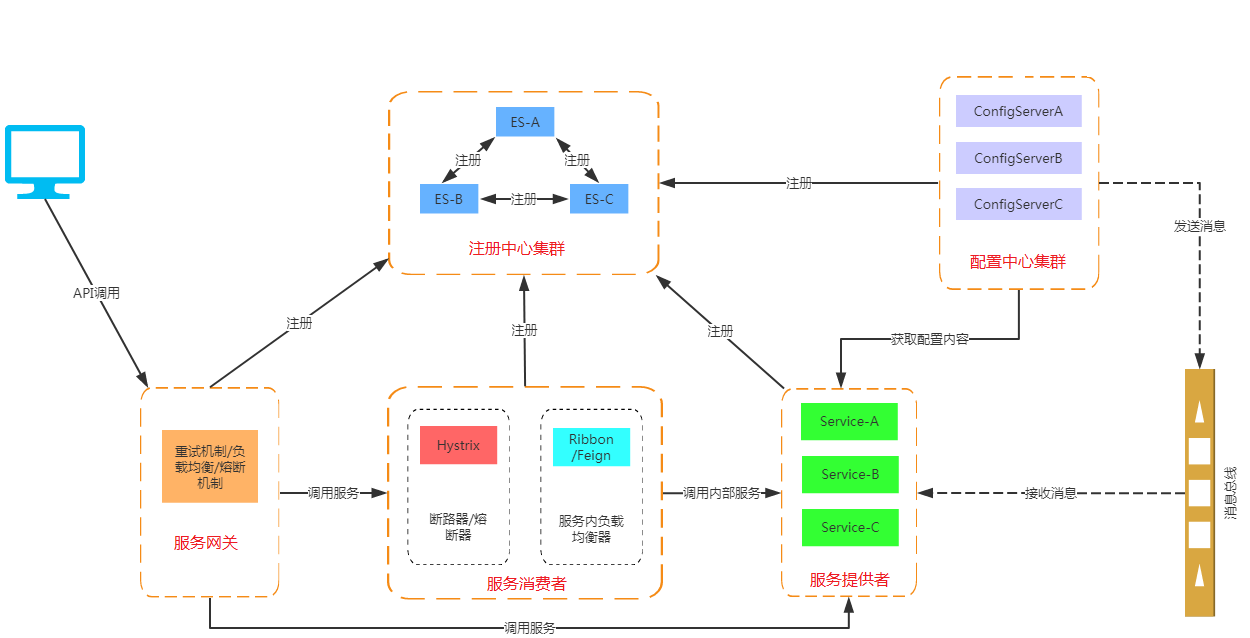
从上图可以看出SpringCloud各个组件的相互配合,合作支持了一套完整的微服务架构。
- 注册中心: 负责服务的注册与发现,很好的将个服务连接起来
- 断路器: 负责监控服务之间的调用情况,连续多次的失败,将进行熔断降级保护
- API网关: 负责转发所有对外的请求和服务
- 配置中心: 提供了统一的配置信息管理服务,可以实时的通知各个服务获取最新的配置信息
- 链路追踪技术: 可以将所有的数据记录下来,方便我们进行后续分析
- 各个组件又提供了功能完善的dashboard监控平台,可以当便的监控各组件的运行状况
1.3、微服务与微服务架构
微服务:
强调的是服务的大小,它关注的是某个一个点,是具体解决某一个问题/提供落地式对应服务的一个服务应用,狭义的看,可以看做是IDEA中的一个个微服务工程或者Moudle模块。IDEA工具里面使用Maven开发的一个个独立的Moudel,它具体是使用SpringBoot开发的一个小模块,专业的事情交给专业的模块来做,一个模块就做一件事情,强调的是一个个个体,每个个体完成一个具体的任务或者功能。
微服务架构:
一种新的架构形式,Martin Fowler于2014年提出。
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间相互协调互相配合,为用户提供最终价值,每个服务运行在其独立的进程中,服务与服务之间采用轻量级的通信机制(如HTTP协议)互相协作,每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境中,另外,应尽量避免统一的,集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具(如maven)对其进行统一构建。
1.4、微服务技术栈概括
| 微服务技术条目 | 技术支持 |
|---|---|
| 服务开发 | Spring、SpringBoot、SpringMVC |
| 服务配置与管理 | Netflix公司的Archaius、阿里的Diamond等 |
| 服务注册与发现 | Eureka、Consul、Zookeeper |
| 服务调用 | Rset、RPC、gRPC |
| 服务熔断器 | Hystrix、Envoy等 |
| 负载均衡 | Ribbon、Nginx等 |
| 服务接口调用(客户端调用服务的简化工具) | Feign等 |
| 消息队列 | RabbitMQ、ActiveMQ、Kafka等 |
| 服务配置中心管理 | SpringCLoudConfig、Chef等 |
| 服务路由(API网关) | Zuul等 |
| 服务监控 | Zabbix、Nagios、Metrics、Specatator等 |
| 全链路追踪 | Zipkin、Brave、Dapper等 |
| 数据流操作开发包 | SpringCloud Stream(封装与Redis、Rabbit、Kafka等发送接收消息) |
| 时间消息总栈 | SpringCloud Bus |
| 服务部署 | Docker、OpenStack、Kuberneters等 |
1.5、为什么选择SpringCloud作为微服务架构?
选型一依据
- 整体解决方案和框架成熟度
- 社区热度
- 可维护性
- 学习曲线
当前各大IT公司用的微服务架构有哪些?
- 阿里:dubbo+HFS
- 京东:JFS
- 新浪:Motan
- 当当网:DubboX
1.6、SpringCloud与SpringBoot的关系
- SpringBoot专注于快速方便的开发出当个个体微服务
- SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务,整合并管理起来,为各个微服务之间提供:配置管理、服务发现、断路器、路由、代理、事件总栈、决策竞选、分布式会话等等集成服务
- SpringBoot可以离开SpringCloud独立使用,开发项目,但是SpringCloud离不开SpringBoot,属于依赖关系
1.7、Dubbo和SpringCloud技术选型
1、分布式+服务治理Dubbo
- 目前成熟的互联网架构,应用服务化拆分+消息中间件
2、Dubbo与SpringCloud对比
可以看一下社区活跃度:Dubbo和SpringCloud
| Dubbo | SpringCloud | |
|---|---|---|
| 服务注册中心 | Zookeeper | Spring Cloud Netflix Eureka |
| 服务调用方式 | RPC | REST API |
| 服务监控 | Dubbo-monitor | SpringBoot Admin |
| 断路器 | 不完善 | SpringCloud Netflix Hystrix |
| 服务网关 | 无 | Spring Cloud Netflix Zuul |
| 分布式配置 | 无 | Spring Cloud Config |
| 服务追踪 | 无 | Spring Cloud Sleuth |
| 消息总栈 | 无 | Spring Cloud Bus |
| 数据流 | 无 | Spring Cloud Stream |
| 批量任务 | 无 | Spring Cloud Task |
两者最大的区别在于通信方式:
SpringCloud抛弃了Dubbo的RPC通信,采用的是基于轻量级HTTP协议的REST API方式。
严格来说,这两种方式各有优劣,在性能上RPC要优于REST,但是在灵活度上REST相比RPC是更灵活,服务提供方和调用方只需要一致契约,不存在代码级别的强依赖,这个优点在当下强调快速演化的微服务环境下,显得更加合适。
二者解决的问题域不同:Dubbo的定位是一款RPC框架,而SpringCloud的目标是微服务架构下的一站式解决方案。
1.8、SpringCloud可以做什么?
- Distributed/Versioned configuration 分布式/版本控制系统
- Service registration and discovery 服务注册与发现
- Routing 路由
- Service-to-service calls 服务到服务之间的调用
- Load balancing 负载均衡策略
- Circuit Breakers 断路器
- Distributed messaging 分布式消息管理
1.9、SpringCloud官网下载
SpringCloud官网
SpringCloud没有采用数字编号的方式命名版本号,而是采用了伦敦地铁站的名称,同时根据字母表的顺序来对应版本时间顺序:
- 最早的Realse版本:Angel,
- 第二个Realse版本:Brixton,
- 然后依次是Camden、Dalston、Edgware,
- 目前最新的是Hoxton SR4 CURRENT GA通用稳定版。
1.10、SpringCloud版本选择
大版本说明
| SpringBoot | SpringCloud | 关系 |
|---|---|---|
| 1.2X | Angel版本 | 兼容SpringBoot1.2X |
| 1.3X | Brixton版本(布里克斯顿) | 兼容SpringBoot1.3X,也兼容SpringBoot1.4X |
| 1.4X | Camden版本(卡姆登) | 兼容SpringBoot1.4X,也兼容SpringBoot1.5X |
| 1.5X | Dalston版本(多尔斯顿) | 兼容SpringBoot1.5X,不兼容SpringBoot2.0X |
| 1.5X | Edgware版本(埃奇韦尔) | 兼容SpringBoot1.5X,不兼容SpringBoot2.0X |
| 2.0X | Finchley版本(芬奇利) | 不兼容SpringBoot1.5X ,兼容SpringBoot2.0X |
| 2.1X | Greenwich版本(格林威治) |
实际开发版本关系
| spring-boot-starter-parent | spring-cloud-dependencies | ||
|---|---|---|---|
| 版本号 | 发布日期 | 版本号 | 发布日期 |
| 1.5.2.RELEASE | 2017-03 | Dalston.RC1 | 2017-x |
| 1.5.9.RELEASE | 2017-11 | Edgware.RELEASE | 2017-11 |
| 1.5.16.RELEASE | 2018-04 | Edgware.SR5 | 2018-10 |
| 1.5.20.RELEASE | 2018-09 | Edgware.SR5 | 2018-10 |
| 2.0.2.RELEASE | 2018-05 | Fomchiey.BULD-SNAPSHOT | 2018-x |
| 2.0.6.RELEASE | 2018-10 | Fomchiey-SR2 | 2018-10 |
| 2.1.4.RELEASE | 2019-04 | Greenwich.SR1 | 2019-03 |
2、基于Eureka注册中心的案例搭建与分析
SpringCloud系列(一)、服务注册中心Eureka基础【详细教程】
3、Eureka的替换方案Consul
Eureka的闭源影响
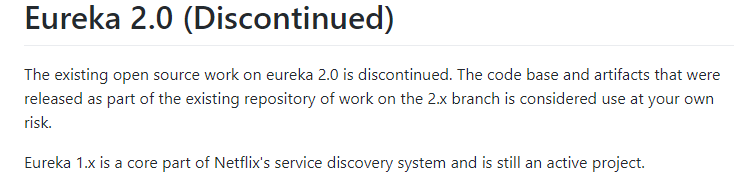
在Euraka的GitHub上,宣布Eureka 2.x闭源。近这意味着如果开发者继续使用作为 2.x 分支上现有工作repo 一部分发布的代码库和工件,风险则将自负。
Eureka的替换方案如下:
- ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
- Consul是近几年比较流行的服务发现工具,工作中用到,简单了解一下。consul的三个主要应用场景:服务发现、服务隔离、服务配置。
- Nacos是阿里巴巴推出来的一个新开源项目,这是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。Nacos 致力于帮助您发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。 Nacos 是构建以“服务”为中心的现代应用架构 (例如微服务范式、云原生范式) 的服务基础设施。
3.1、Consul概述

Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。与其它分布式服务注册与发现的方案,Consul 的方案更“一站式”,
- 内置了服务注册与发现框 架
- 分布一致性协议实现
- 健康检查
- Key/Value 存储
- 多数据中心方案
不再需要依赖其它工具(比如 ZooKeeper 等),使用起来也较 为简单。Consul 使用 Go 语言编写,因此具有天然可移植性(支持Linux、windows和Mac OS X);安装包仅包含一个可执行文件,方便部署,与 Docker 等轻量级容器可无缝配合。
3.2、Consul的优势
- 使用Raft算法来保证一致性,比复杂的Paxoa算法更直接,相比较而言,Zookeeper采用的是Paxos,而etcd使用的则是Raft
- 支持多数据中心,内外网的服务采用不同的端口监听。多数据中心集群可以避免单数据中心的单点故障,而其部署则需要考虑网络延迟,分片等情况,zookeeper和etcd均不提供多数据中心功能的支持
- 支持健康检测,etcd不提供此功能
- 支持HTTP和DNS协议接口。 zookeeper的继承较为复杂,etcd只支持http协议
- 官方提供web管理界面,etcd无此功能
- 综合比较,Consul作为服务注册和配置管理,比较值得关注和研究
Consul的特征:
- 服务发现
- 多数据中心
- key/value存储
- 健康检测
3.3、Consul与Eureka的区别
Consul具有强一致性(CP):
- 服务注册相比Eureka会稍慢一些,因为Consul的Raft协议要求必须过半数的节点都写入成功才认为注册成功
- Leader挂点后,重新选举期间整个Consul不可用,保证了强一致性,但牺牲了可用性
Eureka保证高可用性和最终一致性(AP):
- 服务注册相对要快,因为不需要等注册信息replicate到其他节点上,也不保证注册信息是否replicate成功
- 当数据出现不一致时,虽然A、B上的注册信息不完全相同,但每个Eureka节点依然能够正常对外提供服务,这会出现查询服务信息时,如果请求A查不到,但请求B可以查到(但内容不一定一致),如此保证了高可用性,但是牺牲了一致性
开发语言和使用:
- Eureka就是个servlet程序,跑在servlet容器中
- Consul则是go编写而成,安装启动即可
3.4、Consul的下载与安装
访问 Consul 官网下载 Consul 的最新版本,Consul 需要单独安装,我这里是consul1.5x。根据不同的系统类型选择不同的安装包,从下图也可以看出 Consul 支持所有主流系统。
在Linux虚拟机在中安装Consul服务:
## 从官网下载最新版本的Consul服务
wget https://releases.hashicorp.com/consul/1.5.3/consul_1.5.3_linux_amd64.zip
##使用unzip命令解压
unzip consul_1.5.3_linux_amd64.zip
##将解压好的consul可执行命令拷贝到/usr/local/bin目录下
cp consul /usr/local/bin
##测试一下
consul
启动Consul服务:
##已开发者模式快速启动,-client指定客户端可以访问的ip地址
[root@node01 ~]# consul agent -dev -client=0.0.0.0
==> Starting Consul agent...
