
普通索引和唯一索引
问题
- 在不同的业务场景下,应该选择普通索引,还是唯一索引?
几个注意点
- 数据页内部通过二分法来定位记录
- 面对比较大的类似于身份证号的字段,每一条都是唯一的记录(一般使用唯一索引)
- 查看表T上面的索引的sql语句
mysql> show index from T;
普通索引和唯一索引的读区别
select id from T where k = 5;
-
普通索引(不只是查一条记录)- 查找到满足条件的第一个记录(k=5)时,需要查找下一条记录,直到碰到第一个不满足k=5的记录
-
唯一索引(只查一条记录)- 由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止检索
但是,这个不同带来的影响微乎其微!!!
原因:
- innoDB的数据是按数据页为单位来读写的,也就是说,当需要读一条记录时,并不是将这个记录本身(也就是这一条记录)从磁盘读出来,而是把页作为整个单位将其整体读入内存,在InnoDB中,每个数据页的大小默认是16Kb
普通索引和唯一索引更新区别
change buffer
是什么:
- 当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果数据页还没有在内存中的话,在不影响数据一致性的前提下,InnoDB会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中读入这个数据页了,在下次查询需要访问这个数据页时,将数据页读入内存,然后执行change buffer中与这个页有关的操作
change buffer的存储方式:
- 虽然名字加change buffer,实际上他是可以持久化的数据,也就是说,change buffer在内存中有拷贝,也会被写入到磁盘上
== 有关change buffer的merge操作:==
- 将change buffer中的操作应用到原数据页,得到最新的结果的过程称为merge,除了访问这个数据库会触发merge外,系统有后台线程会定期merge,在数据库正常关闭的过程中,也会发生merge操作
使用change buffer的条件
- 对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反唯一性约束,因此每次要插入一条新的记录(k=4),就必须要判断现在表中有没有这条记录(k=4),这就必须把k= 4这条记录读进内存,如果都已经直接读到内存了,那直接更新内存会更快,没必要使用change buffer
- 所以只有普通索引才能用change buffer
change buffer的参数设置
设置change buffer大小为buffer pool的50/100
mysql> show variables like '%innodb_change_buffer_max_size%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| innodb_change_buffer_max_size | 25 |
+-------------------------------+-------+
change buffer的使用场景
问题:
- 普通索引的所有场景,使用change buffer都可以起到加速作用吗?
解答:
-
因为merge的时候是真正进行数据更新的时刻,而change buffer的主要目的就是把要记录的变更动作缓存下来,所以在一个数据页做merge之前,change buffer记录的操作变更越多,收益就越大
-
对于写多读少的业务来说,页面在写完之后马上被访问的概率小,此时change buffer的效果最好
反过来: -
如果是写少读多,那么由于读的次数多,经常会把数据读入内存,助力的效果就不大
索引选择与实践
因此得出结论:
普通索引和唯一索引在查询能力上没啥大差别,主要考虑对更新性能的影响,应该尽量选择使用普通索引,因为普通索引会使用change buffer
change buffer和redo log
- 在表中插入数据
mysql> insert into T(id,k) values(id1,k1),(id2,k2);
- 假设当前索引树中k1所在的数据页在内存中,K2的数据页不在内存中
- 就会执行下面的更新图
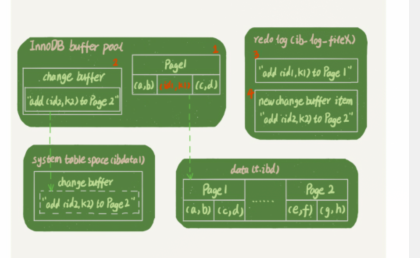

这条更新语句做了如下的操作(插入时):
- Page1在内存中,直接更新内存
- page2没有在内存中,就在内存的change buffer区域,记录下“我要往Page2插入一行”我要往Page2插入一行”
- 将上述两个动作记入Redo log中(把1和2步骤的操作记入RedoLog中)
当执行select * from T where k = k2时(查找时):
- 要读Page2的时候(同时要执行RedoLog),需要把Page2从磁盘读入到内存中,然后应用change buffer里面的操作日志,生成一个正确的版本并返回结果
结论
redoLog主要节省的是随机写磁盘的IO消耗(转成顺序写),而change buffer主要节省的是随机读磁盘的IO消耗
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/202552.html

