
💕成功不是将来才有的,而是从决定去做的那一刻起,持续积累而成。💕
🐼作者:不能再留遗憾了🐼
🎆专栏:Java学习🎆
🚗本文章主要内容:深入理解KMP算法

文章目录
什么是KMP算法
KMP算法,即Knuth-Morris-Pratt算法,是一种字符串匹配算法。其在目标串与模式串匹配过程中,避免了重复比较已经匹配过的字符的情况,提高了匹配效率。因此,KMP算法是解决字符串匹配问题的一个经典算法。
KMP算法的时间复杂度是O(m+n),其中m是模式串的长度,n是目标串的长度。这意味着,KMP算法的效率比暴力匹配算法快得多,特别是在目标串较长,模式串较短的情况下。
KMP算法的核心是构造模式串的部分匹配表(Partial Match Table,PMT),也称为部分匹配值(Partial Match Value,PMV)。PMT中每个位置i所对应的值,表示模式串从开头到i这个子串中,最长的既是前缀又是后缀的字符串的长度。构建PMT的时间复杂度为O(m),其中m是模式串的长度。
有了PMT之后,在匹配目标串和模式串的过程中,如果在匹配某个字符时发现不匹配,就可以利用PMT将模式串向右移动一定的距离,从而避免重复比较已经匹配过的字符的情况。这样可以大大提高匹配效率。
为什么会有KMP算法
我们先来看一个例子:我们想在主串S = “abcdefgabcdex”这个字符串中找到T = “abcdex”出现的位置该怎么办?
一般来说我们会用 i 来遍历主串S,用 j 来遍历字符串T,i 和 j 都从0下标开始,如果 i 所在的字符等于 j 所在的字符,那么 i 和 j 就都向后走一个字符,继续比较 i 和 j 所在的字符,如果不相等那么 i 就回到 1 下标处,j 回到 0 下标处,然后继续比较。
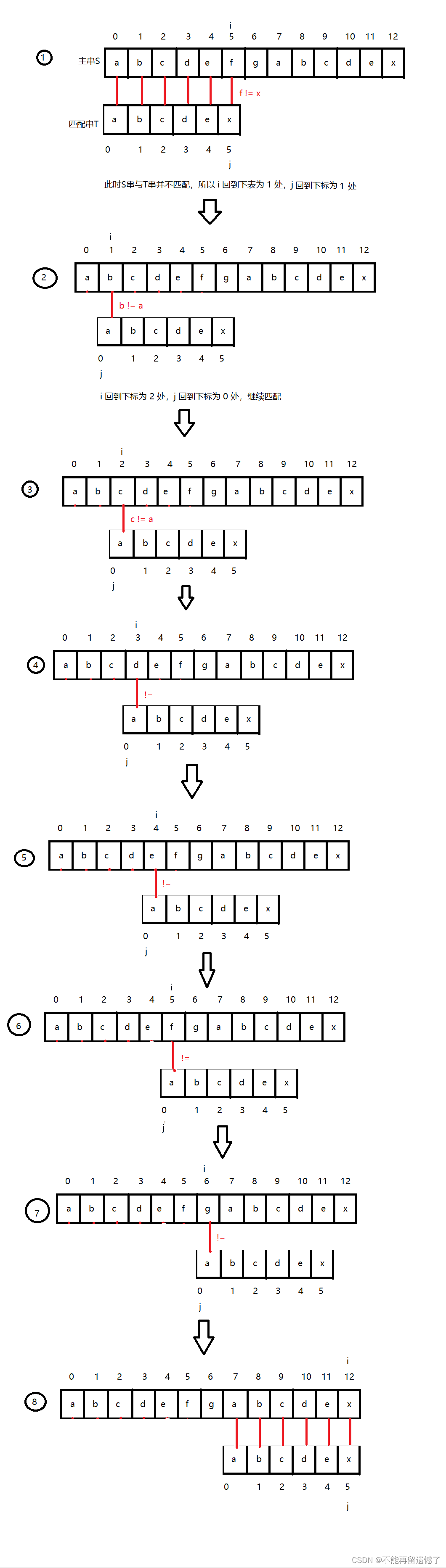
按照常规的暴力匹配算法,需要以上的1,2,3,4,5,6,7,8这几个步骤,但是我们可以发现子串的首字母“a”与后面的“bcedx”的每一个字符都不相等,并且主串S的前五个字符与子串T的前五个字符都匹配,也就是说子串T的首字母“a“不会与主串S的第2-5位的字符匹配。所以我们就可以跳过2-5的步骤,但是第6步不能跳,因为你不能知道S[5]!= T[0]。而这些是理解KMP算法的关键。
KMP算法实现
我们再来看一个例子,上面是子串”a“后面没有相同的”a“字符,那么如果子串首字母”a“后面还有”a“字符呢?