Version: 'v1.5.3'
Node ID: '49ed9aa0-380b-3772-a0b6-b0c6ad561dc5'
Node name: 'node01'
Datacenter: 'dc1' (Segment: '<all>')
Server: true (Bootstrap: false)
Client Addr: [127.0.0.1] (HTTP: 8500, HTTPS: -1, gRPC: 8502, DNS: 8600)
Cluster Addr: 127.0.0.1 (LAN: 8301, WAN: 8302)
Encrypt: Gossip: false, TLS-Outgoing: false, TLS-Incoming: false,
Auto-Encrypt-TLS: false
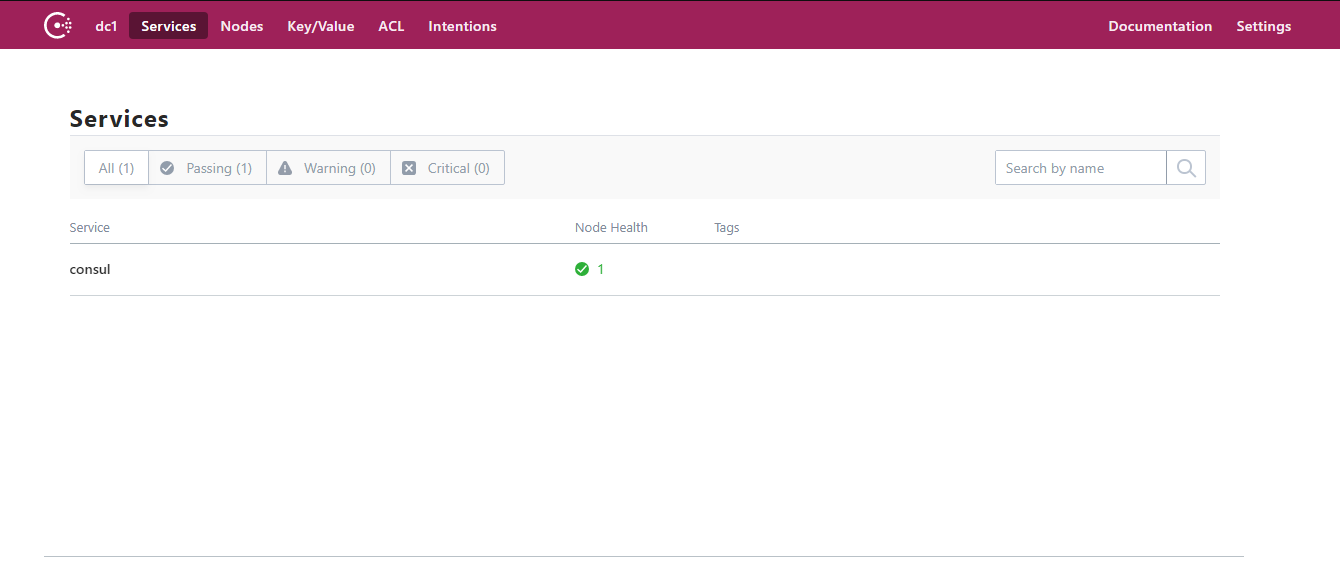
启动成功之后访问: http://IP地址:8500 ,可以看到 Consul 的管理界面:
我们此处暂时先使用windows下的版本启动Consul服务:从官网下载windows版本的zip,解压后免安装:
输入启动Consu命令:
#-client=0.0.0.0 是为了开放所有ip访问
consul agent -dev -client=0.0.0.0
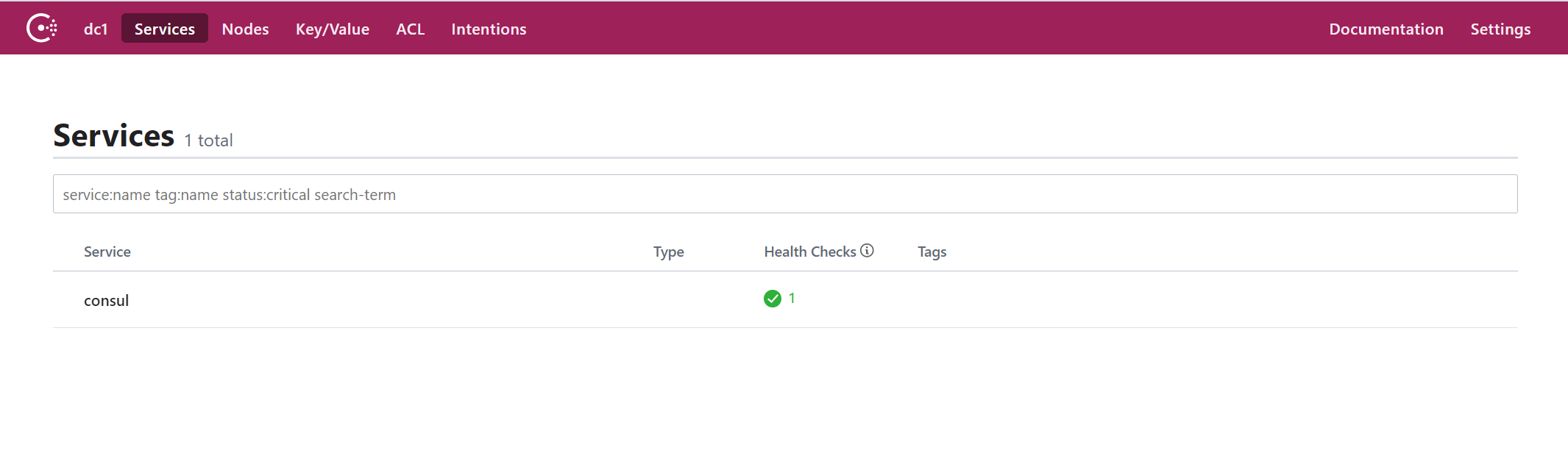
启动之后,访问地址栏:localhost:8500
3.5、Consul的K/V存储
可以参照Consul提供的KV存储的 API完成基于Consul的数据存储
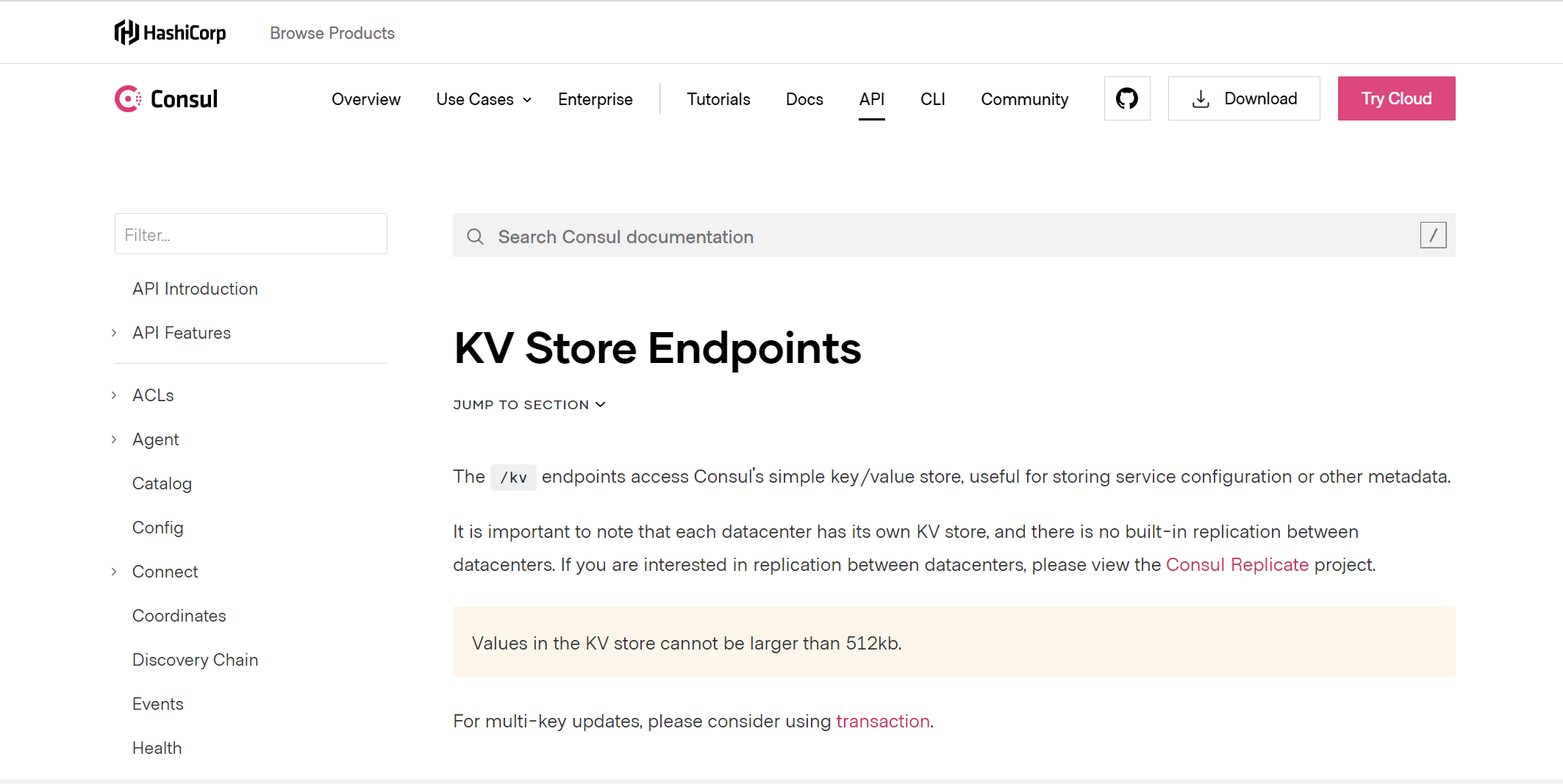
| 含义 | 请求路径 | 请求方式 |
|---|---|---|
| 查看key | v1/kv/:key | GET |
| 保存或更新 | v1/kv/:key | PUT |
| 删除 | v1/kv/:key | DELETE |
- key值中可以带/, 可以看做是不同的目录结构。
- value的值经过了base64_encode加密,获取到数据后base64_decode解密才能获取到原始值。数据不能大于512Kb
- 不同数据中心的kv存储系统是独立的,使用dc=?参数指定。
3.6、基于Consul的服务注册案例
工程配置仍然和Eureka保持一致(可做参考):
SpringCloud系列(一)、服务注册中心Eureka基础【详细教程】
ebuy-consul-parent(父模块)
---ebuy-consul-product(商品微服务)
---ebuy-consul-order(订单微服务)
修改商品和订单微服务模块的pom文件:
<!--SpringCloud提供的基于Consul的服务发现-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
</dependency>
<!--actuator用于心跳检查-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
配置服务注册
ebuy-consul-product的application.yml
server:
port: 9011 #端口号
spring:
application:
name: ebuy-product #商品模块服务名称
datasource:
username: root #数据库用户名
password: root #数据库密码
driver-class-name: com.mysql.jdbc.Driver #mysql加载驱动
url: jdbc:mysql://localhost:3306/ebuy?useUnicode=true&characterEncoding=utf8
cloud:
consul:
host: 127.0.0.1 #指定consul服务地址
port: 8500 #指定consul服务端口号
discovery:
register: true #是否注册
instance-id: ${spring.application.name}-1 #指定实例id名
server-name: ${spring.application.name} #服务实例名称
port: ${server.port} #服务实例端口号
health-check-path: /actuator/health #健康检测路径
health-check-interval: 15s #指定健康检测时间间隔
prefer-ip-address: true #开启ip地址注册
ip-address: ${spring.cloud.client.ip-address} #实例请求ip
#mybatis相关配置
mybatis:
type-aliases-package: com.ebuy.product.pojo #mybatis简化pojo实体类别名
mapper-locations: com/ebuy/product/mapper/*.xml #mapper映射文件路径
#打印日志
logging:
level:
com.ebuy: DEBUG #日志级别
ebuy-consul-order的application.yml
server:
port: 9013 #端口号
address: 127.0.0.1
tomcat:
max-threads: 10 #最大线程数(默认为200台)
spring:
application:
name: ebuy-order #服务名
cloud:
consul:
host: 127.0.0.1 #指定consul服务地址
port: 8500 #指定consul服务端口号
discovery:
register: true #是否注册
instance-id: ${spring.application.name}-1 #指定实例id名
server-name: ${spring.application.name} #服务实例名称
port: ${server.port} #服务实例端口号
health-check-path: /actuator/health #健康检测路径
health-check-interval: 15s #指定健康检测时间间隔
prefer-ip-address: true #开启ip地址注册
ip-address: ${spring.cloud.client.ip-address} #实例请求ip
health-check-url: http://${server.address}:${server.port}/**/health
health-check-critical-timeout: 30s #check失败后,多少秒剔除该服务
#打印日志
logging:
level:
com.ebuy: DEBUG
其中 spring.cloud.consul 中添加consul的相关配置:
- host:表示Consul的Server的请求地址
- port:表示Consul的Server的端口
- discovery:服务注册与发现的相关配置
- instance-id : 实例的唯一id(推荐必填),spring cloud官网文档的推荐,为了保证生成一个唯一的id ,也可以换成
${spring.application.name}:${spring.cloud.client.ipAddress} - prefer-ip-address:开启ip地址注册
- ip-address:当前微服务的请求ip
- instance-id : 实例的唯一id(推荐必填),spring cloud官网文档的推荐,为了保证生成一个唯一的id ,也可以换成
启动两个微服务:查看Consul监控中心
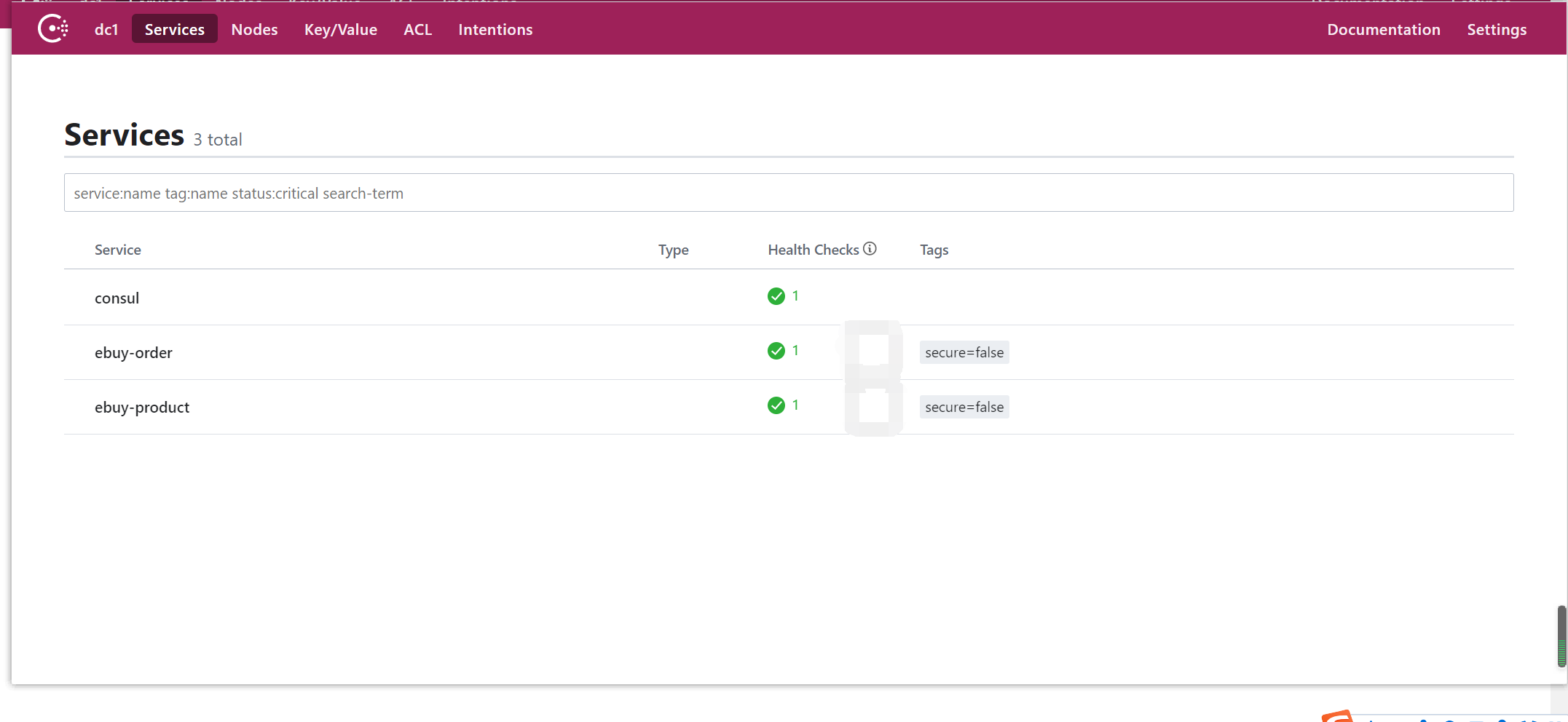
基于微服务的发现:
由于SpringCloud对Consul进行了封装。对于在消费者端获取服务提供者信息和Eureka是一致的。同样使用 DiscoveryClient完成调用获取微服务实例信息,其余用法基本都和Eureka保持一致。
4、Ribbon:基于客户端服务调用(负载均衡)
经过以上的学习,已经实现了服务的注册和服务发现。当启动某个服务的时候,可以通过HTTP的形式将信息注册到注册中心,并且可以通过SpringCloud提供的工具获取注册中心的服务列表。但是服务之间的调用还存在很多的问题,如何更加方便的调用微服务,多个微服务的提供者如何选择,如何负载均衡等。
4.1、什么是Ribbon?
