
朴素贝叶斯是 一种经典的分类算法
贝叶斯定理
条件概率:记事件A发生的概率为P(A),事件B发生的概率为P(B),则在B事件发生的前提下,A事件发生的概率即为条件概率,记为P(A|B)。
P(A|B)=P(AB)/P(B) 由此可以得P(AB)=P(A|B)*P(B)
即同理 P(AB)=P(B|A)*P(A)
即P(A|B)=P(B|A)*P(A)/P(B)
全概率公式:表示若事件 构成一个完备事件组且都有正概率,则对任意一个事件B都有公式成立:
构成一个完备事件组且都有正概率,则对任意一个事件B都有公式成立:
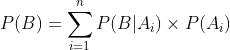
将全概率公式带入贝叶斯公式中,得到
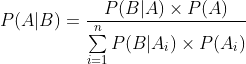
P(A)称为先验概率,即在B事件发生前,对A事件概念的一个判断
P(A|B)称为后验概率,即在B事件发生之后,对于A事件的重新评估。
样例
下面是 随便列举的一堆数据
| 品德 | 性格 | 成绩 | 是否可以被评选为优秀学生 |
| 好 | 好 | 优 | 是 |
| 不好 | 好 | 良 | 不是 |
| 不好 | 不好 | 差 | 不是 |
| 好 | 好 | 良 | 是 |
| 不好 | 好 | 优 | 是 |
| 好 | 不好 | 良 | 不是 |
| 好 | 好 | 差 | 是 |
| 不好 | 不好 | 优 | 不是 |
| 好 | 不好 | 优 | 是 |
| 不好 | 好 | 差 | 不是 |
贝叶斯公式为
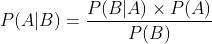
根据贝叶斯公式转化为分类任务的表达式为
P(类别|特征)=P(类别)* P(特征|类别)/ P(特征), 然后计算P(是 |品德好 性格不好 成绩差)和 P(不是 |品德好 性格不好 成绩差),选择是或不是。
解决步骤如下:

朴素贝叶斯对文本进行分类的python代码
import numpy as np
from functools import reduce
#创建一个实验样本
def loadDataSet():
dataSet= [['my','dog','has','flea','problems','help','please'],
['maybe','not','take','him','to','dog','park','stupid'],
['my','dalmation','is','so','cute','I','love','him'],
['stop','posting','stupid','worthless','garbage'],
['mr','licks','ate','my','steak','how','to','stop','him'],
['quit','buying','worthless','dog','food','stupid']]
classVec = [0,1,0,1,0,1]
return dataSet,classVec
# 创建一个包含在所有文档中出现的不重复词的词表
def createbvocabList(dataSet):
vocabSet=set([])# 创建一个空集
for doc in dataSet:
vocabSet=vocabSet|set(doc)# 创建两个集合的并集
vocabList=list(vocabSet)
return vocabList
# 将文档词条转换成词向量
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)#创建一个其中所含元素都为0的向量
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print ("the word: %s is not in my Vocabulary!" % word)
return returnVec
#把实验数据中的每条文本转化为词向量
def get_trainMat(dataSet):
trainMat=[]
vocabList=createbvocabList(dataSet)
for inputSet in dataSet:
returnVec=setOfWords2Vec(vocabList,inputSet)
trainMat.append(returnVec)
return trainMat
# 朴素贝叶斯分类器训练函数 从词向量计算概率
def trainNB(trainMat,classVec):
n=len(trainMat)#文档数目
m=len(trainMat[0])#文档的词条数
pAb=sum(classVec)/n#文档属于侮辱类的
p0Num=np.ones(m)
p1Num=np.ones(m)
p0Denom=2
p1Denom=2
for i in range(n):
if classVec[i]==1:
p1Num+=trainMat[i]
p1Denom+=sum(trainMat[i])
else:
p0Num+=trainMat[i]
p0Denom+=sum(trainMat[i])
p1V=np.log(p1Num/p1Denom)#拉普拉斯平滑,为了解决零概念事件
p0V=np.log(p0Num/p0Denom)
return p0V,p1V,pAb
def classifyNB(vec2Classify,p0V,p1V,pAb):
p1=sum(vec2Classify*p1V)+np.log(pAb)
p0=sum(vec2Classify*p0V)+np.log(1-pAb)
print("p0",p0)
print("p1",p1)
if p1>p0:
return 1
else:
return 0
def testingNB(testVec):
dataset,classVec=loadDataSet()
vocabList=createbvocabList(dataset)
trainMat=get_trainMat(dataset)
p0V,p1V,pAb=trainNB(trainMat,classVec)
thisone=setOfWords2Vec(vocabList,testVec)
if classifyNB(thisone,p0V,p1V,pAb)==1:
print("属于侮辱类")
else:
print("属于非侮辱类")
testVec=["stupid","garbage"]
print(testingNB(testVec))
testVec1=["love","my"]
print(testingNB(testVec1))版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/197061.html