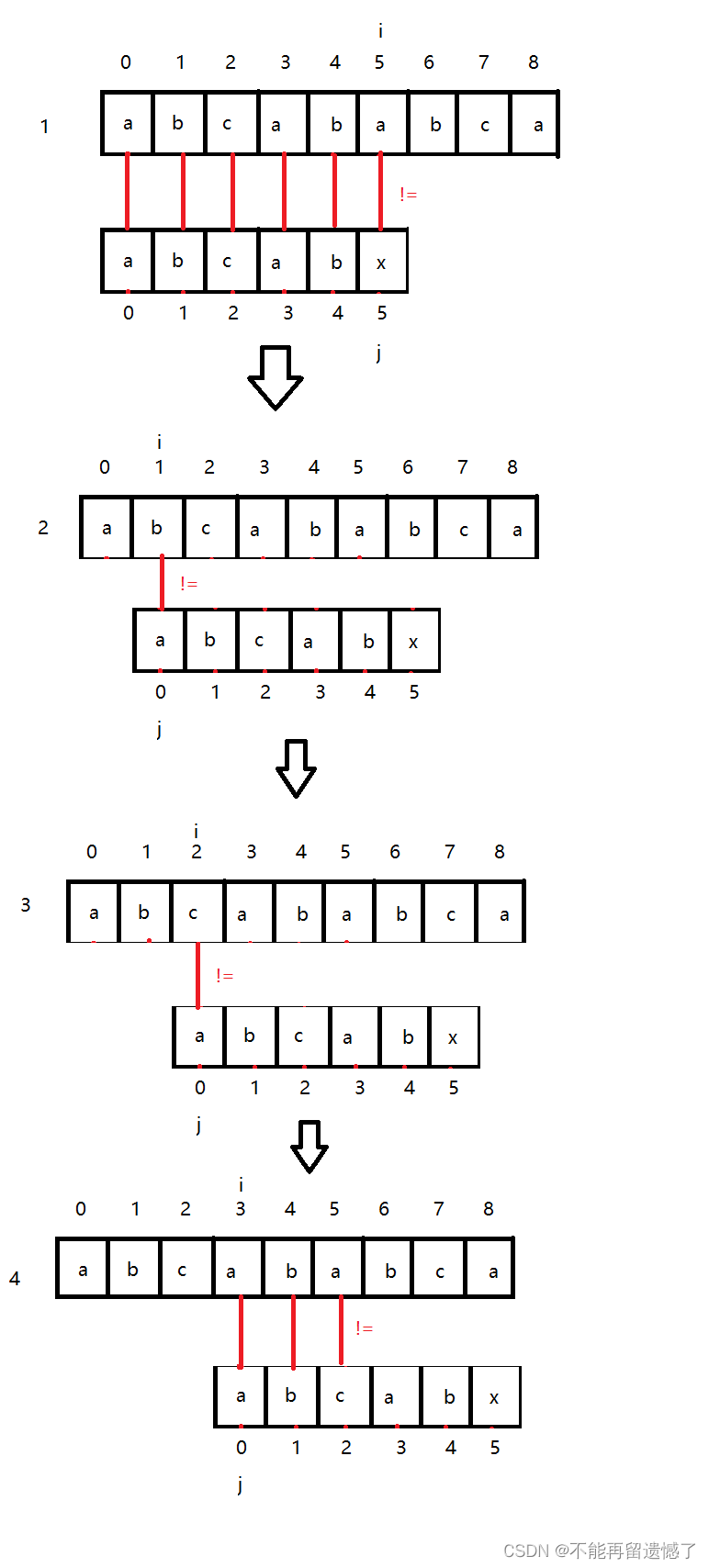
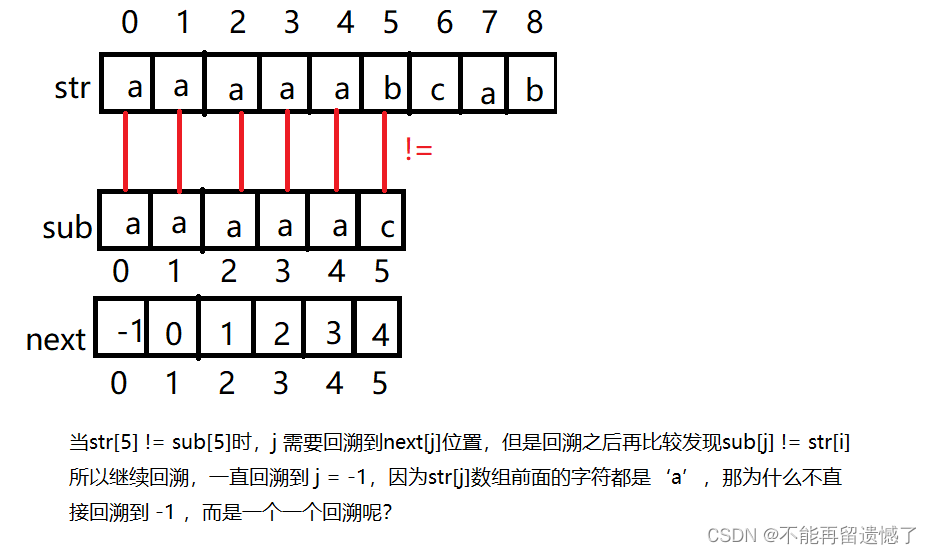
我们用暴力匹配法可以发现,这里我们看到当 i 和 j 都从 0 开始遍历时,前五个字符能够匹配,第六个不能匹配,所以我们就将 i 回到下标为1 处,j 回到下标为 0 处,但是我们观察子串可以发现下标为 0 到 2之间没有重复的字符,并且主串和子串0到4之间的字符是匹配的,所以”a“不会跟主串 1 和 2这两个字符相同,我们就可以省略这些步骤,不仅如此,最后一个步骤的”a“和”b“也是不需要比较的,因为子串T下标为 0 和下标为 3的字符是相同的,下标为 1 处的字符和下表为 4 的字符是相同的,T[0] = T[3],T[1] =T[4],主串和子串0到4之间的字符是匹配的,S[3] = T[3],S[4] = T[4],从而得出T[0] = S[3],T[1] =S[4],所以这两个字符也是不需要比较的。所以我们的步骤可以省略为这样。
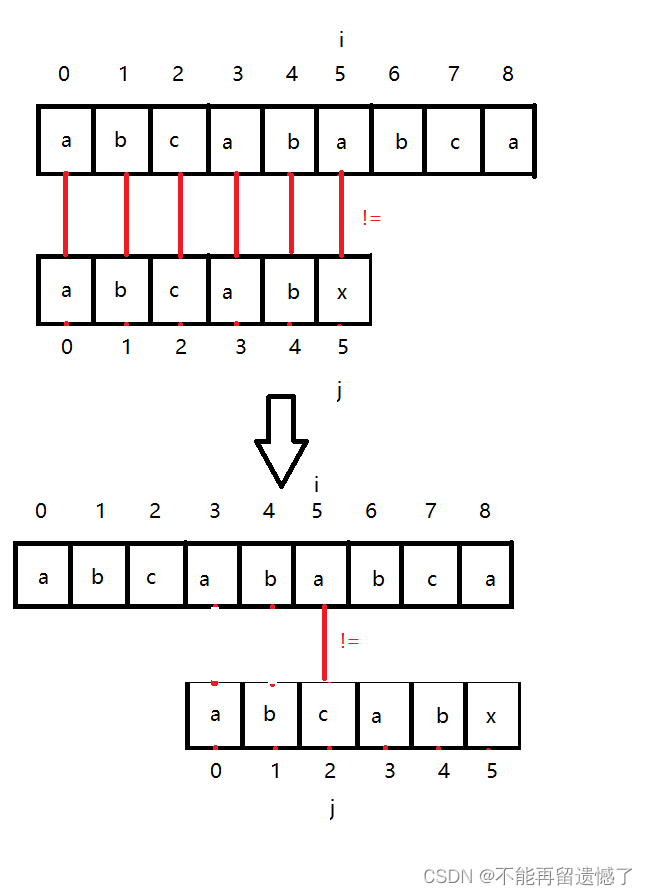
当我们省略这些步骤后我们可以发现,主串的 i 是没有回溯的,而只有子串的 j 在回溯,并且 j 并不是每次都回溯到 0 下标处,而是回溯到子串的具有相同最长的前缀和后缀的下一位置。
根据上面的两个例子我们可以知道KMP算法的关键就是遍历主串的 i 不回溯,而是 遍历子串的 j 回溯到特定的位置,这个特定的位置取决于该位置之前的最长相同前后缀,跟主串并没有关系。
那么我们怎样知道 j 回溯到哪里呢?为了解决这个问题我们可以定义一个next数组来存放对应位置 j 的回溯位置。