Ribbon是Netflix发布的一个负载均衡器,有助于控制HTTP和TCP客户端行为,在SpringCloud中,Eureka一般配合Ribbon进行使用,Ribbon提供了客户端负载均衡的功能,Ribbon利用从Eureka或者Consul中读取到的服务信息,在调用服务节点提供的服务时,会合理的进行负载,默认为轮询策略。
在SpringCloud中可以将注册信息和Ribbon配合使用,Ribbon自动的从注册中心获取服务提供者的列表信息,并基于内置的负载均衡算法,请求服务。
4.2、Ribbon的主要作用
客户端服务调用:
- 基于Ribbon实现服务调用,是通过拉取到的所有服务列表组成(服务名:请求路径)的一种映射关系,借助于RestTemplate最终实现调用。
负载均衡:
- 当有多个服务提供者时,Ribbon可以根据负载均衡的算法自动的选择需要调用的服务地址。
4.3、Ribbon的关键组件
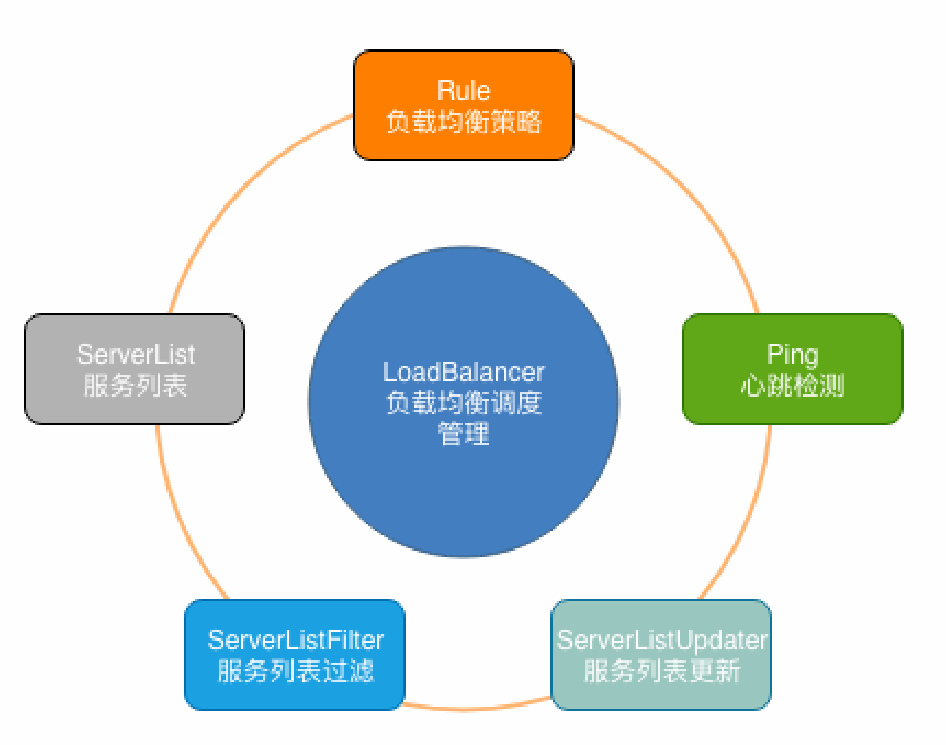
- ServerList:可以响应客户端的特定服务的服务器列表。
- ServerListFilter:可以动态获得的具有所需特征的候选服务器列表的过滤器。
- ServerListUpdater:用于执行动态服务器列表更新。
- Rule:负载均衡策略,用于确定从服务器列表返回哪个服务器。
- Ping:客户端用于快速检查服务器当时是否处于活动状态。
- LoadBalancer:负载均衡器,负责负载均衡调度的管理。
4.4、工程改造
上述讲解了Consul替代Eureka,此处我们暂时先将注册中心改为Eureka注册,并配置两台注册中心集群:
application.yml(将8000注册到9000),互相注册,application.yml(将9000注册到8000)即可
server:
port: 8000 #端口号
spring:
application:
name: eureka-server #eurekaServer服务名
eureka:
#instance:
#hostname: 127.0.0.1 #服务器ip地址
client:
register-with-eureka: true #是否将自己注册到注册中心
#fetch-registry: false #是否从注册中心获取服务列表
serviceUrl: #配置暴露给Eureka Client的请求地址
defaultZone: http://127.0.0.1:9000/eureka/
server:
enable-self-preservation: false #关闭自我保护机制(一旦发现有网络不稳定的服务,直接剔除)
eviction-interval-timer-in-ms: 4000 #剔除时间间隔,单位:毫秒
#wait-time-in-ms-when-sync-empty: 5
服务提供者和消费者:修改application.yml文件中注册中心配置:
server:
port: 90XX #端口号
address: 127.0.0.1
tomcat:
max-threads: 10 #最大线程数(默认为200台)
spring:
application:
name: ebuy-XXXX #服务名
# cloud:
# consul:
# host: 127.0.0.1 #指定consul服务地址
# port: 8500 #指定consul服务端口号
# discovery:
# register: true #是否注册
# instance-id: ${spring.application.name}-1 #指定实例id名
# server-name: ${spring.application.name} #服务实例名称
# port: ${server.port} #服务实例端口号
# health-check-path: /actuator/health #健康检测路径
# health-check-interval: 15s #指定健康检测时间间隔
# prefer-ip-address: true #开启ip地址注册
# ip-address: ${spring.cloud.client.ip-address} #实例请求ip
# health-check-url: http://${server.address}:${server.port}/**/health
# health-check-critical-timeout: 30s #check失败后,多少秒剔除该服务
#使用eureka注册中心
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8000/eureka/,http://127.0.0.1:9000/eureka/
instance:
instance-id: ${spring.cloud.client.ip-address}:${server.port}
prefer-ip-address: true #使用ip地址注册(在注册中心显示名字以ip地址显示)
lease-expiration-duration-in-seconds: 10 #eureka client发送心跳给eureka server服务端后,续约到期时间(默认为90秒)
lease-renewal-interval-in-seconds: 5 #发送心跳续约时间间隔
#打印日志
logging:
level:
com.ebuy: DEBUG
4.5、服务调用Ribbon高级,什么是负载均衡?
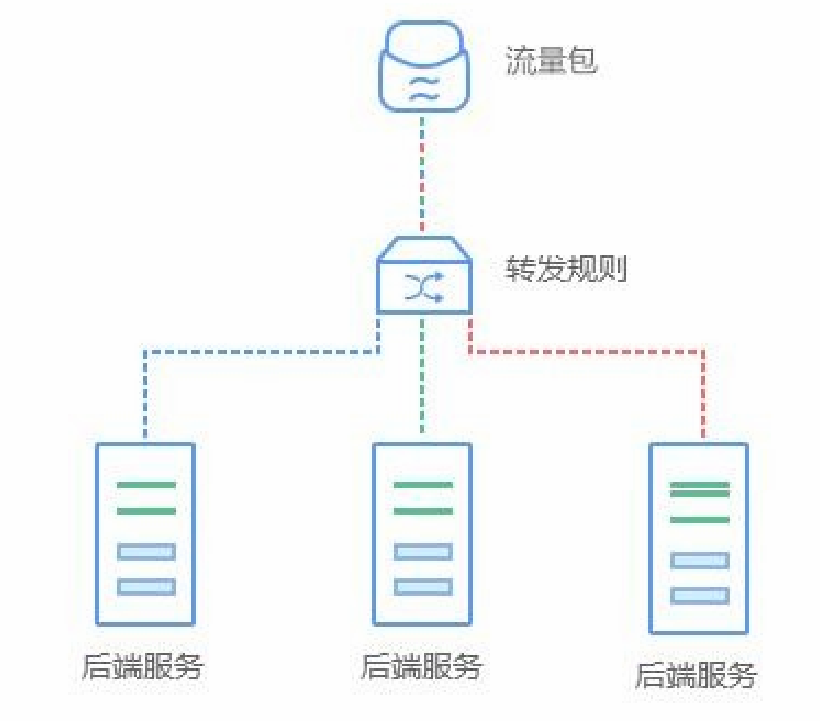
在搭建网站时,如果节点的web服务性能和可靠性都无法达到要求,或者是在使用外网服务时,经常担心被人攻击,一不小心就会有打开外网端口的情况,通常这个时候加入负载均衡就能有效的解决服务访问问题。
负载均衡是一种基础的网络服务,其原理是通过运行在前面的负载均衡服务,按照指定的负载均衡算法,将流量分配到后端服务集群上,从而为系统提供并行扩展的能力。
负载均衡的应用场景包括流量包、转发规则以及后端服务,由于服务有内外网个例,健康检查等功能,能够有效提高系统的安全性和可靠性。
4.6、客户端负载均衡和服务端负载均衡
客户端负载均衡:
- 客户端从注册中心会获取到一个服务提供者的服务器地址列表,在发送请求前通过负载均衡算法选择一个服务器,然后进行访问,这是客户端负载均衡,即在客户端就进行负载均衡算法分配。
服务端负载均衡:
- 先发送请求到负载均衡服务器或软件,然后通过负载均衡算法,在多个服务器之间选择一个进行访问;即在服务器端再进行服务在均衡算法分配
4.7、基于Ribbon实现负载均衡
首先要搭载多态服务器,上述已经搭建好Eureka注册中心的集群,然后再搭建两台ebuy-product和一台ebuy-order即可,如下:
1、服务提供者ebuy-product
服务提供者:修改ebuy-product模块下的ProductController#findById()方法:
@RestController
@RequestMapping("/product")
public class ProductController {
/**
* 回去客户端ip地址
*/
@Value("${spring.cloud.client.ip-address}")
private String ip;
/**
* 获取客户端的端口号
*/
@Value("${server.port}")
private String port;
@Autowired
private EasybuyProductService productService;
@RequestMapping(value = "/{id}",method = RequestMethod.GET)
public EasybuyProduct findById(@PathVariable Long id) {
EasybuyProduct product = productService.selectByPrimaryKey(id);
product.setEpDescription("调用ebuy-product服务,ip:"+ip+",服务提供者端口:"+port);
return product;
}
}
ebuy-product服务提供者启动两台:9011,9012
ebuy-order服务消费者启动一台:9013
2、服务消费者ebuy-order
然后在ebuy-order的EbuyOrderApplication启动类处,创建RestTemplate方法,并添加@LoadBalanced注解实现与Ribbon搭配的负载均衡:
@SpringBootApplication
@EnableEurekaClient //开启Eureka客户端服务注册
@EnableDiscoveryClient //开启服务发现
public class EbuyOrderApplication {
/**
* @Bean 配置RestTemplate交给spring管理
* @LoadBalanced 实现负载均衡(Ribbon原理)
* @return
*/
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(EbuyOrderApplication.class, args);
}
}
在ebuy-order服务模块的OrderController下添加下单方法:
@Autowired
RestTemplate restTemplate;
@RequestMapping(value = "/buy/{id}",method = RequestMethod.GET)
public EasybuyProduct findById(@PathVariable Long id) {
EasybuyProduct easybuyProduct=new EasybuyProduct();
//easybuyProduct=restTemplate.getForObject("http://127.0.0.1:9011/product/"+id,EasybuyProduct.class);
/**
* Ribbon负载均衡策略
* 在RestTemplate注册Bean实例处要使用注解@LoadBalanced注解,
* 此时restTemplate调用产品Restful API接口时,要调用商品微服务名称(才能实现负载均衡,默认为轮询机制)
*/
easybuyProduct=restTemplate.getForObject("http://ebuy-product/product/"+id,EasybuyProduct.class);
return easybuyProduct;
}
访问注册中心地址栏localhost:8000:
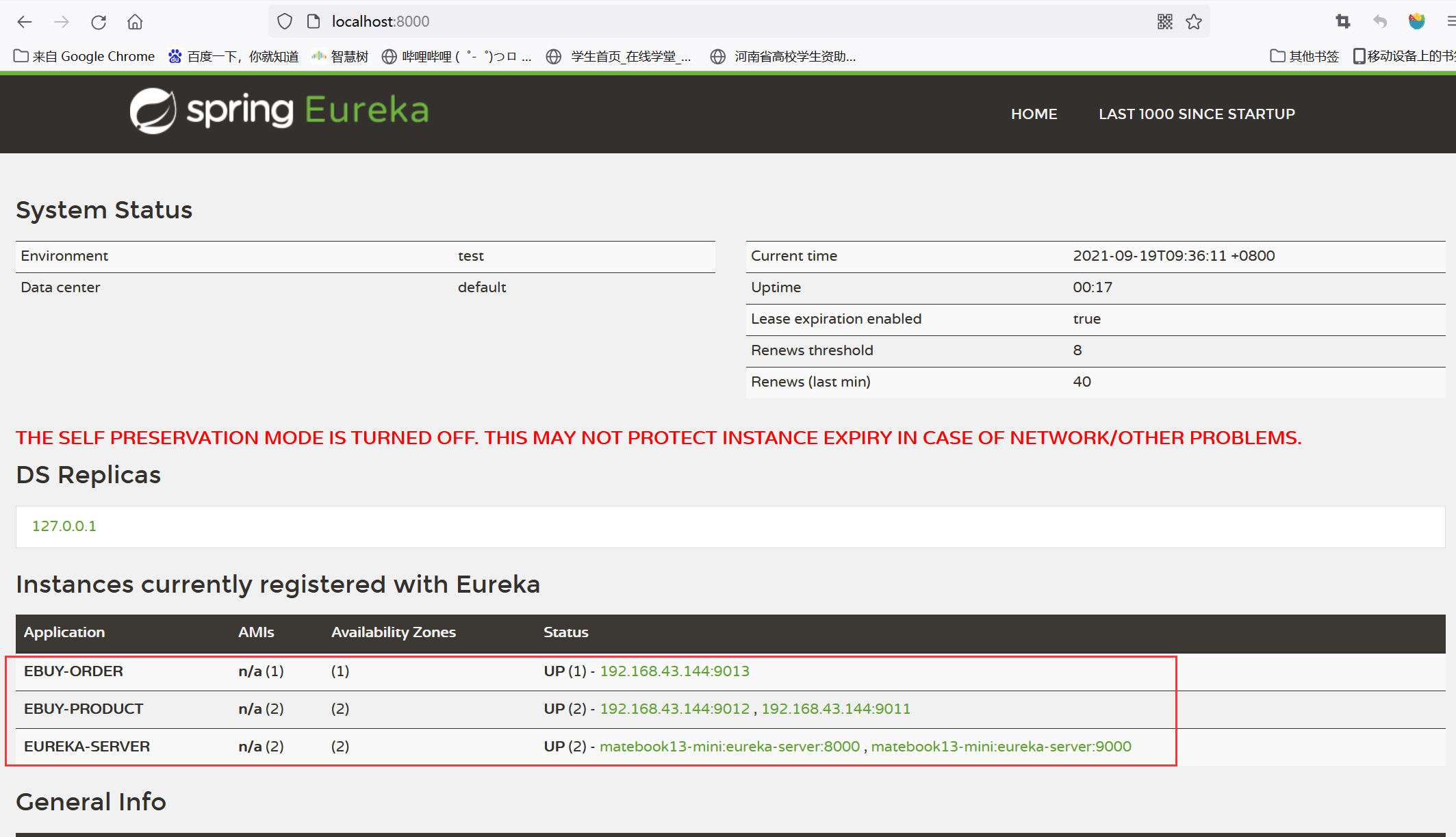
3、测试
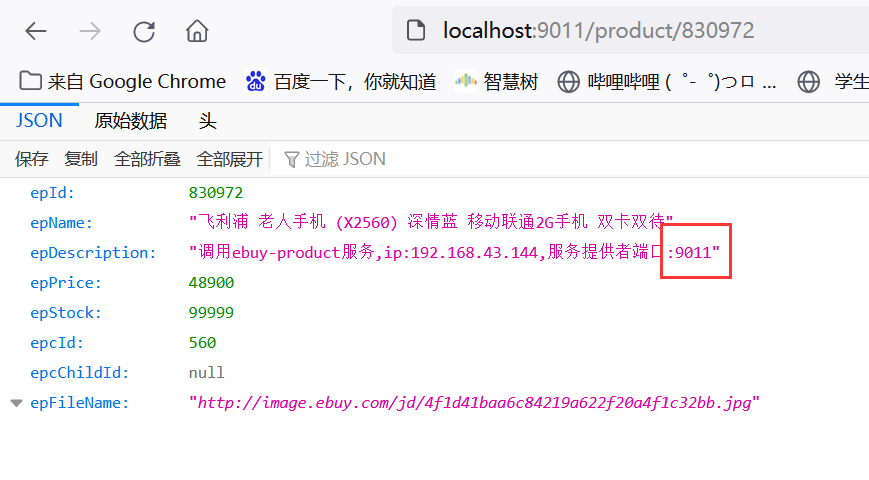
先测试ebuy-product自身查询商品信息访问地址栏:http://localhost:9011/product/830972:
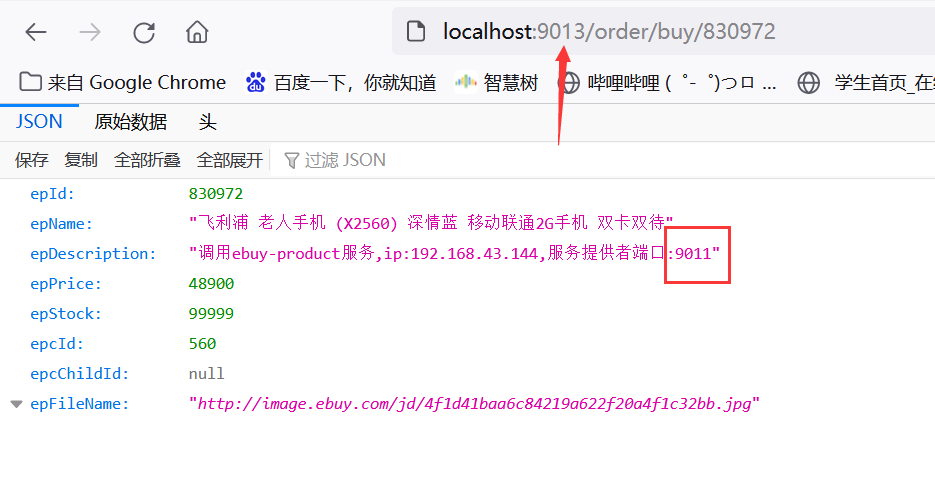
通过ebuy-order服务调用ebuy-product,看是否能够实现负载均衡,
第一次访问:http://localhost:9013/order/buy/830972
第二次访问:http://localhost:9013/order/buy/830972
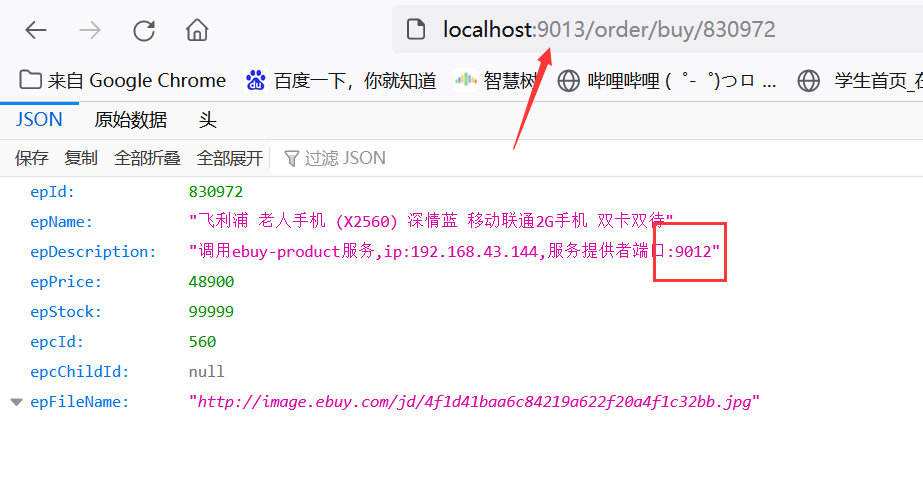
上述说明内部已经实现了负载均衡,而且默认还是RoudrobinBalanced轮询策略
4.8、负载均衡策略
Ribbon内置了多种负载均衡策略,内部负责负载均衡的顶级接口为com.netflix.loadbalancer.IRule,实现方式如下:
- 轮询策略:
com.netflix.loadbalancer.RoundRobinRule - 随机策略:
com.netflix.loadbalancer.RandomRule - 重试策略:
com.netflix.loadbalancer.RetryRule - 权重策略:
com.netflix.loadbalancer.WeightedResponseTimeRule- 会计算每个服务的权重,权重越高,被调用的可能性越大
- 最佳策略:
com.netflix.loadbalancer.BestAvailableRule- 遍历所有的服务实例,过滤掉故障实例,并返回请求数最小的实例。
- 可过滤策略:
com.netflix.loadbalancer.AvailabilityFilteringRule- 过滤掉故障和请求数超过阈值的服务实例,再从剩下的实例中轮询调用
在服务消费者ebuy-order的application.yml配置文件中修改负载均衡策略:
#需要调用的微服务名称(ebuy-order调用ebuy-product服务)
ebuy-product:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #采用随机访问机制(默认就是轮询机制)
策略选择:
- 如果每台服务器的配置基本一致,则不建议修改策略(推荐默认为轮询策略)
- 如果部分及其配置较强,则可以修改为
权重策略:WeightedResponseTimeRule
5、服务调用Feign
5.1、Feign服务调入门
@Autowired
RestTemplate restTemplate;
@RequestMapping(value = "/buy/{id}",method = RequestMethod.GET)
public EasybuyProduct findById(@PathVariable Long id) {
EasybuyProduct easybuyProduct=new EasybuyProduct();
easybuyProduct=restTemplate.getForObject("http://ebuy-product/product/"+id,EasybuyProduct.class);
return easybuyProduct;
}
前面我们使用的RestTemplate实现REST API接口调用,由代码可知,我们是使用拼接字符串的方式构造URL的,该URL只有一个参数。但是,在现实中,URL中往往含有多个参数。这时候我们如果还用这种方式构造URL,那就不合适了吧,那应该如何解决?这个时候Feign就出来了。
5.2、Feign简介
Feign是Netflix开发的声明式,模板化的HTPT客户端请求,其灵感来自Retrofit,JAXRS-2.0以及WebSocket。
- Feign可以帮助我们更加便捷,优雅的调用HTTP API接口
- 在SpringCloud中,使用Feign非常简单,创建一个接口,并在接口上添加@FeignClient注解,代码就完事了
- Feign支持多种注解,例如Feign自带的注解或者JAX-RS注解等
- SpringCloud对Feign进行了增强,使Feign支持了SpringMVC注解,并整合了Ribbon和Eureka,并整合了Ribbon和Eureka。从而让Feign的使用更加方便
5.3、基于Feign的服务调用
(1)在服务调用方引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
(2)EbuyOrderApplication启动类开启Feign支持
@SpringBootApplication
@EnableEurekaClient //开启客户端服务注册
@EnableDiscoveryClient //开启客户端服务发现
@EnableFeignClients //激活feign声明式调用
public class EbuyOrderApplication {
public static void main(String[] args) {
SpringApplication.run(EbuyOrderApplication.class, args);
}
}
通过@EnableFeignClients注解开启Spring Cloud Feign的支持功能。
(3)创建一个 Feign接口,此接口是在Feign中调用微服务的核心接口:
OrderFeignClient
/**
* 此处的feign代表声明式调用
* name:为商品微服务的服务名(不可错)
*/
@FeignClient(name="ebuy-product")
public interface OrderFeignClient {
/**
* 此处调用的是product微服务的Restful API接口
* @param id
* @return
*/
@RequestMapping(value = "/product/{id}",method = RequestMethod.GET)
public EasybuyProduct findById(@PathVariable("id") Long id);
}
- 定义各参数绑定时,@PathVariable、@Requestparam、@RequestHeader等可以指定参数属性,在Feign中绑定参数必须通过
value属性来指定具体的参数名,不然会抛出异常。 @FeignCient:注解通过name指定需要调用的微服务名称,用于创建Ribbon的负载均衡器。所以Ribbon会把ebuy-product解析为注册中心的服务。
(4)配置请求提供者的调用接口
@RestController
@RequestMapping("/order")
@SuppressWarnings("all")
public class OrderController {
/**
* feign声明式调用
*/
@Autowired
OrderFeignClient orderFeignClient;
/**
* 通过feign声明式调用product微服务Restful API接口
* @param id
* @return
*/
@RequestMapping(value = "/feign/{id}",method = RequestMethod.GET)
public EasybuyProduct feignFindById(@PathVariable Long id) {
return orderFeignClient.findById(id);
}
}
(5)重启服务,访问地址栏http://localhost:9013/order/feign/830972
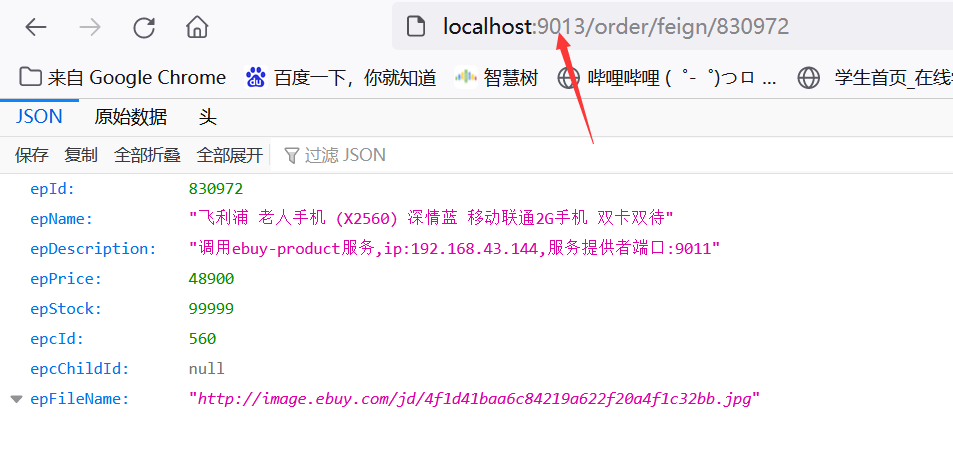
这不就妥了嘛!!!
5.4、Feign 和Ribbon的联系
- Ribbon是一个基于HTTP和TCP协议的客户端的负载均衡工具,它可以在客户端配置RibbonServerList(服务端列表),使用HttpClient或RestTmeplate模拟HTTP请求,步骤相当繁琐
- Feign是在Ribbon的基础上进行了一次修改,是一个使用起来更加方便的HTTP客户端。采用接口的方式只需要创建一个接口,然后在上面添加注解即可,将需要调用的其他服务的方法定义成抽象方法即可,而不需要自己构建HTTP请求,然后就像是在调用自身工程的方法,而感觉不到是在调用远程服务的方法,使得客户端变得非常容易。
5.5、Feign负载均衡策略
Feign本身已经集成了Ribbon依赖和自动配置,因此我们不需要额外引入依赖,也不需要再注册RestTemplate对象。同时我们也可以在application.yml文件中配置Ribbon,
- 全局配置:
ribbon.xx - 局部配置(指定服务名):
服务名.ribbon.xx
ebuy-order的application.yml文件:
#需要调用的微服务名称(局部配置,指定服务名)
ebuy-product:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #采用随机访问机制(覆盖默认的轮询机制)
- 上述
ribbon.NFLoadBalancerRuleClassName默认为轮询的负载均衡策略,可根据具体情况做修改。
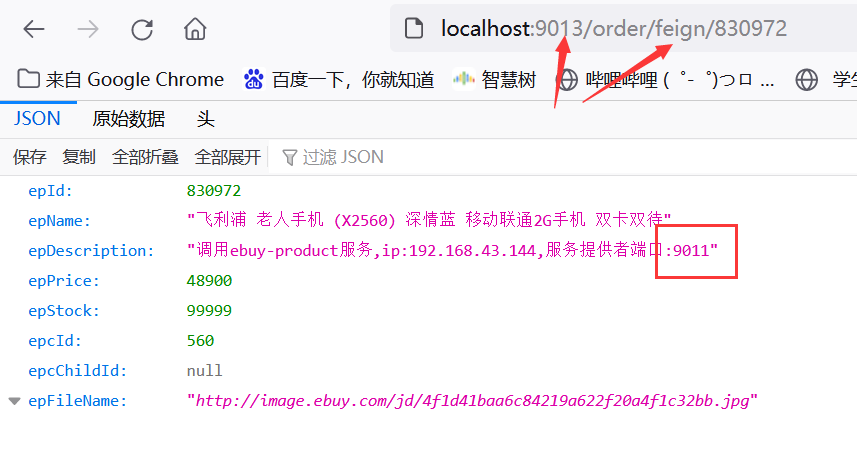
我们启动两台ebuy-product服务提供者9011和9012,ebuy-order9013通过Feign声明式调用:
第一次请求地址http://localhost:9013/order/feign/830972
第二次请求地址http://localhost:9013/order/feign/830972
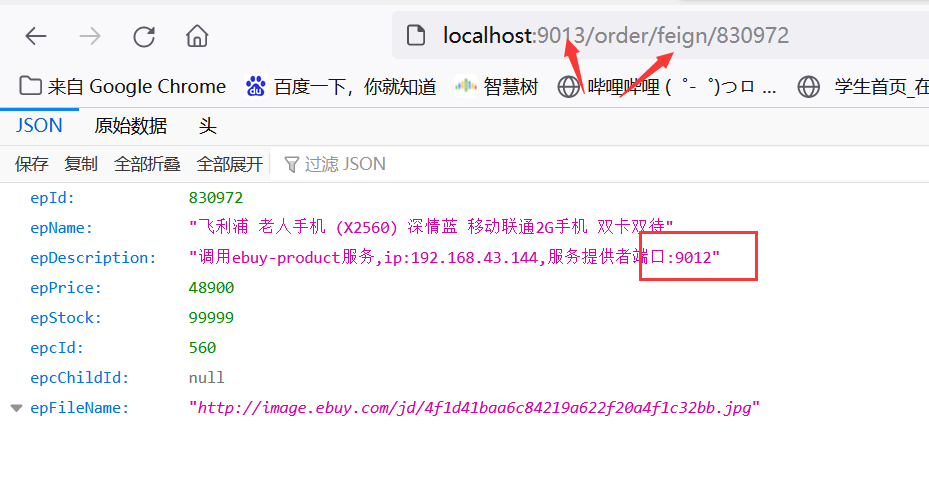
发现通过Feign声明式调用默认就是RoundRobinRule轮询策略,你说强不强,苏大强!!!