部分匹配表的构建
部分匹配表的生成方法如下:
next的第0个元素是-1或者0,我们以-1为例。
从第1个字符开始,依次计算以该元素为结尾的子串的“最长相等前后缀”的长度,即该子串的前缀中有多少个字符与该子串的后缀中的字符相匹配。
以P=”ababc”为例,next的第i个元素表示P的前缀子串(0,i)中,最长的既是前缀又是后缀的子串长度。具体而言:
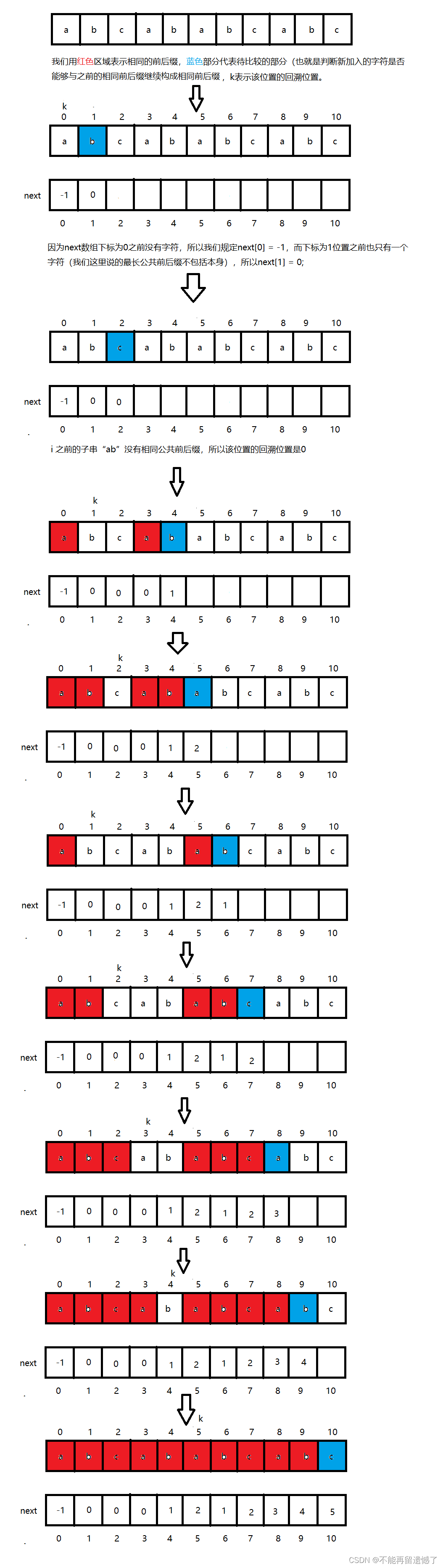
next[0] = -1 ; 它是从字符串0到字符串0之间的最长相同前后缀。
next[1] = 0 ; 它是从字符串0到字符串1之间的最长相同前后缀是空字符串。
next[2] = 0 ; 它是从字符串0到字符串2之间的最长相同前后缀是空字符串。
next[3] = 0 ; 它是从字符串0到字符串3之间的最长相同前后缀是空字符串。
next[4] = 1 ; 它是从字符串0到字符串4之间的最长相同前后缀为”a”。
next[5] = 2;它是从字符串0到字符串5之间的最长相同前后缀为“ab”。
next[6] = 1;它是从字符串0到字符串6之间的最长相同前后缀为“a”。
next[7] = 2;它是从字符串0到字符串7之间的最长相同前后缀为“ab”。
next[8] = 3;它是从字符串0到字符串8之间的最长相同前后缀为“abc”。
next[9] = 4;它是从字符串0到字符串9之间的最长相同前后缀为“abca”。
next[10] = 5;它是从字符串0到字符串10之间的最长相同前后缀为“abcab”。