5.6、Feign高级服务调用配置
从Spring Cloud Edgware开始,Feign支持使用属性自定义Feign。对于一个指定名称的Feign
Client(例如该Feign Client的名称为 feignName ),Feign支持如下配置项:
#feign声明式调用
feign:
client:
config:
feignName : #此处feignName代表的就是要调用的服务提供者名称
loggerLevel: FULL #打印全部日志信息
connectTimeout: 5000 #相当于Request.Options
readTimeout: 5000 #相当于Request.Options
- feignName :此处feignName代表的就是要调用的FeignClient服务提供者名称
- connectTimeout : 建立链接的超时时长
- readTimeout : 读取超时时长
- loggerLevel::Fegin 的日志级别
5.7、请求压缩
Spring Cloud Feign 支持对请求和响应进行GZIP压缩,以减少通信过程中的性能损耗。通过下面的参数即可开启请求与响应的压缩功能:
#feign声明式调用
feign:
client:
config:
ebuy-product:
loggerLevel: FULL #打印全部日志信息
connectTimeout: 5000 #相当于Request.Options
readTimeout: 5000 #相当于Request.Options
compression:
request:
enabled: true #开启请求压缩
min-request-size: 2048 #设置触发压缩的大小下限
mime-types: text/html,application/xml,application/json # 设置压缩的数据类型
response:
enabled: true #开启响应压缩
注:上面的数据类型、压缩大小下限均为默认值。
5.8、日志级别
在开发或者运行阶段往往希望看到Feign请求过程的日志记录,默认情况下Feign的日志是没有开启的。要想用属性配置方式来达到日志效果,只需在 application.yml 中添加如下内容即可:
#上述已配置
feign:
client:
config:
ebuy-product:
loggerLevel: FULL #打印全部日志信息
logging:
level:
com.ebuy.order.feign.OrderFeignClient: DEBUG
logging.level.xx : debug:Feign日志只会对日志级别为debug的做出响应feign.client.config.ebuy-product.loggerLevel : FULL:配置Feign的日志有四种
日志级别:- NONE 【性能最佳,适用于生产】:不记录任何日志(默认值)
- BASIC 【适用于生产环境追踪问题】:仅记录请求方法、URL、响应状态代码以及执行时间
- HEADERS :在BASIC级别的基础上,记录请求和响应的header。
- FULL 【比较适用于开发及测试环境定位问题】:记录请求和响应的header、body和元数据。
6、服务注册与发现小总结
6.1、注册中心
(1)Eureka
- 搭建注册中心(服务端)
- 引入依赖
spring -cloud-starter-netflix-eureka-server - 配置
EurekaServer - 通过
@EnableEurekaServer注解标注启动类,激活Eureka Server端配置
- 引入依赖
- 服务注册(客户端)
- 服务提供者引入
spring -cloud-starter-netflix-eureka-client依赖 - 通过
eureka.client.serviceUrl.defaultZone配置注册中心地址
- 服务提供者引入
(2)Consul
- 搭建注册中心(服务端)
- 下载安装 consul
- 启动 consul,命令:
consul agent -dev -client:0.0.0.0
- 服务注册(客户端)
- 服务提供者引入
spring -cloud-starter-consul-discovery依赖 spring.cloud.consul.host:设置请求地址spring.cloud.consul.port:设置请求端口
- 服务提供者引入
6.2、服务调用
(1)Ribbon
- 通过 Ribbon结合RestTemplate方式进行服务调用只需要在创建RestTemplate的方法上添加注解@LoadBalanced即可
- 可以通过
服务名称.ribbon.NFLoadBalancerRuleClassName配置负载均衡策略
(2)Feign
- 服务消费者引入
spring -cloud-starter-openfeign依赖 - 启动类上通过
@EnableFeignClients激活Feign声明 - 通过
@FeignClient声明一个调用远程微服务接口
7、Hystrix:服务熔断降级处理
7.1、雪崩效应
在微服务架构中,一个请求中需要调用多个服务是非常常见的,如客户端访问A服务,而A服务需要调用B服务,B服务需要调用C服务,由于网络原因或者自身的原因,如果B服务或者C服务不能够及时响应,A服务将处于阻塞状态,直到B服务或C服务完成响应。此时如果有大量的A服务请求涌入,容器的线程资源会被消耗完毕,导致系统服务瘫痪。服务与服务之间的依赖性,故障会传播,造成连锁反应,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的 雪崩效应。
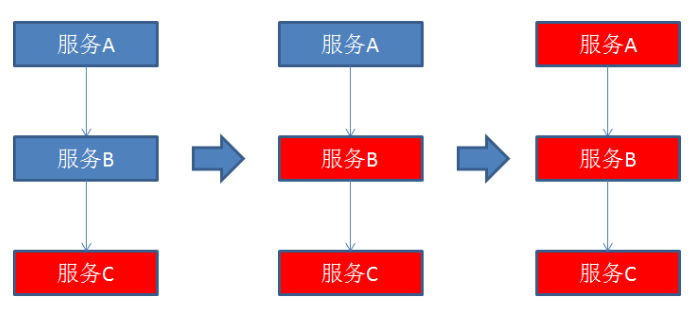
雪崩效应系统中的蝴蝶效应导致其发生的原因多种多样:
- 不合理的容量设计
- 高并发下某一个方法响应变慢
- 某台机器的资源耗尽
从源头上我们无法杜绝雪崩效应的发生,但是雪崩的根本原因来源于服务之间的强依赖行,所以我们可以提前做出评估,做好熔断、隔离、限流。
1、服务熔断降级
熔断这一概念来源于电子工程中的断路器(Circuit Breaker)。在互联网系统中,当下游服务因访问压力过大而响应变慢或失败时,上游服务为了保护系统整体的可用性(A),可以暂时切断对下游服务的调用,这种牺牲局部,保全整体的措施就叫做熔断。
所谓降级,就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback方法进行回调,返回一个缺省值,也可以理解为兜底。
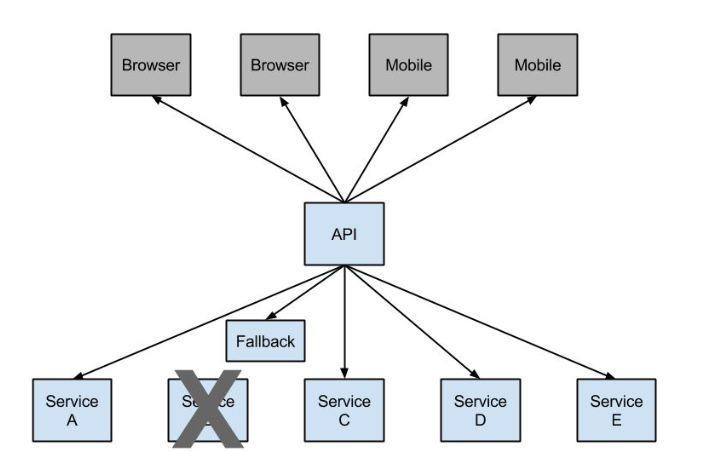
2、服务隔离
顾名思义,它是指将系统按照一定的原则划分成若干个服务模块,各个模块之间相互独立,无强依赖。当有故障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不波及其他模块,不影响整体的系统服务。
3、服务限流
限流可以认为是服务降级的一种,限流即使限制系统的输入和输出流量,以达到保护系统的目的,一般来说系统的吞吐量是可以被预算的,为了保证系统的稳固运行,一旦达到需要限制的阀值,就需要限制流量,并采取少量措施以完成限制流量的目的。比如:推迟解决、拒绝解决、或者部分拒绝解决等。
7.2、Hystrix介绍

Hystrix是由Netflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止级联失败,从而提高系统的可用性和容错性。Hystrix主要通过以下几点实现延迟和容错。
- 包裹请求:使用
HystrixCommand包裹对依赖的调用逻辑,每个命令在独立线程中执行。这使用了设计模式中的命令模式。 - 跳闸机制: 当某服务的错误率超过一定的阈值时,Hystrix可以自动或手动跳闸,停止一段时间对该服务的请求。
- 资源隔离: Hystrix为每个依赖都维护了一个小型的线程池(或者信号量),如果该线程池已满,发生该依赖的请求就会被立即拒绝,而不是排队等待,从而加速失败判定。
- 监控: Hystrix可以近乎实时地监控运行运行指标和配置的变化,例如成功、失败、超时以及被拒绝的请求个数等。
7.3、Rest请求实现服务熔断
我们仍然以上述的工程为基础。
(1)在ebuy-order服务调用者pom文件中,配置依赖
<!--hystrix熔断降级依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
(2)开启熔断支持
在启动类EbuyOrderApplication上添加注解@EnableCircuitBreaker开启熔断支持
@SpringBootApplication
@EnableEurekaClient //开启Eureka客户端服务注册
@EnableDiscoveryClient //开启服务发现
@EnableFeignClients //激活feign声明式调用
@EnableCircuitBreaker //开启熔断支持
//@SpringCloudApplication
public class EbuyOrderApplication {
/**
* @Bean 配置RestTemplate交给spring管理
* @LoadBalanced 实现负载均衡(Ribbon原理)
* @return
*/
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(EbuyOrderApplication.class, args);
}
}
可以看到,我们类上的注解越来越多,在微服务中,经常会引入上面的几个常用注解,于是 Spring就提供了一个组合注解:@SpringCloudApplication,但是不建议使用这个组合注解,在启动类处标清楚所用的注解,可以很清楚的知道当前微服务正在使用的有哪些技术栈操作。
(3)配置熔断降级业务逻辑(局部方法熔断)
@RestController
@RequestMapping("/order")
@SuppressWarnings("all")
public class OrderController {
@Autowired
RestTemplate restTemplate;
/**
* 通过RestTemplate直接跨项目调用(可以实现负载均衡)
* @PathVariable 将restful中的参数id映射到形参列表
* @HystrixCommand(fallbackMethod = "orderFallBack") 熔断降级
*/
@RequestMapping(value = "/buy/{id}",method = RequestMethod.GET)
@HystrixCommand(fallbackMethod = "orderFallBack")
public EasybuyProduct findById(@PathVariable Long id) {
//制造异常熔断降级
if(id != 738388){
throw new RuntimeException("请求出现异常,请重试!");
}
return restTemplate.getForObject("http://ebuy-product/product/"+id,EasybuyProduct.class);
}
/**
* 降级方法
* @param id 使用全局服务熔断降级处理时,降级处理函数orderFallBack不可以有参数
* @param id 使用局部熔断时,fallback方法的参数和返回值类型必须和要使用降级处理的方法保持一致
* @param @PathVariable Long id
*/
public EasybuyProduct orderFallBack(@PathVariable Long id) {
System.out.println("熔断:触发降级方法");
EasybuyProduct easybuyProduct = new EasybuyProduct();
easybuyProduct.setEpDescription("熔断:触发降级方法");
return easybuyProduct;
}
}
上述代码可知,在findById()方法上,使用注解@HystrixCommand的fallbackMethod属性,指定熔断触发的降级方法是orderFallBack()。
下方为findById()方法编写一个回退方法orderFallback,该方法与findById具有相同的参数和返回值类型,该方法返回一个默认的错误信息。
- 局部方法熔断的降级逻辑方法必须和正常逻辑方法保证:相同的参数列表和返回值声明。
- 在
findById()方法上标注@HystrixCommand(fallbackMethod = "orderFallBack")用来声明一个降级逻辑的办法。
(4)测试局部熔断
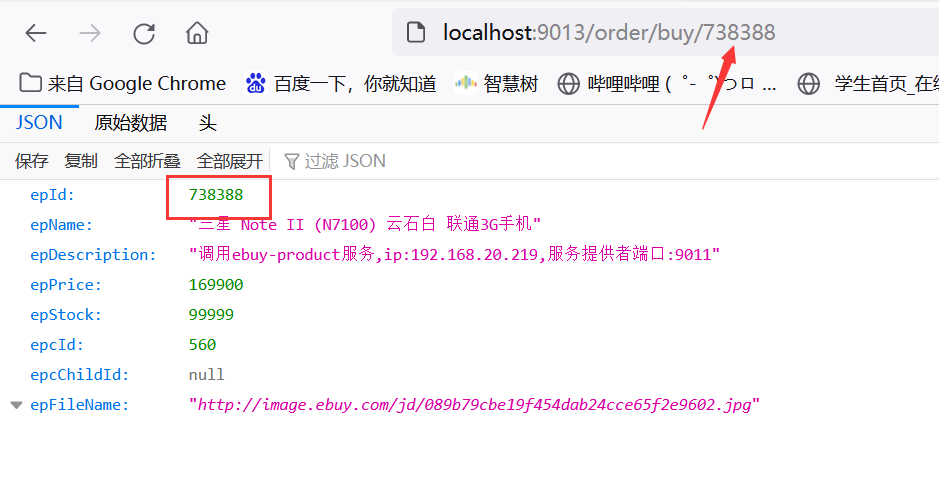
访问地址http://localhost:9013/order/buy/738388正常显示:
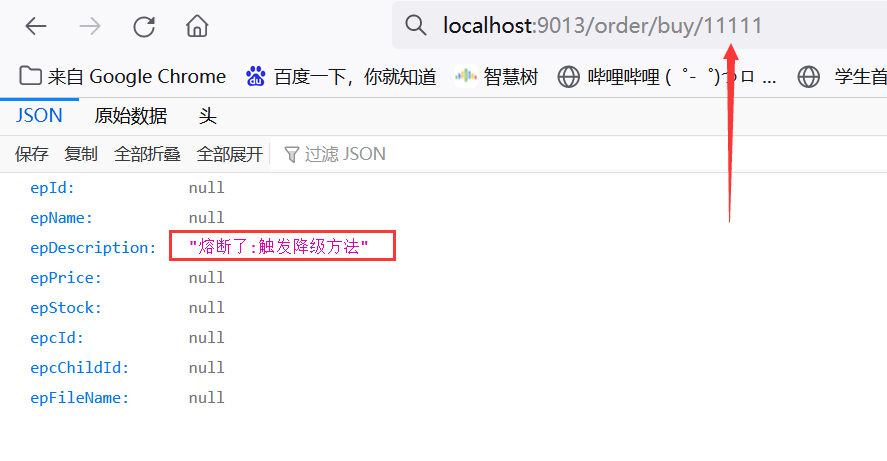
这个时候为了测试触发熔断降级,我们可以将ebuy-product服务提供者直接宕机,但是我们为了方便演示,在上述findById()代码中已经事先在程序中制造了一个运行时异常,只要id != 738388则会抛出异常,模拟服务终端从操作,下面让我们来随便输入一个id值访问地址localhost:9013/order/buy/11111
(5)全局熔断
上述我们把fallback写在了某一个业务方法上,很显然这样做不合适,如果有很多业务方法时,那岂不是要写很多个fallback回调方法,所以我们可以把fallback配置在类上,实现默认的fallback方法,我们称为全局熔断:
@RestController
@RequestMapping("/order")
@SuppressWarnings("all")
@DefaultProperties(defaultFallback = "orderFallBack") //全局熔断降级
public class OrderController {
@Autowired
RestTemplate restTemplate;
/**
* 通过RestTemplate直接跨项目调用(可以实现负载均衡)
* @PathVariable 将restful中的参数id映射到形参列表
* @HystrixCommand(fallbackMethod = "orderFallBack") 熔断降级
*/
@RequestMapping(value = "/buy/{id}",method = RequestMethod.GET)
@HystrixCommand
public EasybuyProduct findById(@PathVariable Long id) {
//制造异常熔断降级
if(id != 738388){
throw new RuntimeException("请求出现异常,请重试!");
}
return restTemplate.getForObject("http://ebuy-product/product/"+id,EasybuyProduct.class);
}
/**
* 降级方法
* @param id 使用全局服务熔断降级处理时,降级处理函数orderFallBack不可以有参数
* @param id 使用局部熔断时,fallback方法的参数和返回值类型必须和要使用降级处理的方法保持一致
* @param @PathVariable Long id
*/
public EasybuyProduct orderFallBack() {
System.out.println("全局熔断了:触发降级方法");
EasybuyProduct easybuyProduct = new EasybuyProduct();
easybuyProduct.setEpDescription("全局熔断了:触发降级方法");
return easybuyProduct;
}
}
做出的修改:
- 在OrderController类上标注
@DefaultProperties(defaultFallback = "orderFallBack") - 在需要降级熔断处理的业务逻辑方法上标注
@HystrixCommand标识 - 注意:
orderFallBack()方法不可以有参数列表,但是返回值要和方法的返回值类型保持一致(其实这点设计的不是很完善,一个Controller类中有若干份个方法,但是所有方法不可能返回值都保持一致,所以说有局限性)
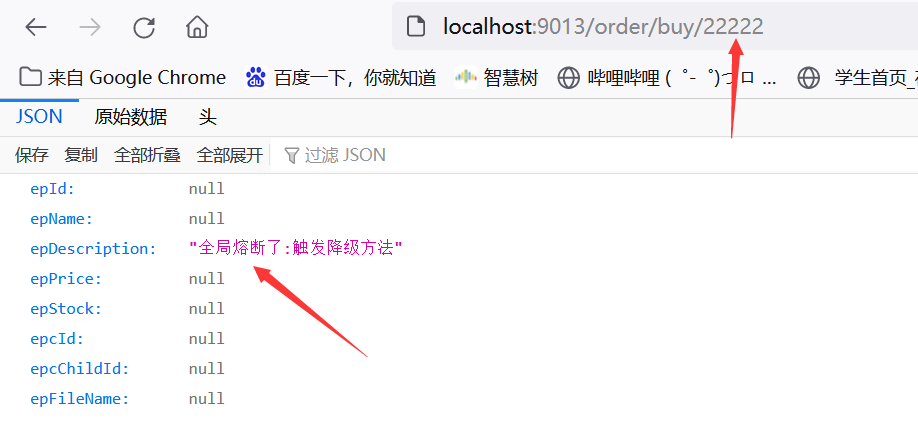
测试,访问地址栏id随便输:http://localhost:9013/order/buy/22222
(6)超时设置
在之前的案例中,其实隐含着一个条件,就是请求在超过1秒后都会返回错误信息(也就是会发生熔断降级处理),这是因为Hystix的默认超时时长为1秒,我们可以通过配置修改这个值:
#hystrix线程请求超时时间(毫秒)
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 1000 #默认即为1秒
我们将ebuy-product的ProductController层的请求方法findById(),模拟请求超时,让其线程等待2秒,然后在通过ebuy-order访问调用ebuy-product的findById方法:
@RestController
@RequestMapping("/product")
public class ProductController {
/**
* 回去客户端ip地址
*/
@Value("${spring.cloud.client.ip-address}")
private String ip;
/**
* 获取客户端的端口号
*/
@Value("${server.port}")
private String port;
@Autowired
private EasybuyProductService productService;
@RequestMapping(value = "/{id}",method = RequestMethod.GET)