以上这些是我们用眼睛看出来的相同的前后缀,那么如果以代码的思想该怎么写呢?
我们定义一个k,使得k所在的位置之前的字符是与 i 之前的相同个数的字符是相同的,也就是相同的前缀和后缀,k 是子串对应位置的回溯位置,比较 i-1 所在的字符是否是与 k 所在的字符相等,如果相等,就说明相同前后缀的长度增加了,那么该位置的next[i]就等于++k,如果不相等,那么就需要在 i 之前的位置重新找相同前后缀,因为 k 之前的子串就是相同前后缀的前缀,所以就让k回溯到next[k]的位置,直到 k 所在位置等于 i-1所在位置的字符,如果最终 k = -1,那就说明主串的第一个字符和子串的第一个字符都不相等,所以我们的 i 下标处的回溯位置就等于++k= 0 。
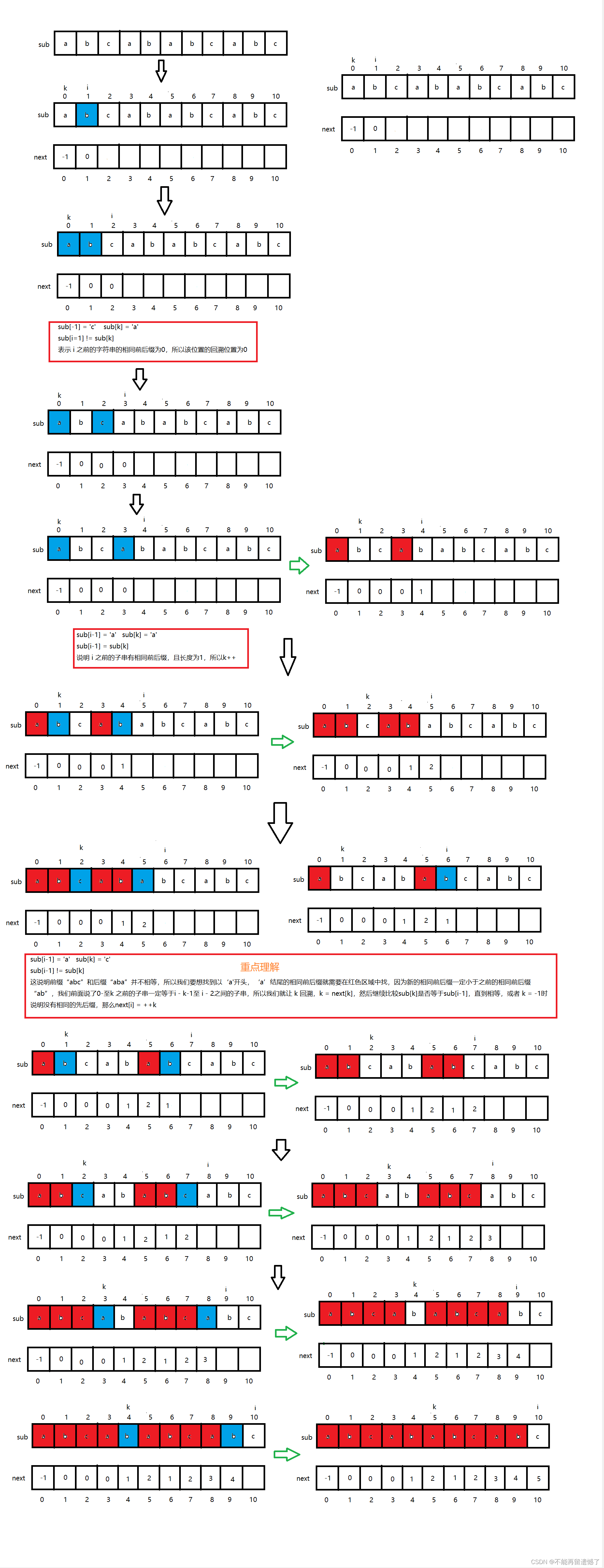
俗话说:磨刀不误砍柴工,我们在进行字符串匹配之前,先对要匹配的字符串做出分析,创建一个next数组,这样可以大大减少我们查找的难度和提高查找的速度。
C语言实现KMP算法
#include<stdio.h>
#include<assert.h>
#include<string.h>
#include<stdlib.h>
void getNext(char sub[], int next[], int lenSub)
{
next[0] = -1;
next[1] = 0;
int i = 2;
//k所指的数组下标位置之前的字符与i-1之前相同数量的字符是相等的,
//也就是相等前后缀
int k = 0;
while (i < lenSub)
{
if (k == -1 || sub[i - 1] == sub[k])
{
next[i] = k + 1;
i++;
k++;
}
else
{
k = next[k];
}
}
}
int KMP(char str[], char sub[],int pos)
{
//判断数组和坐标的合法性
assert(str != NULL && sub != NULL);
int lenStr = strlen(str);
int lenSub = strlen(sub);
if (lenStr == 0 || lenSub == 0) return -1;
if (pos < 0 || pos >= lenStr) return -1;
int i = pos;
int j = 0;
int* next = (int*)malloc(sizeof(int) * lenSub);
getNext(sub, next,lenSub);
while (i < lenStr && j < lenSub)
{
if (j == -1 || str[i] == sub[j])
{
i++;
j++;
}
else
{
j = next[j];
}
}
if (j >= lenSub) return i - j;
return -1;
}
int main()
{
printf("%d", KMP("abababcabd", "abd",0));
return 0;
}
Java实现KMP算法
public class Test {
public static int KMP(String str,String sub,int pos) {
if(str == null || sub == null) return -1;
int lenStr = str.length();
int lenSub = sub.length();
if(lenStr == 0 || lenSub == 0) return -1;
if(pos < 0 || pos >= lenStr) return -1;
int[] next = new int[lenSub];
getNext(sub,next);
int i = pos;
int j = 0;
while(i < lenStr && j < lenSub) {
if(j == -1 || str.charAt(i) == sub.charAt(j)) {
i++;
j++;
}else {
j = next[j];
}
}
if(j >= lenSub) {
return i - j;
}
return -1;
}
private static void getNext(String sub, int[] next) {
next[0] = -1;
next[1] = 0;
int k = 0;
int i = 2;
while(i < sub.length()){
if(k == -1 || sub.charAt(i-1) == sub.charAt(k)) {
next[i] = k + 1;
i++;
k++;
}else {
k = next[k];
}
}
}
}
KMP算法优化
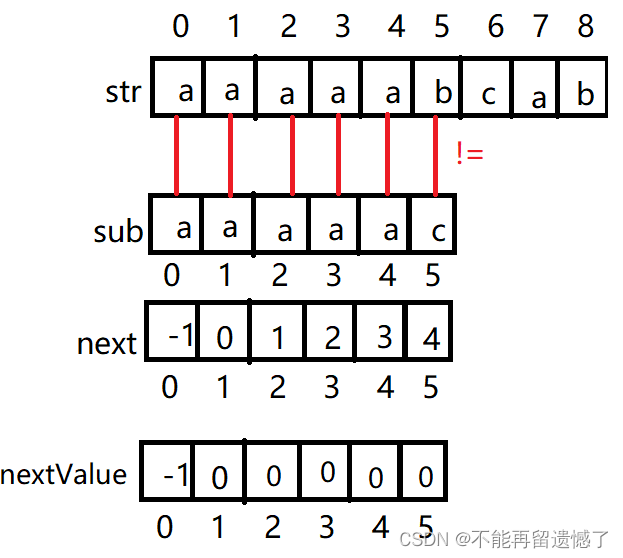
上面的KMP算法速度已经提升很多了,但是还可以再快一点,我们看看为什么上面的代码还可以优化呢?