public EasybuyProduct findById(@PathVariable Long id) {
//制造线程沉睡2秒
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
EasybuyProduct product = productService.selectByPrimaryKey(id);
product.setEpDescription("调用ebuy-product服务,ip:"+ip+",服务提供者端口:"+port);
return product;
}
}
重新启动ebuy-product服务,端口号改为9012,先通过自身访问,http://localhost:9012/product/738388:
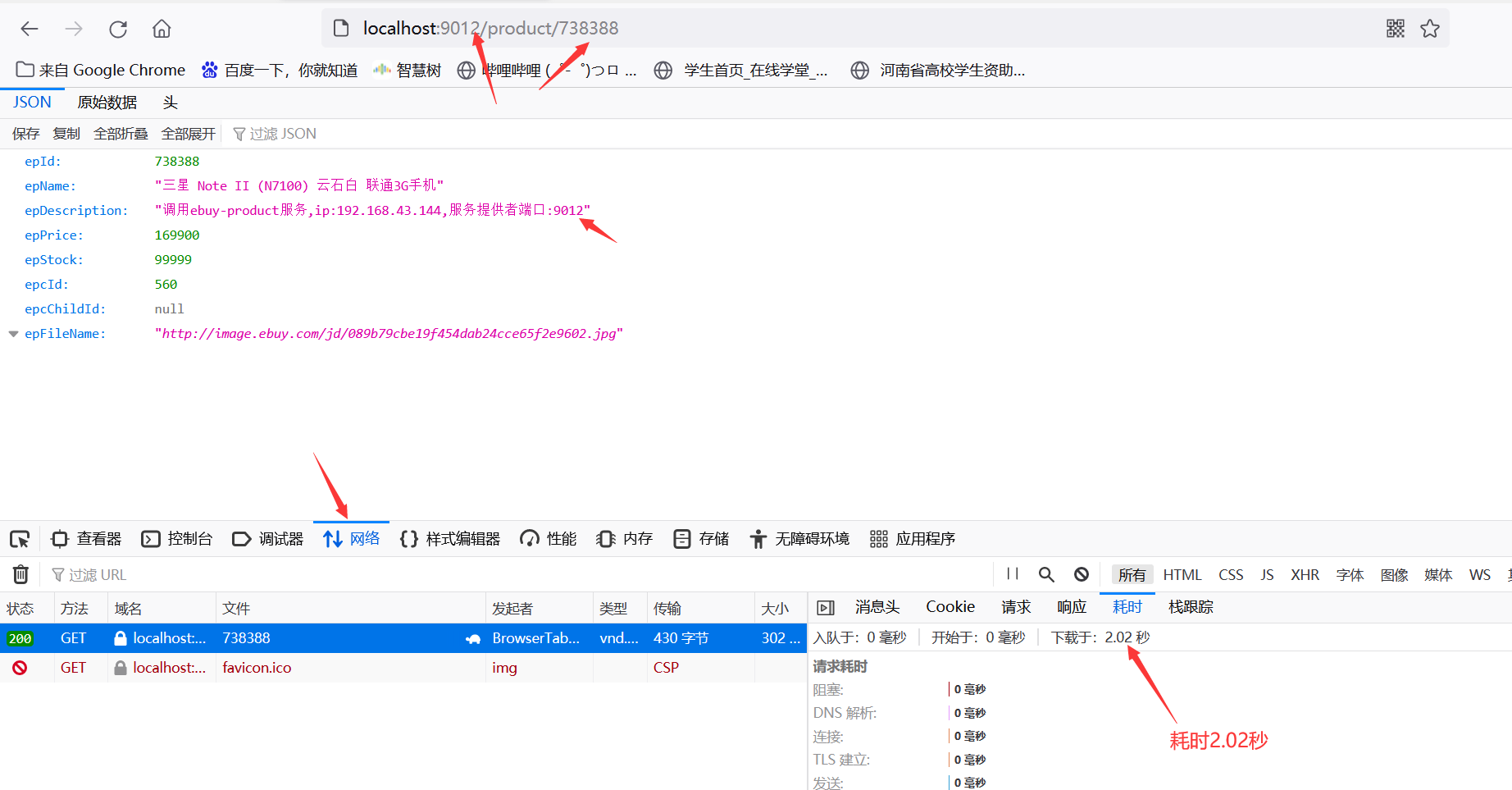
通过ebuy-order输入正确的id访问地址localhost:9013/order/buy/738388:
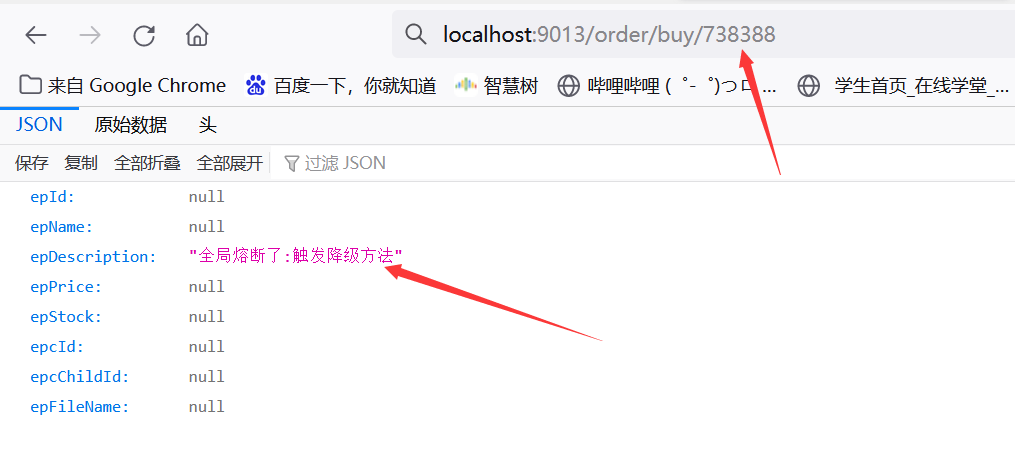
你会发现无论如何访问,始终都是发生熔断降级处理,这就是因为上述所说的hystrix默认的请求超时时间为1秒,我们现在通过配置将其设置为3秒:
#hystrix线程请求超时时间(毫秒)
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 3000 #默认为1秒,时间太短,此处设为3秒
重新启动ebuy-order服务,再次访问地址localhost:9013/order/buy/738388
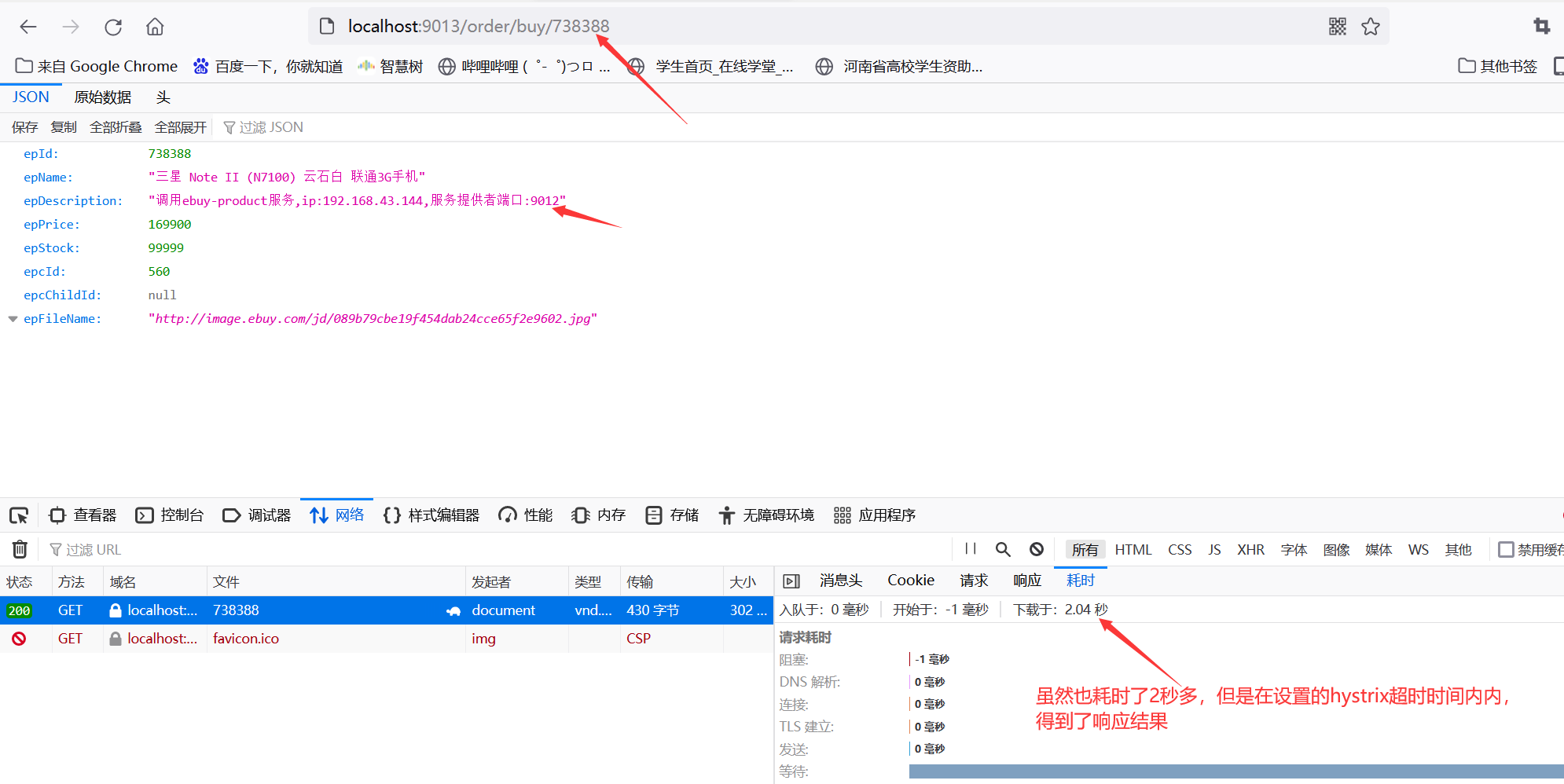
7.4、Feign 实现服务熔断
SpringCloud Feign内部已经整合了hystrix,所以添加了Feign的相关依赖后,就不需要再单独添加hystrix相关的依赖了,那么怎么才能让Feign的熔断机制生效呢,只需按照以下步骤开发:
(1)修改ebuy-order服务中的application.yml,在Fegin中开启hystrix支持,feign内部虽然整合了hystrix,但是默认的超时时间设置仍然需要通过hystrix节点单独配置:
#feign声明式调用
feign:
hystrix:
enabled: true #在feign中开启hystrix熔断
hystrix暂不配置,仍然是先使用hystrix默认的1秒。
(2)配置OrderFeignClient接口,在@FeignClient注解中添加降级方法
@FeignClient(name="ebuy-product",fallback = OrderFeignClientFallBack.class)
public interface OrderFeignClient {
/**
* 此处调用的是product微服务的Restful API接口
* @param id
* @return
*/
@RequestMapping(value = "/product/{id}",method = RequestMethod.GET)
public EasybuyProduct findById(@PathVariable("id") Long id);
}
(3)配置OrderFeignClient接口的实现类OrderFeignClientFallBack
@Component
public class OrderFeignClientFallBack implements OrderFeignClient {
/**
* 降级方法
*/
public EasybuyProduct findById(Long id) {
System.out.println("feign熔断:触发降级方法");
EasybuyProduct easybuyProduct = new EasybuyProduct();
easybuyProduct.setEpDescription("feign熔断:触发降级方法");
return easybuyProduct;
}
}
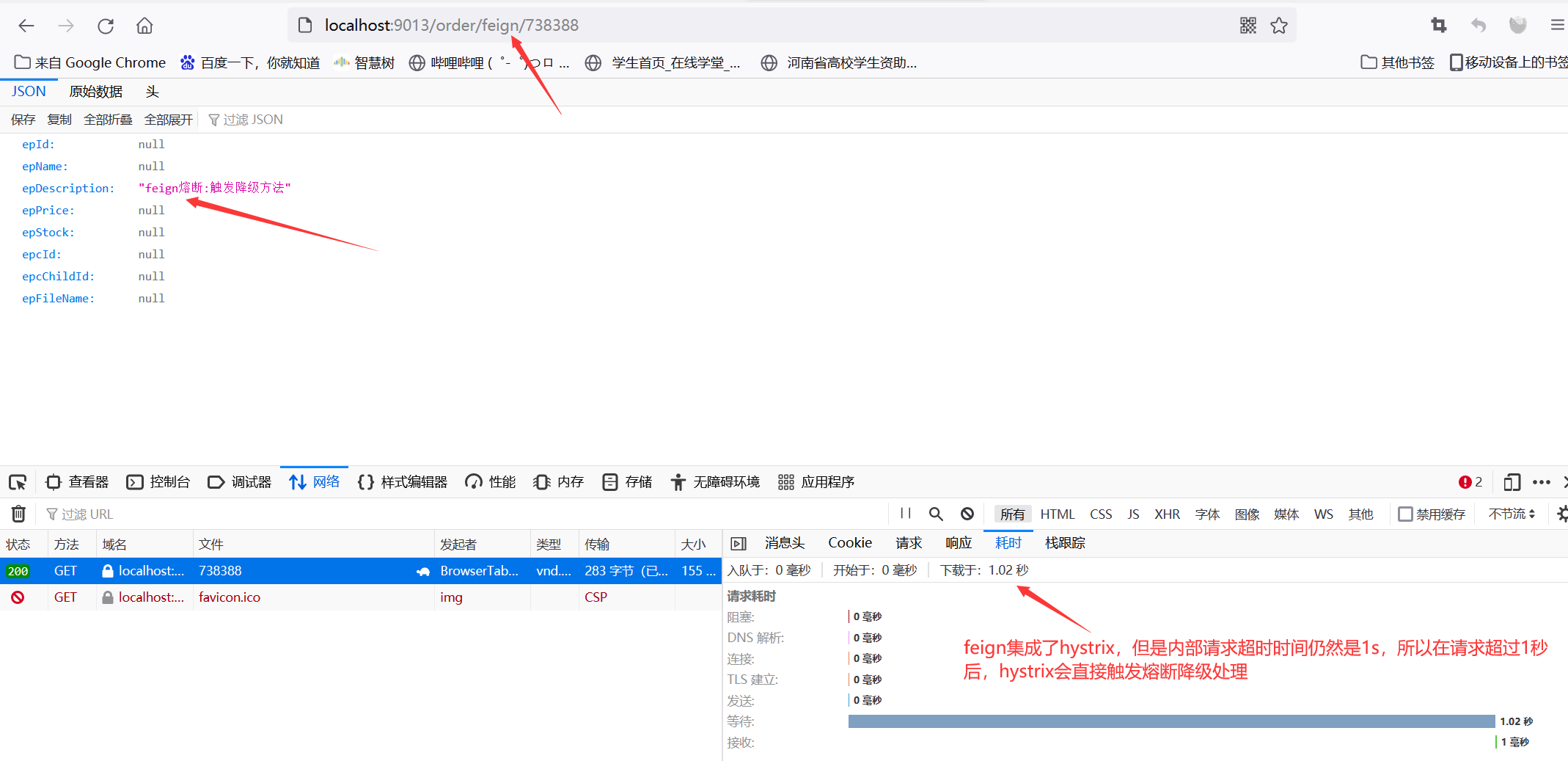
修改application.yml文件中的hystrix默认时间
#hystrix线程请求超时时间
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 3000 #默认为1秒,时间太短,此处设为3秒
重新启动ebuy-order服务,重新访问地址:http://localhost:9013/order/feign/738388
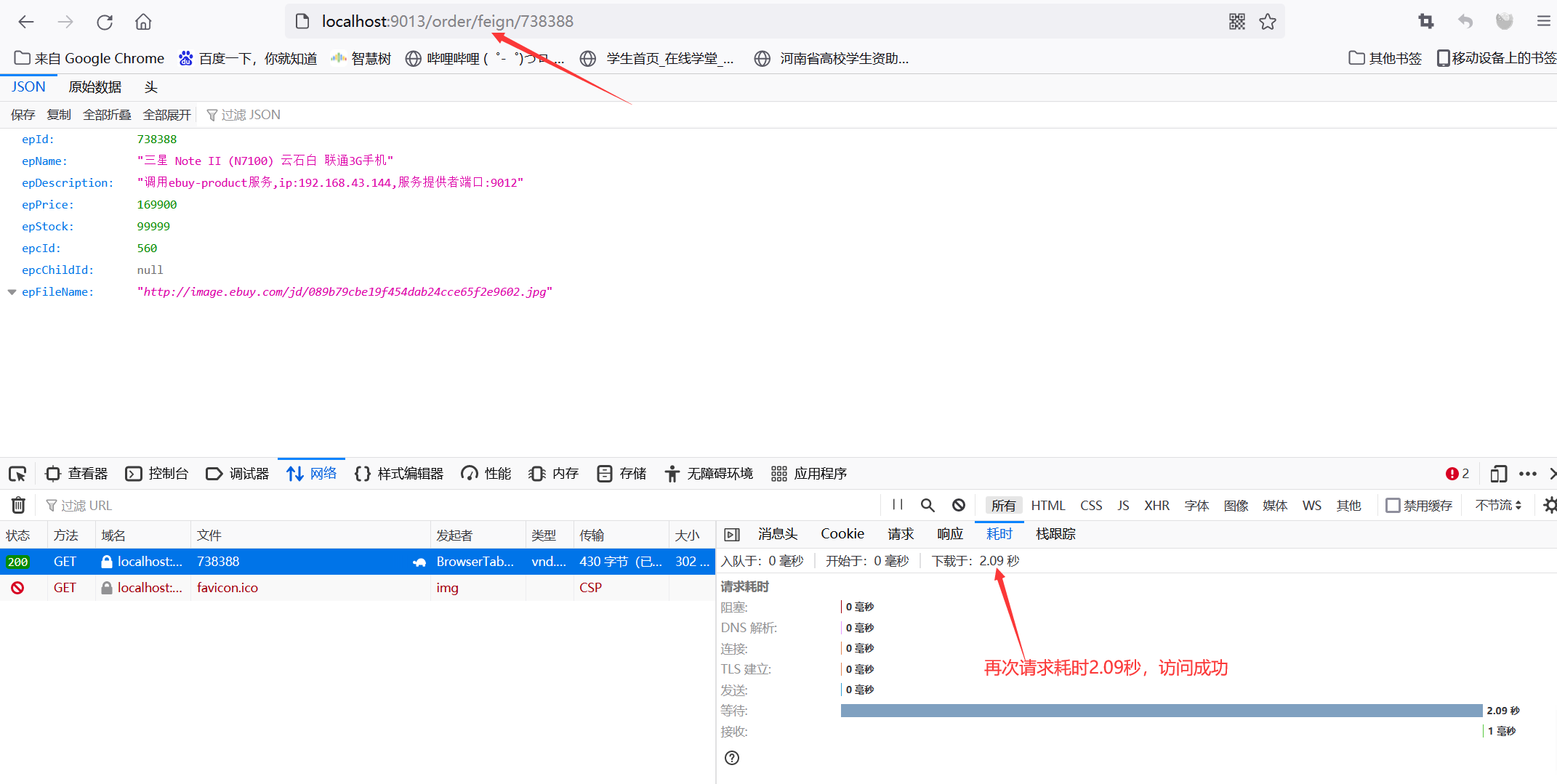
7.5、服务熔断Hystrix高级
我们知道,当请求失败,被拒绝,超时的时候,都会进入到降级方法中。但进入降级方法并不意味着断路器已经被打开。那么如何才能了解断路器中的状态呢?
1、Hystrix的监控平台
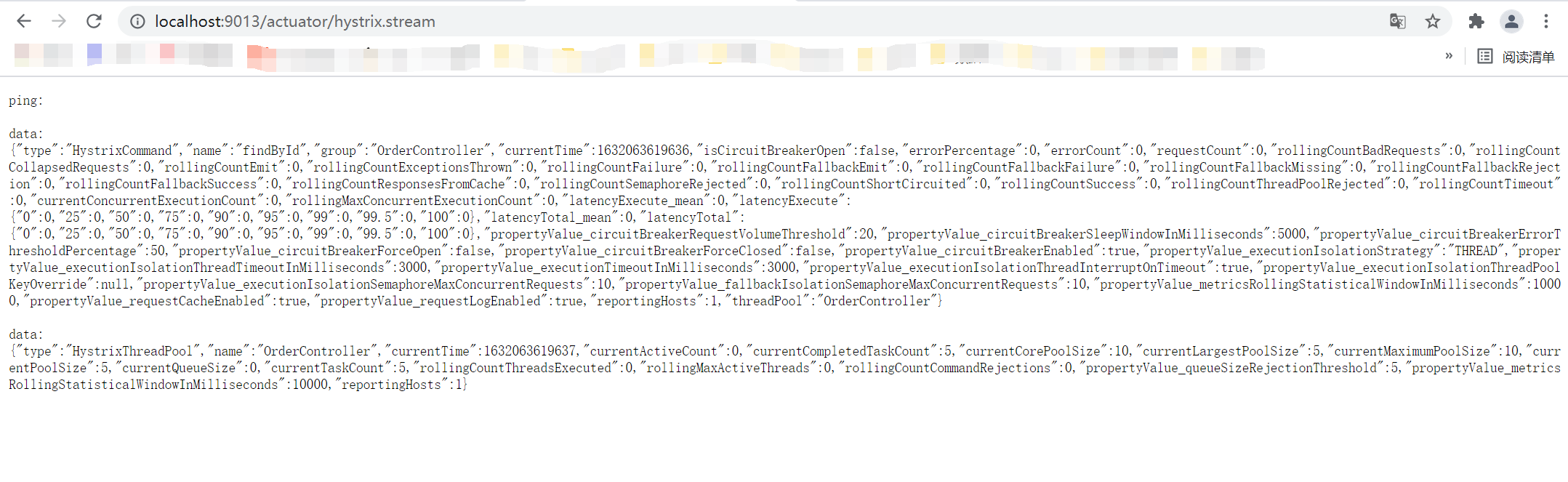
除了实现容错功能,Hystrix还提供了近乎实时的监控,HystrixCommand和HystrixObservableCommand在执行时,会生成执行结果和运行指标。比如每秒的请求数量,成功数量等。这些状态会暴露在Actuator提供的/health健康检测端点中。只需为项目添加spring -boot-actuator依赖,重启项目,访问 http://localhost:port端口号/actuator/hystrix.stream ,即可看到实时的监控数据。
2、搭建Hystrix DashBoard监控
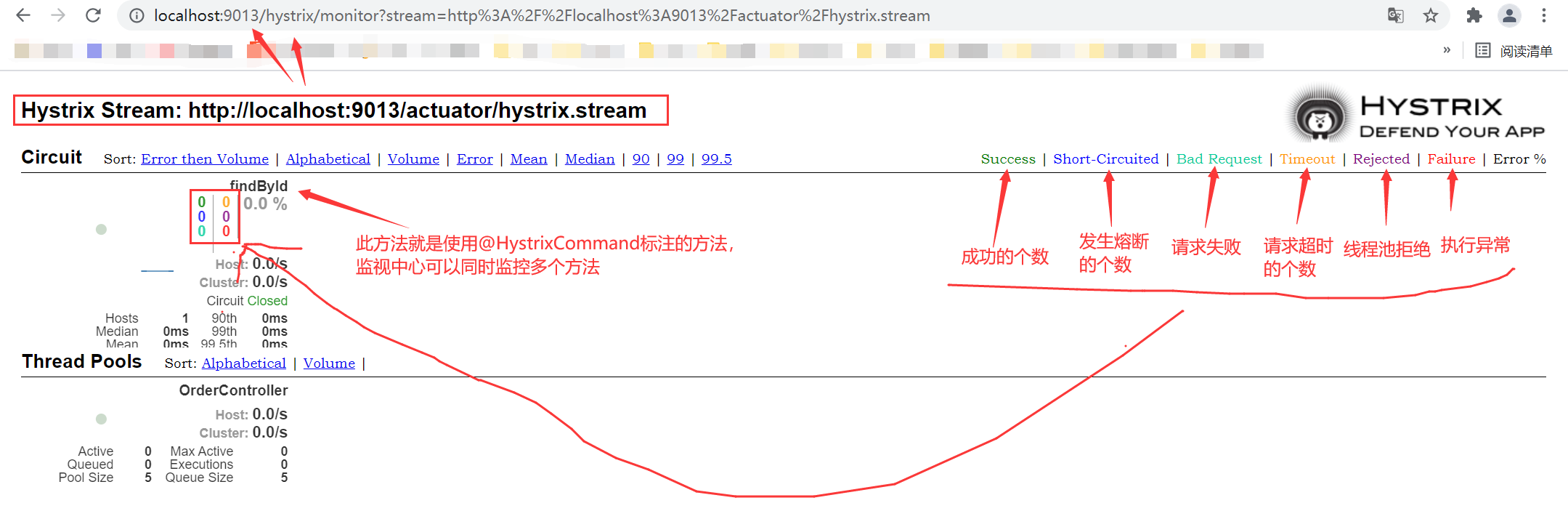
刚刚讨论了Hystrix的监控,但访问/hystrix.stream接口获取的都是以文字形式展示的信息。很难通过文字直观的展示系统的运行状态,所以Hystrix官方还提供了基于图形化的DashBoard(仪表板)监控平台。Hystrix仪表板可以显示每个断路器(被@HystrixCommand注解的方法)的状态。
(1)在ebuy-product的pom中引入依赖:
<!--心跳检测依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--开启hystrix服务熔断依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<!--hystrix dashboard动态监视中心-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
(2)在EbuyOrderApplication启动类中添加注解添加@EnableHystrixDashboard注解,开启监视中心支持
@SpringBootApplication
@EnableEurekaClient //开启Eureka客户端服务注册
@EnableDiscoveryClient //开启服务发现
@EnableFeignClients //激活feign声明式调用
@EnableCircuitBreaker //开启熔断支持
@EnableHystrixDashboard //激活仪表盘项目
public class EbuyOrderApplication {
/**
* @Bean 配置RestTemplate交给spring管理
* @LoadBalanced 实现负载均衡(Ribbon原理)
* @return
*/
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(EbuyOrderApplication.class, args);
}
}
访问http://localhost:9013/hystrix

此时我们是在ebuy-order服务消费者的服务上建立的hystrix dashboard监视中心,所以直接输入地址http://localhost:9013/actuator/hystrix.stream即可
7.6、断路器聚合监控Turbine
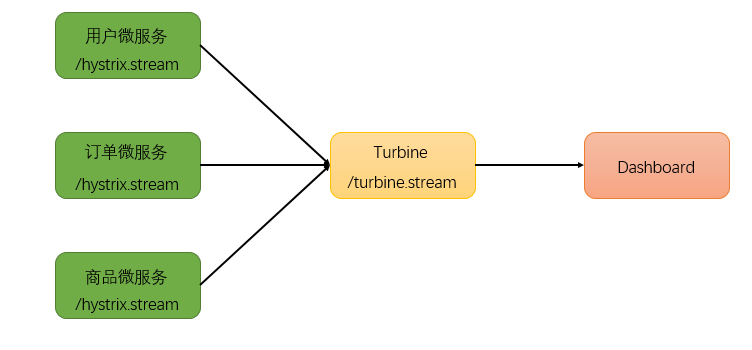
在微服务架构体系中,每个服务都需要配置Hystrix DashBoard监控。如果每次只能查看单个实例的监控数据,就需要不断切换监控地址,这显然很不方便。要想看这个系统的Hystrix Dashboard数据就需要用到Hystrix Turbine。Turbine是一个聚合Hystrix 监控数据的工具,他可以将所有相关微服务的Hystrix 监控数据聚合到一起,方便使用。引入Turbine后,整个监控系统架构如下:
(1) 搭建TurbineServer微服务监视中心,ebuy-turbine微服务
引入相关依赖坐标:
<!--断路器聚合监控Turbine-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-turbine</artifactId>
<version>2.2.0.RELEASE</version>