所以我们继续定义一个nextValue数组,如果sub[i-1] =sub[nextValue[i-1]],那么sub[i-1]一定不会等于sub[k],所以我们直接将nextValue[i] =nextValue[nextValue[i-1]]。
C语言优化KMP算法
#include<stdio.h>
#include<assert.h>
#include<string.h>
#include<stdlib.h>
void getNextValue(char sub[], int nextValue[], int lenSub)
{
nextValue[0] = -1;
nextValue[1] = 0;
int i = 2;
//k所指的数组下标位置之前的字符与i之前相同数量的字符是相等的,也就是相等前后缀
int k = 0;
while (i < lenSub)
{
if (k == -1 || sub[i - 1] == sub[k])
{
if (sub[i - 1] == sub[nextValue[i - 1]])
{
next[i] = nextValuw[nextValue[i - 1]];
}
else
{
nextValue[i] = k + 1;
}
i++;
k++;
}
else
{
k = nextValue[k];
}
}
}
int KMP(char str[], char sub[],int pos)
{
assert(str != NULL && sub != NULL);
int lenStr = strlen(str);
int lenSub = strlen(sub);
if (lenStr == 0 || lenSub == 0) return -1;
if (pos < 0 || pos >= lenStr) return -1;
int i = pos;
int j = 0;
int* nextValue = (int*)malloc(sizeof(int) * lenSub);
getNextValue(sub, nextValue,lenSub);
while (i < lenStr && j < lenSub)
{
if (j == -1 || str[i] == sub[j])
{
i++;
j++;
}
else
{
j = nextValue[j];
}
}
if (j >= lenSub) return i - j;
return -1;
}
Java代码优化KMP算法
public class Test {
public static int KMP(String str,String sub,int pos) {
if(str == null || sub == null) return -1;
int lenStr = str.length();
int lenSub = sub.length();
if(lenStr == 0 || lenSub == 0) return -1;
if(pos < 0 || pos >= lenStr) return -1;
int[] nextValue= new int[lenSub];
getNext(sub,nextValue);
int i = pos;
int j = 0;
while(i < lenStr && j < lenSub) {
if(j == -1 || str.charAt(i) == sub.charAt(j)) {
i++;
j++;
}else {
j = nextValue[j];
}
}
if(j >= lenSub) {
return i - j;
}
return -1;
}
private static void getNext(String sub, int[] nextValue) {
nextValue[0] = -1;
nextValue[1] = 0;
int k = 0;
int i = 2;
while(i < sub.length()){
if(k == -1 || sub.charAt(i-1) == sub.charAt(k)) {
if(sub.charAt(i-1) == sub.charAt(nextValue[i-1])) {
nextValue[i] = nextValue[nextValue[i-1]];
}else {
nextValue[i] = k + 1;
}
i++;
k++;
}else {
k = nextValue[k];
}
}
}
}
总结
KMP算法是一种高效的字符串匹配算法,可以在线性的时间内解决字符串匹配问题,而使用KMP算法的关键在于自己手写代码生成一个next或者nextValue数组,一旦写出来了这个数组,那么代码的速度将会大大提升,相信大家如果掌握了的话,一定会爱上他的。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/192638.html