</dependency>
<!--熔断器hystrix-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.2.0.RELEASE</version>
</dependency>
<!--hystrix dashboard监视仪表盘-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
<version>2.2.0.RELEASE</version>
</dependency>
(2) 配置多个微服务的hystrix监控, 在application.yml的配置文件中开启turbine并进行相关配置:
server:
port: 8031 #端口
spring:
application:
name: ebuy-turbine #服务名称
logging:
level:
cn.ebuy: DEBUG
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8000/eureka/,http://127.0.0.1:9000/eureka/
instance:
prefer-ip-address: true #使用IP地址註冊
lease-expiration-duration-in-seconds: 10 #eureka client发送心跳给server端后,续约到期时间(默认90秒)
lease-renewal-interval-in-seconds: 5 #发送心跳续约间隔
turbine:
app-config: ebuy-order,ebuy-product
cluster-name-expression: "'default'"
- eureka 相关配置 : 指定注册中心地址
- turbine 相关配置:指定需要监控的微服务列表
- turbine会自动的从注册中心中获取需要监控的微服务,并聚合所有微服务中的 /hystrix.stream 数据
(3)配置启动类
@SpringBootApplication
@EnableTurbine //并激活Turbine
@EnableHystrixDashboard //开启 HystrixDashboard监控平台,
public class EbuyTurbineApplication {
public static void main(String[] args) {
SpringApplication.run(EbuyTurbineApplication.class, args);
}
}
(4)测试
浏览器访问 http://localhost:8031/hystrix 展示HystrixDashboard。并在url位置输入 http://local host:8031/turbine.stream ,动态根据turbine.stream数据展示多个微服务的监控数据
7.7、熔断器的状态
熔断器有三个状态 CLOSED 、 OPEN 、 HALF_OPEN 熔断器默认关闭状态,当触发熔断后状态变更为OPEN ,在等待到指定的时间,Hystrix会请求检测服务是否开启,这期间熔断器会变为 HALF_OPEN 半开启状态,熔断探测服务可用,则继续变更为 CLOSED 关闭熔断器。
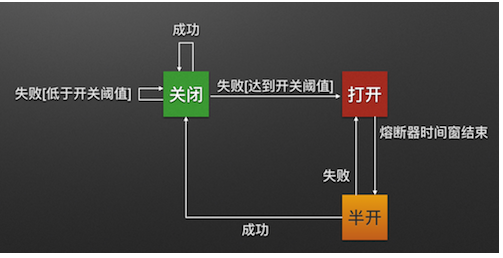
- Closed:关闭状态(断路器关闭) ,所有请求都正常访问。代理类维护了最近调用失败的次数,如果某次调用失败,则使失败次数加1。如果最近失败次数超过了在给定时间内允许失败的阈值,则代理类切换到断开(Open)状态。此时代理开启了一个超时时钟,当该时钟超过了该时间,则切换到半断开(Half-Open)状态。该超时时间的设定是给了系统一次机会来修正导致调用失败的错误。
- Open :打开状态(断路器打开) ,所有请求都会被降级。Hystix会对请求情况计数,当一定时间内失败请求百分比达到阈值,则触发熔断,断路器会完全关闭。默认失败比例的阈值是50%,请求次数最少不低于20次。
- Half Open :半开状态 ,此open状态不是永久的,打开后会进入休眠时间(
默认是5S)。随后断路器会自动进入半开状态。此时会释放1次请求通过,若这个请求是健康的,则会关闭断路器,否则继续保持打开,再次进行5秒休眠计时。
此处的服务休眠表示的是,一旦请求异常或失败超过一定的比例,熔断被触发后,默认会处于熔断5秒中,5秒后会释放一次重新请求服务,如果请求成功,则会关闭断路器。
7.8、为了能够精确控制请求的成功或失败,我们在 ebuy-order的调用业务中加入一段逻辑:
@RequestMapping(value = "/buy/{id}",method = RequestMethod.GET)
@HystrixCommand
public EasybuyProduct findById(@PathVariable Long id) {
//制造异常熔断降级
if(id != 738388){
throw new RuntimeException("请求出现异常,请重试!");
}
return restTemplate.getForObject("http://ebuy-product/product/"+id,EasybuyProduct.class);
}
这样如果参数是 id为738388,一定成功,其它情况都失败。
我们准备两个请求窗口:
- 一个请求: http://localhost:9013/consumer/11111,注定失败
- 一个请求: http://localhost:9013/consumer/738388,肯定成功
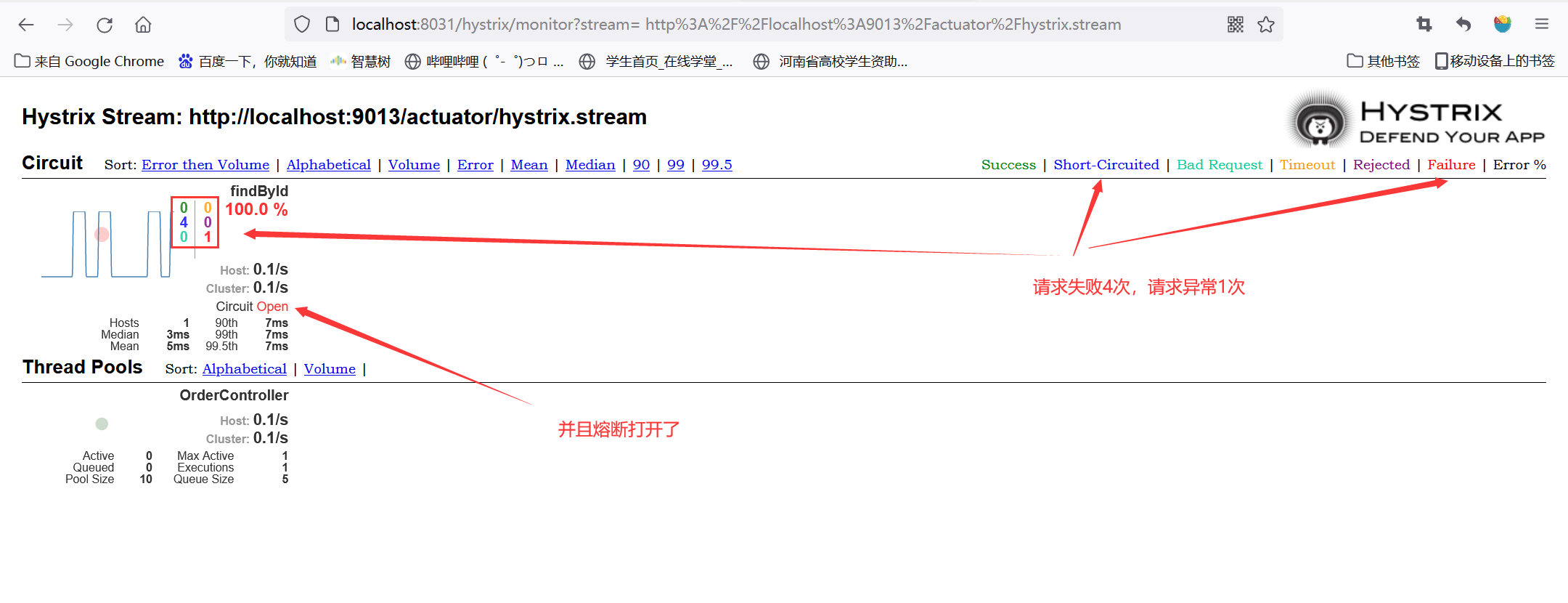
熔断器的默认触发阈值是20次请求,不好触发。休眠时间为5秒,时间太短,不易观察,为了测试方便,我们可以通过配置修改熔断策略:
hystrix:
command:
default:
circuitBreaker:
requestVolumeThreshold: 5 #触发熔断的最小请求次数,默认20
sleepWindowInMilliseconds: 10000 #熔断多少秒后,重新恢复正常请求
errorThresholdPercentage: 50 #触发熔断的失败请求最小占比,默认50%(10次中有5次失败即触发)
解读:
- requestVolumeThreshold :触发熔断的最小请求次数,默认20次
- sleepWindowInMilliseconds :当我们疯狂访问id为11111的请求时(超过5次),就会触发熔断,熔断10秒后去尝试请求,
- errorThresholdPercentage :触发熔断的失败请求最小占比,默认50%
*(1)测试失败的请求http://localhost:9013/order/buy/11111,请求5次
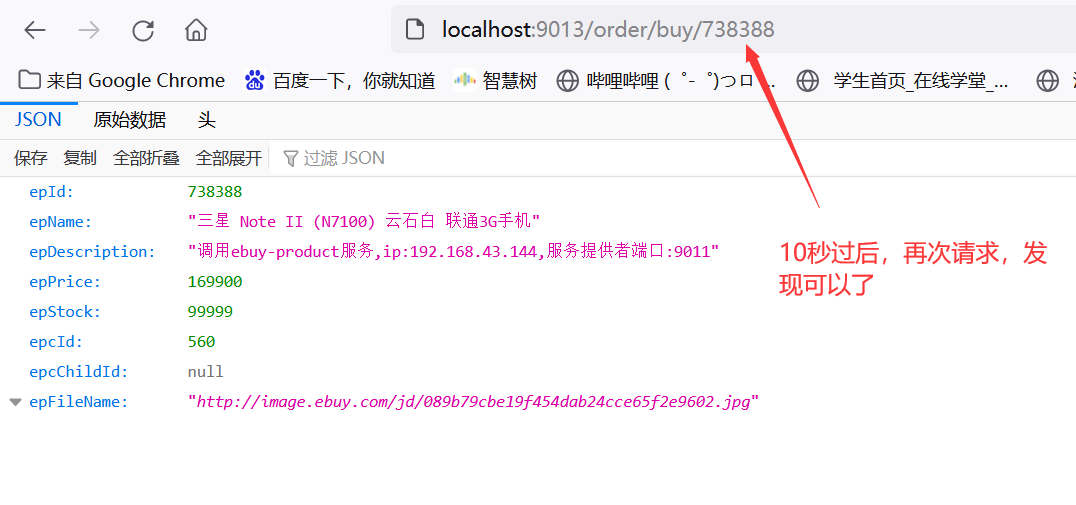
当发生熔断后,此时你访问id为738388(正确的id)的请求,会发现返回的也是失败,因为此时处于熔断状态,由于配置为10秒,所以10秒会重新回复为正常的请求,这个时候访问id为738388,发现可以访问请求成功

7.9、熔断器的隔离策略
微服务使用Hystrix熔断器实现了服务的自动降级,让微服务具备自我保护的能力,提升了系统的稳定性,也较好的解决雪崩效应。其使用方式目前支持两种策略:
- 线程池隔离策略: 使用一个线程池来存储当前的请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求堆积入线程池队列。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)
- 信号量隔离策略: 使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃改类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)
线程池和信号量两种策略功能支持对比如下:
| 功能 | 线程池隔离 | 信号量隔离 |
|---|---|---|
| 线程 | 与调用线程非相同线程 | 与调用线程相同(jetty线程) |
| 开销 | 排队、调度、上下文开销等 | 无线程切换、开销低 |
| 异步 | 支持 | 不支持 |
| 并发支持 | 支持(最大线程池大小) | 支持(最大信号量上限) |
- 配置隔离策略: hystrix.command.default.execution.isolation.strategy :
- 信号量隔离: ExecutionIsolationStrategy.SEMAPHORE
- 线程池隔离: ExecutionIsolationStrategy.THREAD
- 最大信号量上限: hystrix.command.default.execution.isolation.maxConcurrentRequests :
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/189420.html

